
信頼区間とは?95%信頼区間の正しい意味をやさしく図解
ルミィ
AIの歩き方

前回のk近傍法は「距離」で分類しました。今回のナイーブベイズは、うって変わって「確率」で見分ける分類手法です。迷惑メールフィルタの古典として、長く活躍してきました。
「このメールに“無料”“当選”という言葉が入っている。だからスパムの確率が高い」——こんなふうに、手がかりごとの“それっぽさ”を確率でかけ合わせて判定するのがナイーブベイズです。名前に“ナイーブ(単純)”とつく理由もふくめて、図でやさしく見ていきましょう。
この連載は、機械学習の3つの学び方でいう「教師あり学習(分類)」の手法をあつかいます。決定木やロジスティック回帰を読んでいると、より分かりやすいです。
📘 連載「機械学習アルゴリズム図鑑」(手法編・全4回)
線形回帰や決定木に続く“定番の分類アルゴリズム”を、1つずつ図でやさしく整理する連載です。

『この単語があるならスパムっぽい』を確率でかけ算するだけ。単純だけど、スパム判定では長年の働き者だよ。
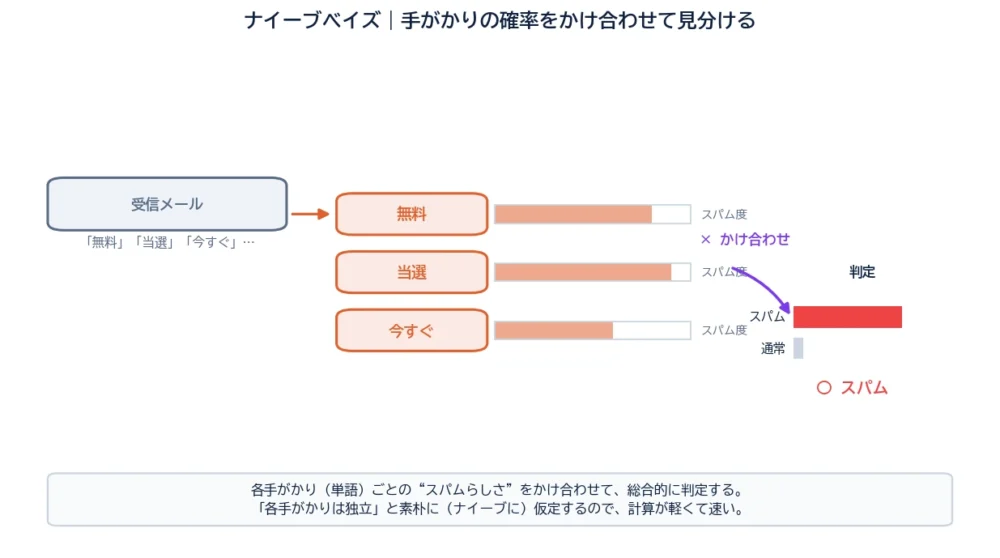
ナイーブベイズは、確率の考え方(ベイズの定理)を使って分類する手法です。データの持つ“手がかり”を見て、「それぞれのクラスである確率」を計算し、いちばん確率の高いクラスに分類します。
代表例が、迷惑メール判定です。メールに含まれる単語を手がかりに、「このメールがスパムである確率」と「通常メールである確率」を計算し、高いほうに振り分けます。図のように、各単語の“スパムらしさ”をかけ合わせていくイメージです。
ナイーブベイズの土台はベイズの定理ですが、難しい数式は要りません。エッセンスはこうです。
「もともとの確率(事前確率)」に、「手がかりから分かること」をかけ合わせて、「結論の確率(事後確率)」を更新する。
たとえば、世の中のメールの3割がスパムだとします(これが“もともとの確率”)。そこに「“当選”という単語が入っている」という手がかりが加わると、スパムである確率はぐっと上がります。「最初の見込み」を「手がかり」で更新していく——これがベイズの考え方です。新しい証拠が出るたびに考えを改める、私たちの自然な推論にも近いものです。
ナイーブベイズの「ナイーブ」は、「各手がかりが、おたがいに無関係(独立)だと単純に仮定する」ことからきています。
たとえば「無料」「当選」「今すぐ」という3つの単語があったとき、本当はこれらは一緒に出やすい(関係がある)かもしれません。でもナイーブベイズは、そこを気にせず「それぞれ独立」とみなして、確率をかけ算するだけにします。この“割り切り”が「ナイーブ=単純・お人よし」と呼ばれる理由です。
乱暴に思えますが、不思議なことに、この割り切りでも実用上はよく当たる。計算がとても軽くなるメリットのほうが大きく、実務で重宝されてきました。
具体的に、迷惑メール判定の流れを見てみましょう。
単語を数えて、かけ算するだけ。とてもシンプルなのに、迷惑メールフィルタとして長年活躍してきたのは、この手軽さと速さのおかげです。
ナイーブベイズの得意・不得意を整理します。
| 内容 | |
|---|---|
| 長所① | 計算がとても軽く、高速。大量の文書もすぐ処理できる |
| 長所② | 少ないデータでもそれなりに動く |
| 長所③ | 仕組みが単純で、結果の解釈もしやすい |
| 短所① | 「手がかりは独立」という仮定は、現実には崩れていることが多い |
| 短所② | 学習データに無い単語が来ると確率がゼロになる(対策あり) |
| 短所③ | 微妙な文脈やニュアンスは捉えにくい |
短所はあるものの、「速くて・軽くて・そこそこ当たる」バランスのよさが、ナイーブベイズの魅力です。
ナイーブベイズは、特にテキスト(文章)の分類で力を発揮します。
なお、ナイーブベイズには扱うデータに応じて種類(多項分布・ガウス・ベルヌーイなど)がありますが、「手がかりの確率をかけ合わせる」という核は同じです。
もう少しだけ詳しく見ると、ナイーブベイズは扱うデータの形に応じて使い分けます。名前だけでも知っておくと、解説で出てきても戸惑いません。
どれを選んでも、「手がかりの確率をかけ合わせて、いちばんありえそうなクラスを選ぶ」という芯は変わりません。データが“回数”なのか“有無”なのか“数値”なのかで、確率の測り方だけを取り替える、というイメージです。
ナイーブベイズには、有名な落とし穴があります。学習データに一度も出てこなかった単語が来ると、その確率が「ゼロ」になってしまうことです。
確率はかけ算なので、1つでもゼロが混じると、全体の確率がまるごとゼロになってしまいます。せっかく他の手がかりがスパムを示していても、未知の単語ひとつで判定が台無しに。これは困ります。
そこで使うのがスムージング(平滑化)という工夫です。すべての単語に「最低限ちょっとだけ」の確率を下駄ばきさせることで、ゼロを防ぎます(ラプラススムージングが有名)。地味ですが、ナイーブベイズを実用的にする大事なひと工夫です。
ナイーブベイズが一躍有名になったのが、2000年代初頭の迷惑メール対策でした。それまでは「このアドレスは拒否」「この単語が入っていたら弾く」といった、人が手で作るルールが中心。でも、スパムを送る側は手口を次々と変えるので、いたちごっこでした。
そこに登場したのが、ベイズ流のフィルタです。「ユーザーがスパムだと分類したメールから自動で学び、確率で判定する」ことで、手口の変化に追従できるようになりました。一人ひとりの受信箱に合わせて賢くなる“学習するフィルタ”は画期的で、いまの迷惑メール対策の礎になりました。
登場から年月が経ち、より高精度な手法も増えました。それでもナイーブベイズが現役で使われ続けるのには、はっきりした理由があります。
「最先端ではないけれど、軽くて速くて、そこそこ当たる」。この絶妙なバランスが、ナイーブベイズを“枯れた名脇役”として生かし続けているのです。新しい手法を試す前の比較対象としても、ナイーブベイズはうってつけ。これより複雑な手法を使うなら、「ナイーブベイズよりどれだけ良くなったか」を物差しにできるからです。
ナイーブベイズは、ベイズの定理を使い、手がかりごとの確率をかけ合わせてクラスを見分ける分類手法です。「各手がかりは独立」と単純に割り切る(ナイーブな)ことで計算が軽くなり、迷惑メール判定をはじめとするテキスト分類で長く活躍してきました。
独立の仮定は現実には崩れがちですが、それでも実用上はよく当たり、何より速い。「単純さは正義」を体現したような手法です。次回は連載の最終回、複数の手法を束ねて強くするアンサンブル学習に進みます。
派手な深層学習が注目を集める時代でも、現場の多くは『まず軽くて確実な手法で土台を作る』ことから始まります。ナイーブベイズは、その最初の一歩を支える縁の下の力持ち。スパムフィルタという、私たちが毎日その恩恵にあずかっている仕組みの裏で、いまも静かに働いています。
そして、ベイズの『手がかりで見込みを更新する』という考え方は、機械学習にとどまらず、私たちが日々おこなう推論そのものでもあります。新しい証拠を見たら、頭の中の確率を少し書き換える——ナイーブベイズを学ぶことは、確率的にものを考える練習にもなるのです。最先端の手法を追いかけることも大切ですが、こうした“枯れた名作”をていねいに理解することは、機械学習という分野そのものへの理解を、確かなものにしてくれます。速さと割り切りの美学を、ぜひ味わってみてください。
ナイーブベイズ=手がかりの確率をかけ合わせて分類する。
「各手がかりは独立」と単純に割り切る(だから“ナイーブ”)。
軽くて速く、スパム判定などテキスト分類の古典。
A. ベイズの定理(確率の考え方)を使い、データの手がかりごとの確率をかけ合わせて、いちばん確率の高いクラスに分類する手法です。迷惑メール判定などのテキスト分類で長く使われてきました。
A. 各手がかり(単語など)が、おたがいに無関係(独立)だと単純に仮定して確率をかけ算するためです。現実には手がかりどうしに関係があることも多いですが、そこを割り切るので“ナイーブ=単純・お人よし”と呼ばれます。
A. もともとの確率(事前確率)に、手がかりから分かることをかけ合わせて、結論の確率(事後確率)を更新する考え方です。新しい証拠が出るたびに見込みを改める、私たちの自然な推論にも近いものです。
A. まず大量のスパム・通常メールから各単語がどちらに出やすいかを数えておきます。新しいメールの単語を取り出して、各単語のスパムらしさをかけ合わせ、スパム確率と通常確率を計算し、高いほうに振り分けます。
A. 計算がとても軽く高速で、大量の文書もすぐ処理できることです。少ないデータでもそれなりに動き、仕組みが単純で結果の解釈もしやすいという利点があります。
A. 「手がかりは独立」という仮定が現実には崩れていることが多い点、学習データに無い単語で確率がゼロになる点(対策あり)、微妙な文脈やニュアンスを捉えにくい点です。それでも実用上はよく当たります。
A. 迷惑メール判定、ニュースなどの文書ジャンル分け、口コミの感情分析、問い合わせの自動振り分けなど、主にテキスト(文章)の分類で力を発揮します。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わります。





