
決定木とは?仕組み・ジニ不純度・剪定までやさしく解説【機械学習入門】
ルミィ
AIの歩き方

「三人寄れば文殊の知恵」——1人では平凡でも、みんなで意見を出し合えば、ぐっと賢い答えにたどり着く。これをそのまま機械学習にしたのが、連載最終回のアンサンブル学習です。
じつは、当サイトで紹介してきたランダムフォレストやXGBoost、LightGBMといった“強い”手法は、すべてこのアンサンブル学習の仲間です。その背骨にある考え方を知れば、これらの手法がなぜ強いのかが腑に落ちます。
この連載は、機械学習の3つの学び方でいう「教師あり学習(分類)」の手法をあつかいます。決定木やロジスティック回帰を読んでいると、より分かりやすいです。
📘 連載「機械学習アルゴリズム図鑑」(手法編・全4回)
線形回帰や決定木に続く“定番の分類アルゴリズム”を、1つずつ図でやさしく整理する連載です。

弱い学習器を1つ作るより、たくさん作って“多数決”したほうが強い。Kaggleの上位常連も、この考え方だよ。
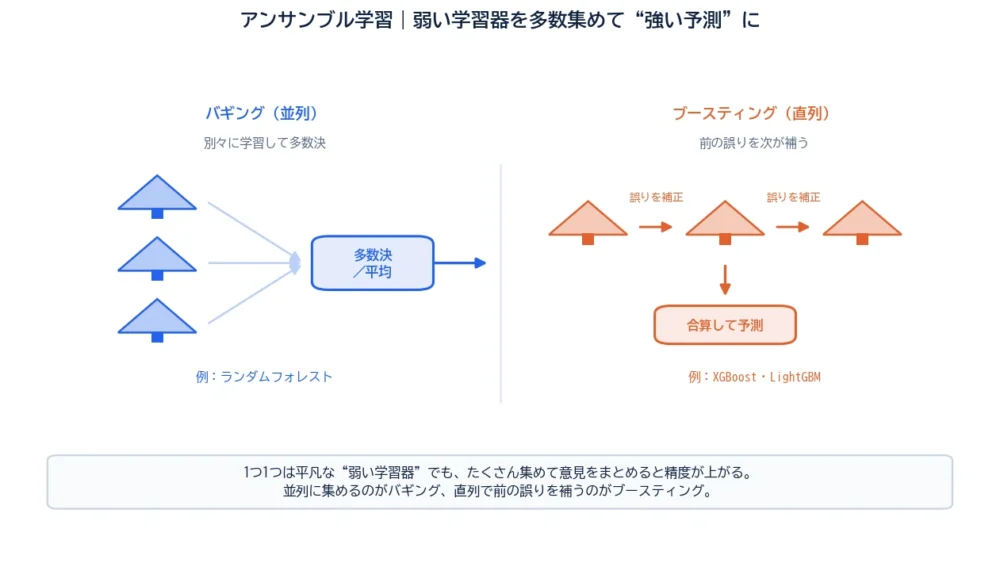
アンサンブル学習は、たくさんの“弱い学習器”を組み合わせて、1つの“強い予測”を作る手法です。「アンサンブル」は、もともと音楽で“合奏”を意味する言葉。1つ1つの楽器(モデル)が完璧でなくても、合わせれば豊かな音になる、というイメージです。
ここでいう「弱い学習器」とは、単体ではそこそこの精度しかないモデルのこと。たとえば浅い決定木1本などです。これを何十・何百と作って意見を集約すると、不思議と1本のときよりずっと高い精度が出る——これがアンサンブルの魔法です。
ポイントは、それぞれの学習器が“違う間違い方”をすることです。
1本のモデルには、どうしても得意・不得意のクセ(間違い)があります。でも、少しずつ違うモデルをたくさん用意すると、あるモデルの間違いを、別のモデルが正してくれる。多数決をとれば、てんでばらばらな間違いは打ち消し合い、みんなが共通して正しい部分だけが残ります。
クイズ番組で、1人の回答より“観客全員の多数決”のほうが正答率が高い、という現象に似ています。「みんなの知恵」は、たいてい個人より賢いのです。
1つ1つは平凡な“弱い学習器”でも、たくさん集めて意見をまとめると、間違いが打ち消し合って精度が上がる。これがアンサンブルの核心。
アンサンブルの代表的なやり方が2つあります。1つ目がバギングです。図の左側のように、複数の学習器を“別々に・並列に”作り、その多数決(や平均)をとる方法です。
各学習器には、元データから少しずつ違うデータを抜き出して渡します。すると、少しずつ性格の違うモデルがたくさんでき、それを多数決でまとめます。
この代表がランダムフォレスト。たくさんの決定木を別々に育てて多数決する、まさにバギングの王道です。各木が勝手に育つので並列に計算でき、過学習も抑えやすいのが長所です。
2つ目がブースティングです。図の右側のように、学習器を“一列に・順番に”作り、前の学習器が間違えたところを、次の学習器が重点的に補う方法です。
1つ目のモデルが苦手だった部分に注目し、2つ目はそこを頑張る。さらにその誤りを3つ目が……と、バトンをつなぐようにだんだん賢くしていくイメージです。最後に全員の予測を合算します。
この代表がXGBoostやLightGBM。表形式データのコンペ(Kaggleなど)で上位を席巻してきた“最強クラス”の手法群で、その正体はこのブースティングです。
2つの違いを、表で整理しておきましょう。
| バギング | ブースティング | |
|---|---|---|
| 作り方 | 並列(別々に独立して) | 直列(順番に) |
| 集め方 | 多数決・平均 | 前の誤りを補正して合算 |
| 主な狙い | ばらつき(過学習)を抑える | 精度を高く押し上げる |
| 代表 | ランダムフォレスト | XGBoost・LightGBM |
ざっくり、「安定重視ならバギング、精度を限界まで攻めるならブースティング」。ブースティングは強力な反面、やりすぎると過学習しやすいので、チューニングが効いてきます。
3つ目のやり方としてスタッキングも知っておくと通です。これは、種類の違うモデル(決定木・SVM・kNNなど)の予測を、さらに別のモデルに“まとめ役”として学習させる方法です。
「いろんな専門家の意見を、まとめ役がもう一段で判断する」二段構えのイメージ。手間はかかりますが、コンペで最後の精度を絞り出すときによく使われます。
ここまで読むと気づくはずです。当サイトで「強い手法」として紹介してきたランダムフォレスト(バギング)、XGBoost・LightGBM(ブースティング)は、すべてアンサンブル学習だったのです。
つまり、いまの表形式データ分析の主役は、ほぼアンサンブルが占めていると言ってよいほど。「1つの賢いモデルを作る」より「平凡なモデルをたくさん束ねる」ほうが強い——この発想の転換こそ、現代機械学習の大事なカギなのです。
アンサンブルがうまくいくための条件は、集めるモデルが“似すぎていない”ことです。全員が同じ間違いをするなら、何人集めても同じ間違いをするだけ。多数決の意味がありません。
だからバギングでは、わざと少しずつ違うデータや特徴量を各モデルに渡して、“間違い方の個性”を作り出します。ランダムフォレストが、各木にランダムなデータと特徴量を割り当てるのは、この多様性を生むためです。「みんな違って、みんなそこそこ」——これがアンサンブルの理想です。
強力なアンサンブルにも、知っておきたいコストがあります。
特に「結果の理由を説明したい」場面では、精度の高いアンサンブルより、シンプルな決定木やロジスティック回帰のほうが向くこともあります。精度と説明しやすさは、しばしばトレードオフになります。
データ分析コンペ(Kaggleなど)の上位は、長年アンサンブルが席巻してきました。理由はシンプルで、ほんの少しの精度差が勝負を分ける世界だからです。
1つのモデルで限界まで精度を上げたら、次は「少し違うモデルを足して、間違いを埋め合う」。この積み重ねが、最後の小数点以下を絞り出します。実務では「速さ・説明しやすさ」とのバランスも大事ですが、「精度がすべて」の場面でアンサンブルが最強と言われるのは、こうした理由からです。
アンサンブルの説明によく出てくる「弱い学習器」という言葉。これは「当てずっぽうよりは少しマシ」くらいの、そこそこの予測しかできないモデルを指します。たとえば、枝分かれが2〜3回しかない浅い決定木などです。
1本だけでは頼りない弱い学習器も、たくさん集めて意見をまとめると、驚くほど強くなる。「弱さ」は欠点ではなく、むしろ多様性を生む材料——ここがアンサンブルの面白いところです。完璧な一人の天才より、それぞれ少しずつ違う得意を持つ大勢のほうが、チームとしては強い。人間社会にも通じる教訓かもしれません。
アンサンブル学習は、たくさんの弱い学習器を組み合わせ、多数決などで1つの強い予測にまとめる手法です。並列に集めて多数決するのがバギング(ランダムフォレスト)、直列で前の誤りを補うのがブースティング(XGBoost・LightGBM)。違う間違い方をするモデルを束ねることで、間違いが打ち消し合い、精度が上がります。
これで連載「機械学習アルゴリズム図鑑(手法編)」は完結です。境界をかしこく引くSVM、ご近所を見るkNN、確率で見分けるナイーブベイズ、そして束ねて強くするアンサンブル。決定木やランダムフォレストの“仲間たち”が出そろい、機械学習の道具箱がぐっと充実したはずです。お疲れさまでした。
これで、決定木・ランダムフォレスト・XGBoostと学んできた“木の仲間”の正体——アンサンブルという背骨——が、はっきり見えたはずです。1本の木は弱くても、森にすれば強い。違いを活かして束ねれば、平凡が非凡を超える。この発想は、機械学習の枠を超えて、チームづくりや意思決定にも通じる普遍的な知恵です。手法編で身につけたこの“地図”を手に、次に出会うアルゴリズムも、きっと自分の言葉で位置づけられるはずです。それこそが、アルゴリズムを“暗記”ではなく“理解”するということ。一つひとつの手法の長所と短所が見えてくれば、データと目的に合わせて道具を選べる、本当の意味でのデータ分析が始まります。
アンサンブル=弱い学習器を多数集めて強い予測にする。
バギング=並列・多数決(ランダムフォレスト)/ブースティング=直列・誤り補正(XGBoost)。
今の表データ分析の主役。『1つの賢いモデル』より『平凡を束ねる』が強い。
A. たくさんの“弱い学習器”(単体ではそこそこの精度のモデル)を組み合わせて、多数決などで1つの“強い予測”を作る手法です。違う間違い方をするモデルを束ねることで、間違いが打ち消し合い精度が上がります。
A. 各モデルは少しずつ違う間違い方をするため、あるモデルの誤りを別のモデルが正してくれるからです。多数決をとると、ばらばらな間違いは打ち消し合い、みんなが共通して正しい部分が残ります。
A. 複数の学習器を別々に・並列に作り、その多数決や平均をとる方法です。元データから少しずつ違うデータを渡して性格の違うモデルを作ります。代表はランダムフォレストで、過学習を抑えやすいのが長所です。
A. 学習器を順番に作り、前の学習器が間違えたところを次の学習器が重点的に補う方法です。バトンをつなぐように賢くしていきます。代表はXGBoostやLightGBMで、表形式データで非常に高い精度を出します。
A. バギングは並列に作って多数決し、ばらつき(過学習)を抑えるのが狙いです。ブースティングは直列に作って前の誤りを補正し、精度を高く押し上げるのが狙いです。安定重視ならバギング、精度を攻めるならブースティングです。
A. はい。ランダムフォレストはバギング、XGBoostやLightGBMはブースティングという、いずれもアンサンブル学習です。表形式データ分析で強い手法の多くが、アンサンブルにあたります。
A. 種類の違うモデル(決定木・SVM・kNNなど)の予測を、さらに別のモデルにまとめ役として学習させる二段構えの方法です。手間はかかりますが、コンペで最後の精度を絞り出すときによく使われます。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わります。





