信頼区間とは?95%信頼区間の正しい意味をやさしく図解
ルミィ
AIの歩き方


Yes/No を確率で答えたい――そんな分析、何使えばいい?
「このメールはスパムか」「この患者は病気か」「この顧客は離脱するか」――Yes/No を確率で答える分類問題は、ビジネスのあらゆる場面に登場します。これを扱うのが、ロジスティック回帰です。
私もね、最初は『線形回帰の親戚』くらいの認識だったけど、用途の広さに驚いたんだ
この記事は、ロジスティック回帰を初心者向けに解説する実践ガイドです。仕組み(線形回帰+シグモイド関数)、Python での実装、評価指標(精度・適合率・再現率・AUC)、過学習対策、線形回帰との使い分けまで網羅。分類問題を扱う必要のある全ての人にとって、最初に押さえるべき1記事です。
結論をひとことで言うと、こうです。
ロジスティック回帰は「線形回帰の出力を、シグモイド関数で0〜1の確率に押し込めた」分類の手法。「Yes/Noを確率で答えたい」場面で活躍します。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
「線形回帰は知ってるけど、ロジスティック回帰って何が違うの?」「シグモイド関数とかオッズ比とか、用語がややこしくて挫折しそう…」そんな悩みを持つ方に向けて、この記事ではロジスティック回帰の仕組みを、線形回帰と比較しながらやさしく解説していきます。私自身、最初にこの手法を学んだとき、「『回帰』なのに『分類』?」と頭が混乱したのを覚えています。同じところでつまずいた方も、安心して読み進めてください。
「回帰」とついてるのに「分類」に使うって、最初はビックリするよね!でも仕組みを知ると、「なるほど!」ってスッキリするはずだよ~
ロジスティック回帰とは、ある事象が「起こる」か「起こらない」かを確率で予測するための統計手法です。一見「回帰」と名がついていますが、実際は2値分類(Yes/No、0/1)に使われる代表的な機械学習アルゴリズムです。
身近な例だと、こんな場面で使われています。
このように、「Yes/No」を確率で答えるような問題で大活躍するのがロジスティック回帰です。
ロジスティック回帰は「分類」のための手法ですが、出力されるのは0〜1の確率値。たとえば「迷惑メールである確率:0.92」のように予測します。一般的に0.5を閾値として、それ以上なら「Yes」と判定しますが、用途によっては閾値を調整することもあります(後述の適合率・再現率と関係します)。
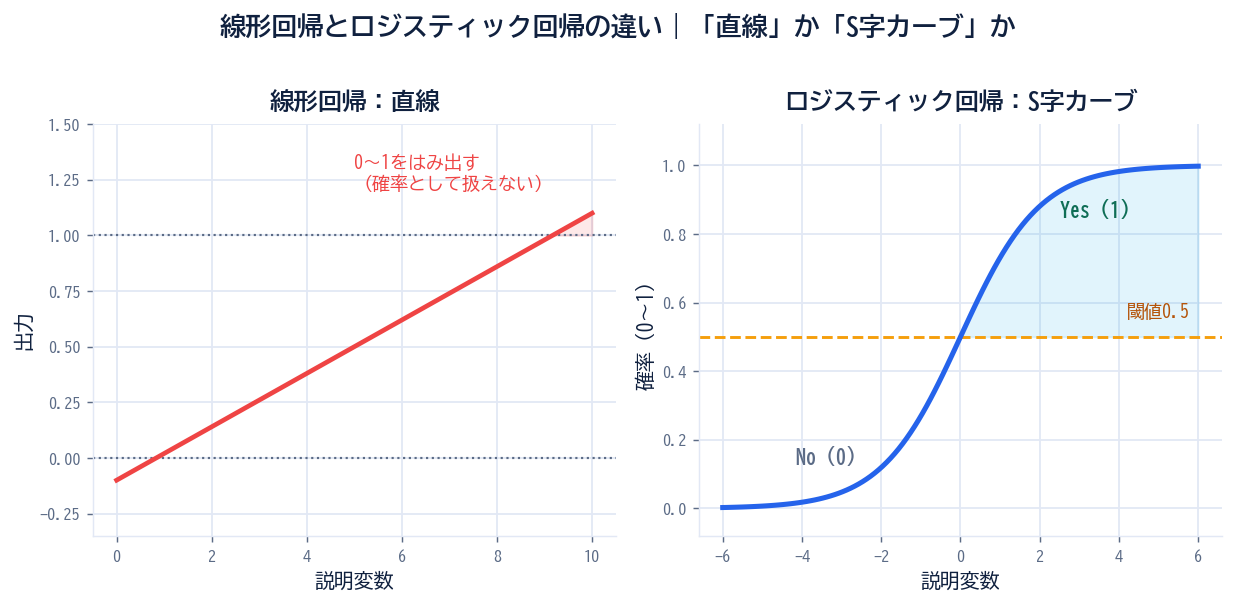
ロジスティック回帰を理解する一番の近道は、線形回帰との違いを比較することです。まず全体像を表で押さえてから、個別に見ていきましょう。
| 観点 | 線形回帰 | ロジスティック回帰 |
|---|---|---|
| 予測対象 | 連続値(売上、気温など) | 確率(0〜1)→分類に使う |
| モデルの形 | 直線 | S字カーブ(シグモイド関数) |
| 出力の解釈 | そのまま数値として読める | 確率→閾値で「Yes/No」に分ける |
| 評価指標 | R²、RMSE、MAE | 精度、適合率、再現率、F値、AUC |
| よく使う場面 | 売上予測、価格予測、需要予測 | スパム判定、与信審査、医療診断 |
線形回帰は、身長から体重を予測する、広告費から売上を予測するのように、連続的な数値を予測する手法です。グラフにすると、データの傾向を表す1本の直線でモデル化されます。
一方、ロジスティック回帰では出力を必ず0〜1の範囲に収めたいので、直線ではなくシグモイド関数と呼ばれるS字カーブを使います。これにより、どんな入力値でも確率として解釈できる出力が得られます。
線形回帰とロジスティック回帰は、見た目こそ違いますが、「説明変数の重み付き合計(z = β₀ + β₁x₁ + β₂x₂ + …)」を作るという土台は共通です。違いは、そのzをそのまま使うか(線形回帰)、シグモイド関数で確率に変換するか(ロジスティック回帰)だけ。だから「線形回帰の兄弟」と言われます。
S字カーブと「重み付き合計」、この2つを押さえればロジスティック回帰の骨組みはばっちりだよ!見た目はちょっと違って見えるけど、中身は線形回帰と友達みたいなものなんだよね~
シグモイド関数は、ロジスティック回帰の心臓部とも言える重要な関数です。式は少し難しく見えますが、やっていることはシンプルです。
σ(z) = 1 / (1 + e−z)
ここで z = β₀ + β₁x₁ + β₂x₂ + … で、これは線形回帰と同じ形です。つまり、線形回帰の出力をシグモイド関数で「0〜1の確率」に押し込めたのが、ロジスティック回帰なのです。
式だけ見てもピンとこない人のために、実際の数値で追ってみましょう。
z の値ごとに、シグモイド関数の出力 σ(z) を計算してみる:
z = 0 → σ(0) = 1 / (1 + 1) = 0.500(ちょうど真ん中)
z = 1 → σ(1) ≈ 0.731(Yes寄り)
z = 2 → σ(2) ≈ 0.881(かなりYes)
z = −1 → σ(−1) ≈ 0.269(No寄り)
z = −2 → σ(−2) ≈ 0.119(かなりNo)
→ z がプラスに大きくなるほど確率は1に近づき、マイナスに大きくなるほど0に近づく。けっして1を超えたり、0より下になったりしない(=これが「確率として扱える」ポイント)。
ロジスティック回帰でよく出てくる用語が「オッズ」と「オッズ比」です。馬券で聞くオッズと考え方は同じです。
たとえば、年齢が1歳上がるごとに「ある病気にかかるオッズ比が1.05」だとすると、1歳ごとにオッズが約5%上がると解釈できます。10歳上がれば、おおよそ 1.0510 ≈ 1.63 倍。「年齢」という変数が、結果にどれくらい効いているかを、こうした形で具体的に説明できるのがロジスティック回帰の強みです。
オッズ比は厳密には「確率が何倍になるか」ではなく「オッズが何倍になるか」です。確率が0.1のときと0.9のときでは、同じ「オッズ1.5倍」でも実際の確率変化は大きく異なります。正確な解釈が必要な場面(医療・金融など)では、確率に直して確認するのが安全です。
ロジスティック回帰はscikit-learnを使えば、数行のコードで実装できます。基本的な流れは線形回帰とほぼ同じです。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル作成・学習
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# 予測(クラス)
y_pred = model.predict(X_test)
# 予測(確率)
y_proba = model.predict_proba(X_test)predict() はクラス(0か1)を返し、predict_proba() は各クラスの確率を返します。閾値の調整をしたい場面では predict_proba から自分で判定するのが定石です。max_iter は収束しないときに増やすパラメータで、scikit-learnのデフォルトでは警告が出ることがあるので明示しておくと安心です。scikit-learnの LogisticRegression はデフォルトでL2正則化がかかっています。特徴量のスケールが揃っていないと結果が歪むため、事前に標準化(StandardScaler など)しておくのが基本です。
▶ 関連記事:【完全ガイド】線形回帰分析を学ぶ全ステップ
分類モデルの評価には、線形回帰のR²とは違う指標を使います。代表的なのが混同行列から計算される以下の指標です。
「迷惑メール判定」のように誤検知(False Positive)を減らしたいなら適合率を、「がん検診」のように見逃し(False Negative)を減らしたいなら再現率を重視します。両方バランスよく見たい場合はF値が便利。「Yes:No = 1:99」のような偏ったデータでは、精度ではなくAUCを基準にしましょう。
class_weight='balanced' や AUC で評価する工夫が必要▶ 関連記事:多重共線性とは?回帰分析でハマる落とし穴を初心者向けに解説
注意点を知っておくと、データを見たとき「あ、これはロジスティック回帰と相性がいいね!」って考えられるようになるよ!
A. 基本的には同じものを指します。「対数オッズ(logit)」を線形モデルで予測することからロジット回帰、確率を出すロジスティック関数(シグモイド関数)を使うことからロジスティック回帰と呼ばれます。論文・教科書では使い分けがあるものの、実務では同じ手法として扱って問題ありません。
A. はい、3クラス以上の分類にも拡張できます。代表的な方法は2つで、One-vs-Rest(クラスごとに「自分 vs それ以外」のロジスティック回帰を作る)と、多項ロジスティック回帰(softmax回帰)です。scikit-learnのLogisticRegressionでは multi_class パラメータで指定できます。クラスが増えるほど決定木やランダムフォレストの方が扱いやすい場面も多いので、用途に応じて比較しましょう。
A. 線形回帰でも0/1のラベルを予測しようとすれば数値は出ますが、出力が0未満や1超になることがあり、確率として解釈できません。また、誤差の分布も不適切になります。シグモイド関数で出力を必ず0〜1に収めるロジスティック回帰の方が、分類問題には自然です。
A. 一般的なアプローチは、ロジスティック回帰でベースラインを作り、それから決定木・ランダムフォレスト・XGBoostなどで精度を比較する流れです。ロジスティック回帰は「係数で説明できる」という強みがあり、結果の解釈や報告に向いています。複雑な非線形関係を捉えたい場合は、ツリー系モデルの方が精度が上がりやすいです。
A. 用途次第です。誤検知のコストが高いなら適合率を優先(例:迷惑メール判定で大事なメールがスパム扱いされたら困る)。見逃しのコストが高いなら再現率を優先(例:がん検診で陽性を見逃したら命に関わる)。両方バランスを取りたい場合はF値、閾値全体での性能を見たい場合はAUCを使います。
ロジスティック回帰は、機械学習の「分類」に最初に触れるのに最適な手法です。仕組みもシンプルで、結果の解釈もしやすく、実務でも幅広く使われています。
線形回帰とロジスティック回帰、この2つを押さえれば、機械学習の基礎の半分はクリアです。次は決定木やランダムフォレストのような、もっと表現力のあるモデルへ進んでいきましょう。
今すぐ試せる次の一歩:
1. scikit-learnの load_iris や load_breast_cancer など、組み込みデータセットで LogisticRegression を動かしてみる
2. 特徴量を StandardScaler で標準化してから学習し、結果の違いを比べる
3. predict_proba で確率を出し、閾値を0.5から変えると適合率・再現率がどう動くかを確認する
▶ 関連記事:決定木とは?仕組み・ジニ不純度・剪定までやさしく解説
📚 機械学習入門シリーズ(全6回)
🧭 もっと広い地図で眺める:この手法は機械学習という大きな地図の一部です。教師あり・教師なし・強化学習という全体像や、クラスタリング・PCA・過学習・評価指標といった“使いこなし”は、連載「機械学習の地図」(概念編・全5回)で図解しています。