
多重共線性とは?重回帰分析の落とし穴と対処法を初心者向けに解説
ルミィ
AIの歩き方


決定木、フローチャートみたいで分かりやすそうだけど、本当にAIなの?
「決定木」は機械学習の中でも最も直感的に理解できる手法で、Yes/No の質問を繰り返して結論にたどり着くフローチャートのような構造です。AIの「ブラックボックス」問題に対する1つの解として、いまも実務でよく使われます。
私もね、決定木を知った時『これがAIなら、私も理解できるかも』って思ったんだよ
この記事は、決定木を初心者向けに丁寧に解説するガイドです。仕組み、Python での実装、剪定(過学習対策)、評価指標、ランダムフォレストとの関係、ビジネスでの活用例まで網羅。解釈性が重要な現場(医療・金融・人事)で機械学習を使いたい全ての人向けの、実践チュートリアルです。
「AIで予測できるのはわかった。でも、その判断理由を上司やお客さんに説明できないと使えない」——ビジネスの現場では、こうした場面がよくあります。決定木は、まさにその「説明できる」を強みにした手法です。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
決定木って、フローチャートを描く感覚に近いんだよね。だから「なんでAIってそう判断したの?」って聞かれても、ちゃんと説明できるのが強みなんだ~
決定木(けっていぎ、Decision Tree)とは、データをYES/NOの質問で枝分かれさせていき、最終的に「このデータはこのクラス」と判定する手法です。たとえば「顧客が商品を買うかどうか」を予測したいとき、ツリーは次のように枝分かれしていきます。
「年齢は30歳以上?」→YESなら「年収500万円以上?」→YESなら「購入する」、NOなら「購入しない」——というふうに、質問を重ねていくうちに答えにたどり着くイメージです。この「質問と枝分かれの連鎖」が木のような構造に見えるため、決定木と呼びます。
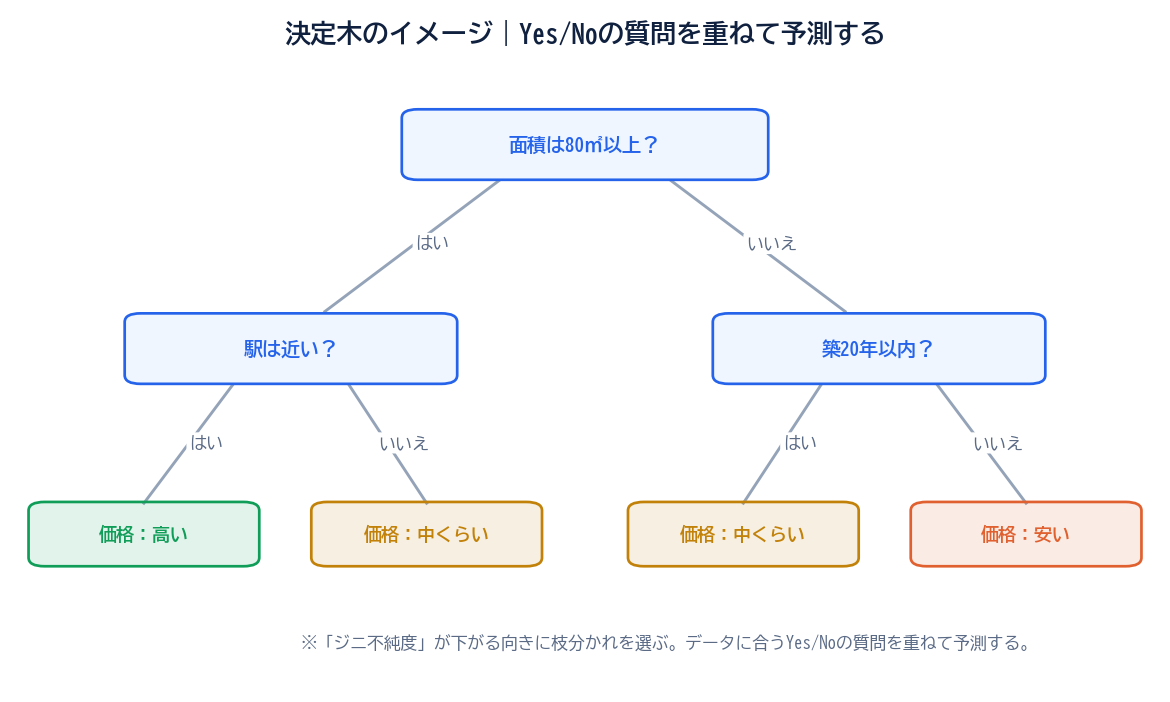
決定木の強みのひとつは、ひとつの手法で「分類」と「数値予測」の両方ができることです。
「購入する/しない」「スパム/スパムでない」のようにクラスを予測するときは分類木、「売上はいくらか」「家賃はいくらか」のように数値を予測するときは回帰木と呼びます。どちらの場合も、「データを枝分かれさせて分けていく」という基本の考え方は同じです。この汎用性の高さが、決定木がビジネスで広く使われる理由のひとつになっています。
決定木の中身でいちばんよく使われるのがジニ不純度(Gini Impurity)です。「枝分かれの基準(どの変数で・どの値で分けるか)を決めるためのものさし」と考えてください。
ジニ不純度はとてもシンプルで、「そのノード(枝先)に含まれるデータが、どれくらい混ざっているか」を表します。値は0に近いほど純粋で、2クラス分類では半々に混ざっているときに最大の0.5になります。3クラス以上では最大値が0.5を超えることもあります。「YESばかり」「NOばかり」のように1種類しかない状態ならジニ不純度=0(純粋)です。
計算式は次の通りです。クラスiの割合をpiとすると:
Gini = 1 − Σ pi²
式だけ見てもピンとこない人のために、実際の数値で追ってみましょう。
例:あるノードに10件のデータ。うち7件が「購入する(YES)」、3件が「購入しない(NO)」。
pYES = 7/10 = 0.7 pNO = 3/10 = 0.3
Gini = 1 − (0.7² + 0.3²) = 1 − (0.49 + 0.09) = 0.42
→ このノードはまだ混ざっている(0.42)。さらに枝分かれさせる価値がある。
比較:もし10件すべてが「YES」だったら?
Gini = 1 − (1.0² + 0²) = 0.00(完全に純粋。これ以上分ける必要なし)
決定木は枝分かれするたびに「分けたあとのジニ不純度がいちばん下がる質問はどれか?」を全変数から探して、いちばん効率よくデータを純粋にできる質問を選びます。これを葉が十分に純粋になるか、停止条件に達するまで繰り返すのが学習のしくみです。
決定木が長く愛されているのは、次のようなメリットがあるからです。
ひとつ目は、結果が人間にとってわかりやすいこと。判定の過程を「この質問にこう答えたから、この結論になった」と説明できます。この「説明可能性」は、金融や医療など、説明責任が重視される分野を理解するうえでも重要な考え方です。
ふたつ目は、データの前処理が比較的シンプルで済むこと。線形回帰のようにデータのスケールを細かく揃えなくても使いやすいのが特徴です。ただし、scikit-learnでカテゴリデータを扱う場合は、One-Hot Encodingなどで数値化してから学習させる必要があります。
みっつ目は、説明変数の重要度がわかること。「どの変数が予測に効いているか」がスコアとして出てくるため、ビジネス上の示唆を得やすくなります。
よっつ目は、非線形な関係も扱えること。変数間の関係が直線では表せないようなデータでも、枝分かれを重ねることで柔軟にフィットしてくれます。
一方で、決定木には次のような弱点もあります。
ひとつ目は、過学習しやすいこと。枝分かれをどこまでも続けられるため、学習データに合わせすぎて未知データでは精度が下がる、という現象が起きやすくなります。これを防ぐには、後述する剪定(せんてい)でモデルの複雑さを適度に抑える必要があります。
ふたつ目は、データのブレに弱いこと。学習データが少し変わっただけで木の構造が大きく変わってしまう、という不安定さがあります。
みっつ目は、単体だと予測精度に限界があること。これらの弱点を補うために、「ランダムフォレスト」や「XGBoost」など、決定木をたくさん組み合わせる手法が登場しました。これらは現代のビジネスで最もよく使われる機械学習手法のひとつになっています。
決定木の過学習を防ぐためのもっとも基本的なテクニックが剪定(pruning)です。木が伸びすぎないように、適度なところで枝分かれを止めたり、できあがった枝を切り戻したりする操作のことを指します。剪定には大きく2種類のアプローチがあります。
木が育ちすぎる前に「これ以上は枝分かれさせない」というルールを最初から設定する方法です。scikit-learnのDecisionTreeClassifierでは、次のようなパラメータで事前剪定をコントロールします。
いったん木を最後まで育ててから、「重要度の低い枝」を後から切り戻す方法です。scikit-learnではコスト複雑度剪定(CCP, Cost Complexity Pruning)が用意されており、ccp_alphaというパラメータで切り戻しの強さを調整できます。
概念を押さえたら、実際にコードで動かすイメージも持っておきましょう。詳細な実装手順と可視化は次の記事で扱いますが、scikit-learnでの基本的な書き方はこうなります。
from sklearn.tree import DecisionTreeClassifier
# モデル定義(過学習を抑えるため max_depth を設定)
model = DecisionTreeClassifier(max_depth=5, min_samples_leaf=10, random_state=42)
# 学習
model.fit(X_train, y_train)
# 予測精度の確認
print(model.score(X_test, y_test))max_depth=5とmin_samples_leaf=10はあくまでも出発点の目安です。最適な値は交差検証で探します。Pythonによる実装の詳細・可視化コードは「決定木を実装する」記事で順を追って解説します。
ビジネスの具体例をいくつか見てみましょう。金融での信用スコアリング(この顧客に融資して大丈夫か)、医療での診断補助(この症状はどの病気の可能性が高いか)、マーケティングでの顧客セグメント・購入予測・解約予測、製造業での不良品検知など、活用範囲は非常に幅広いです。
特に「なぜそう判定したのかを、現場の人に説明したい」というケースで決定木は強い味方になります。
「精度が高い」だけじゃなくて、「説明できる」ってビジネスではすごく大事なんだよね。お客さんに理由を聞かれたとき、ちゃんと答えられるのが決定木のいいところ!
決定木を学ぶと、次に必ず出てくるのがランダムフォレストやXGBoostです。それぞれどう違うのか、ざっくり比較してみましょう。
| 手法 | 特徴 | 強み | 向く場面 |
|---|---|---|---|
| 決定木 | 1本のツリー | 説明しやすい、実装が簡単 | 結果の根拠を説明したい場面 |
| ランダムフォレスト | 決定木を多数組み合わせた多数決 | 安定性が高く過学習しにくい | 精度と安定性を両立したい場面 |
| XGBoost / LightGBM | 弱い木を順番に積み上げる勾配ブースティング | 高精度、実務・分析コンペで広く使われる | 精度を最大限追いたい場面 |
「たくさんの決定木を作って、多数決で結論を出す」のがランダムフォレスト、「弱い木を少しずつ改善しながら積み上げる」のがXGBoostです。どちらも決定木を土台にした手法のため、決定木をしっかり理解しておくことが、これらへの理解の近道になります。
なお、XGBoostとLightGBMはどちらも勾配ブースティング系ですが、木の育て方や高速化の仕組みには違いがあります。ここでは「決定木を土台にした高精度な発展手法」と大づかみに理解しておけば十分です。
決定木の前段階として、回帰の基礎を押さえておくと理解がより深まります。また、分類タスクの定番であるロジスティック回帰も決定木と並んで重要な手法です。
▶ 関連記事:【完全ガイド】線形回帰分析を学ぶ全ステップ
▶ 関連記事:ロジスティック回帰とは?線形回帰との違いを初心者向けに解説
今後「AIの歩き方」では、決定木シリーズとして以下を順次公開していく予定です。
A. 決定木は「1本のツリーで結論を出す」手法、ランダムフォレストは「たくさんの決定木を作って多数決をとる」手法です。1本だけだと過学習しやすく不安定になりやすいですが、多数決にすることで精度と安定性が大きく上がります。実務では精度優先ならランダムフォレスト以上が選ばれることが多いですが、「根拠を説明したい」場面では1本の決定木に軍配が上がります。
A. 変数間の関係が非線形なデータや、条件分岐で説明しやすいデータに向いています。カテゴリ変数が多いデータにも使いやすい考え方ですが、scikit-learnで扱う場合はOne-Hot Encodingなどで数値化する必要があります。欠損値についても、使うライブラリや手法によって扱いが変わるため、必要に応じて補完や前処理を行ってから使うのが安全です。まず試してみて、交差検証で精度を評価するのが実務的なアプローチです。
A. どちらを使っても、多くの場合は似たような木の構造になりやすいです。ただし、データによっては選ばれる枝分かれが変わることもあります。scikit-learnのデフォルトはジニ不純度(criterion='gini')で、計算が軽いためそのまま使うのが一般的です。エントロピー(criterion='entropy')も試してみて、検証精度が良い方を選ぶという進め方でも問題ありません。
A. はい、scikit-learn(sklearn)というライブラリを使えば、数行のコードで実装できます。DecisionTreeClassifier(分類)やDecisionTreeRegressor(回帰)が用意されており、plot_tree関数で木を図として可視化することも可能です。具体的な実装手順は「決定木をPythonで実装する」記事で詳しく解説します。
A. データによって異なりますが、最初はmax_depth=3〜5くらいの浅めの木から試すと、構造を理解しやすくなります。深くするほど学習データへの当てはまりは上がりますが、過学習のリスクも高まります。GridSearchCVなどの交差検証を使って、検証データでの精度が最も高くなる深さを探すのが確実です。
決定木は、機械学習の手法のなかでも「なぜそういう結論になったのか」が人間にわかりやすいという、大きな強みを持っています。そのわかりやすさは、ビジネスでモデルを実際に使ううえで極めて重要な価値です。
さらに、この決定木をベースにして、ランダムフォレストやXGBoost・LightGBMといった実務やデータ分析コンペでよく使われる木ベースの勾配ブースティング手法が発展しています。決定木を押さえることは、その先の手法を理解するための土台になります。
大事なポイントをもう一度整理しておきましょう。
まずは「質問を重ねて枝分かれしていく」っていうシンプルなイメージをつかめればOK!次はPythonで実際に動かしてみたり、ランダムフォレストに進んでみたりしよう~
📚 機械学習入門シリーズ(全6回)
🧭 もっと広い地図で眺める:この手法は機械学習という大きな地図の一部です。教師あり・教師なし・強化学習という全体像や、クラスタリング・PCA・過学習・評価指標といった“使いこなし”は、連載「機械学習の地図」(概念編・全5回)で図解しています。





