
データの種類とは?量的データと質的データの違いをやさしく図解
ルミィ
AIの歩き方

前回の機械学習の3つの学び方で、正解を与えず構造を見つける「教師なし学習」を紹介しました。その代表選手が、今回のクラスタリングです。
クラスタリングは、ひとことで言うと「似たものどうしを、自動でグループに分ける」こと。誰も「これが正解」と教えていないのに、AIがデータの“近さ”だけを頼りに仲間分けをしてくれます。この記事では、その仕組み(代表のk-means)と使いどころを、図でやさしく整理します。
🧭 連載「機械学習の地図」(全5回)
線形回帰や決定木の“その先”——機械学習の全体像と、回帰・木以外の代表的な考え方を、順番にやさしくたどる連載です。

正解を教えなくても、似たものを勝手にまとめてくれる。これが教師なし学習のいちばん身近な例だよ。
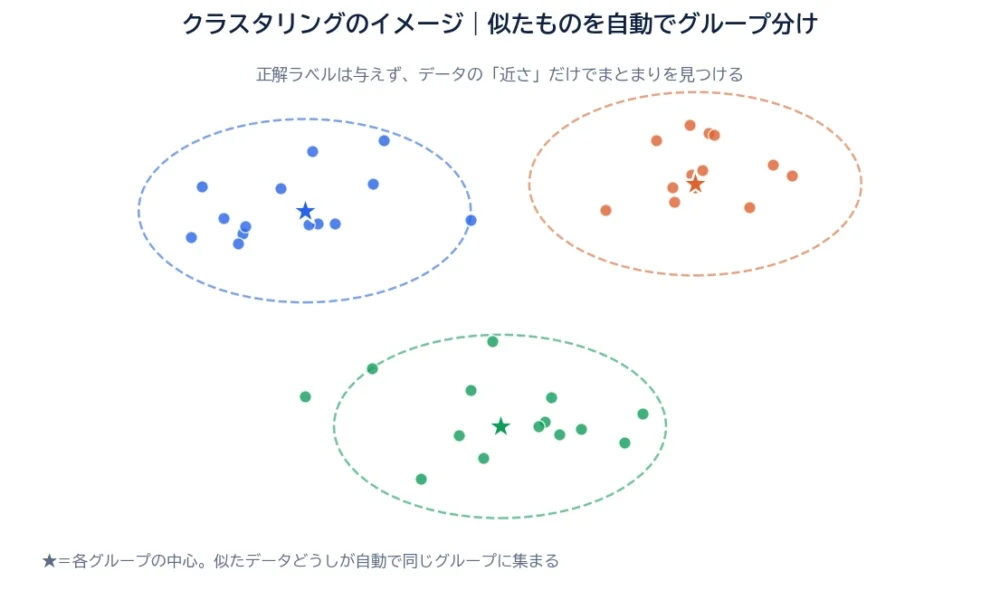
クラスタリングは、データをいくつかの「クラスタ(かたまり)」に分ける手法です。図のように、近くにあるデータどうしを同じグループにまとめ、離れているものは別のグループにします。
大事なのは、正解ラベルを使わないこと。「この客はAグループ」といった答えを人が用意するのではなく、データの特徴の近さだけで、AIが自分でグループの境目を見つけます。だから、人間が気づいていなかった意外なまとまりが見つかることもあります。
クラスタリングの方法はいくつもありますが、いちばん有名なのがk-means(ケイ平均法)です。仕組みは驚くほど直感的で、4ステップの繰り返しです。
「集めて、真ん中を取り直して、また集める」をくり返すうちに、自然とまとまりが安定していきます。図の★が、最終的に落ち着いた各グループの中心です。
k-meansの悩みどころは、「グループをいくつにするか(k)」を最初に決めないといけないことです。3つがいいのか5つがいいのか、データは教えてくれません。
目安としてよく使われるのがエルボー法です。kを2,3,4…と増やしながら「グループ内のばらつき」を測ると、最初は急に小さくなり、あるところから減り方が鈍ります。その“ひじ(elbow)”のように曲がる点が、ちょうどよいkの目安、という考え方です。とはいえ最後は、「分けた結果が、目的にとって意味があるか」を人が判断するのがいちばん大切です。
クラスタリングは、ビジネスの現場で広く使われています。
「正解は分からないけれど、とにかくデータの傾向をつかみたい」という場面で、最初の一手として重宝します。
もう少し具体的に、k-meansの動きを追ってみましょう。あるカフェが、常連さんを「来店頻度」と「1回の注文額」の2つで分けたい、とします。
最初はランダムだった分かれ方が、くり返すうちに“意味のあるまとまり”へ収束していく——これがk-meansの気持ちよさです。出てきたグループに人間が名前を付ければ、そのまま施策(常連向けクーポン、休眠掘り起こし等)につながります。
k-meansと並ぶもう一つの代表が、階層的クラスタリングです。こちらは、近いものから順にペアでくっつけていき、最後は全体が1つの大きな木にまとまるやり方です。
いちばんの利点は、グループ数を最初に決めなくていいこと。まず木(デンドログラムと呼ぶ枝分かれ図)を作っておき、あとから「この高さで切れば3グループ、もっと下で切れば5グループ」と、切る位置で粒度を選べます。
| k-means | 階層的クラスタリング | |
|---|---|---|
| グループ数 | 最初に決める | あとから切る位置で選べる |
| 得意な規模 | 大きなデータも速い | 小〜中規模向き(重め) |
| 出力 | 各データの所属 | 枝分かれの木(全体像) |
「とにかく速く大量に分けたい」ならk-means、「いくつに分けるか迷っていて、全体の入れ子構造も見たい」なら階層型、と使い分けると良いでしょう。
「グループに分ける」と聞くと、教師あり学習の分類と混同しがちですが、別ものです。違いは“正解を使うか”の一点です。
| 分類(教師あり) | クラスタリング(教師なし) | |
|---|---|---|
| 正解ラベル | 使う(犬/猫など) | 使わない |
| やること | 決まったカテゴリに振り分ける | 似たものでまとまりを自分で作る |
| 例 | 迷惑メール判定 | 顧客のセグメント発見 |
分類は「あらかじめ決まった箱に入れる」、クラスタリングは「箱そのものをデータから作る」。この違いを押さえると、両者を取り違えなくなります。
便利なk-meansにも、知っておきたいクセがあります。
これらは「使い方の注意」であって、クラスタリングの価値を損なうものではありません。クセを知って使えば、強力な“発見の道具”になります。
なお、k-meansや階層型のほかにも、点が混み合った場所をまとまりとみなすDBSCANという手法もあります。どこにも属さない孤立点を“外れ値”として弾けるのが特徴で、複雑な形のまとまりや異常検知に強く、グループ数を指定しなくてよい利点もあります。手法は一つではないので、データの形に合わせて選ぶのがコツです。
クラスタリングは「実行は簡単、活かすのは奥が深い」手法です。結果を意味あるものにするためのコツが3つあります。
アルゴリズムは中身を計算してくれますが、「何を入れて」「結果をどう読むか」は人間の仕事。ここがクラスタリングの腕の見せどころです。
正解がない教師なし学習では、「うまく分けられたか」をどう測るのでしょう。代表的なのがシルエット係数です。
これは、「同じグループ内では近く、別のグループとは遠く分かれているか」を数値(−1〜1)で表すものです。1に近いほど、くっきり分かれた良いクラスタリングと判断できます。グループ数kをいくつにするか迷ったとき、kを変えながらこの値を見て決める、という使い方もできます。正解がなくても“分かれの良さ”は測れる、というわけです。
クラスタリングは、正解を教えずに、似たものを自動でグループ分けする教師なし学習の代表です。k-meansは「集めて、中心を取り直して、また集める」のくり返しで、データの自然なまとまりを見つけます。
k-meansだけでなく、グループ数を後から選べる階層的クラスタリング、外れ値に強いDBSCAN、そして分かれの良さを測るシルエット係数まで引き出しに入れておけば、「とりあえず分けてみる」から一歩進んで、データの形と目的に合った分け方を選べるようになります。まずは手元のデータをk-meansで分け、出てきたグループに自分で名前を付けてみるところから始めてみてください。
顧客分析から異常検知まで、「まずデータを眺めて傾向をつかみたい」場面で活躍します。グループ数を自分で決める必要があるなどのクセを押さえれば、心強い相棒になります。
クラスタリング=正解なしで似たものをグループ分け。
代表はk-means(集める→中心更新→繰り返し)。
分類との違いは「正解を使うか」。クラスタリングは箱そのものを作る。
次回は、もう一つの教師なし学習——たくさんの情報を大事な軸にまとめる主成分分析(PCA)・次元削減に進みます。
A. 正解ラベルを使わず、データの特徴の近さだけで似たものを自動的にグループ(クラスタ)に分ける手法です。教師なし学習の代表で、顧客のセグメント分けや異常検知などに使われます。
A. まずグループ数kぶんの中心をランダムに置き、各データを最も近い中心のグループに振り分け、各グループの真ん中に中心を移動する、を繰り返します。中心がほとんど動かなくなったら完成です。
A. エルボー法がよく使われます。kを増やしながらグループ内のばらつきを測り、減り方が鈍る“ひじ”のような点を目安にします。最終的には、分けた結果が目的にとって意味があるかを人が判断することが大切です。
A. 分類は正解ラベルを使い、あらかじめ決まったカテゴリに振り分ける教師あり学習です。クラスタリングは正解を使わず、データから自分でまとまり(箱)を作る教師なし学習です。正解を使うかどうかが最大の違いです。
A. 顧客のセグメント分け、異常検知、似た文書や画像の整理、データ傾向の探索などに使えます。正解が分からない状態で、まずデータの傾向をつかみたいときの最初の一手として便利です。
A. グループ数を自分で決める必要があること、複雑な形のまとまりが苦手なこと、特徴量のスケールや中心の初期位置で結果が変わることなどです。標準化や複数回の試行で対処します。
A. 唯一の正解はありません。同じデータでもグループ数や手法で結果が変わります。だからこそ、分けた結果が目的に照らして役立つかどうかを人が評価することが重要になります。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わるため、実務では各手法の前提条件もご確認ください。





