
信頼区間とは?95%信頼区間の正しい意味をやさしく図解
ルミィ
AIの歩き方

データ分析と聞くと、いきなり平均やグラフを思い浮かべがちです。でも、その前に必ず確かめたいことがあります。「そのデータは、どんな種類のデータか?」——これを知らずに分析を始めると、平気で“意味のない計算”をしてしまうのです。
たとえば、アンケートの「性別」を数字(男=1, 女=2)で入力したからといって、その平均(1.5)を出しても意味はありませんよね。データには種類があり、種類によって使える計算・グラフ・手法が変わります。連載「データの見方・まとめ方」の第1回として、まずはこの“データの地図”を押さえましょう。
この連載は、統計のきほん(標準偏差・正規分布・相関・検定)の“ひとつ手前”——集めたデータをまず「要約して・見る」ための記述統計をあつかいます。
📏 連載「データの見方・まとめ方」(記述統計編・全4回)
集めたデータを「どう要約し、どう見るか」——データ分析の“いちばん最初の一歩”を、図でやさしく整理する連載です。

分析の前に「これは数で測るデータ? 種類で分けるデータ?」を確かめる。これだけで、的外れな計算を防げるよ。
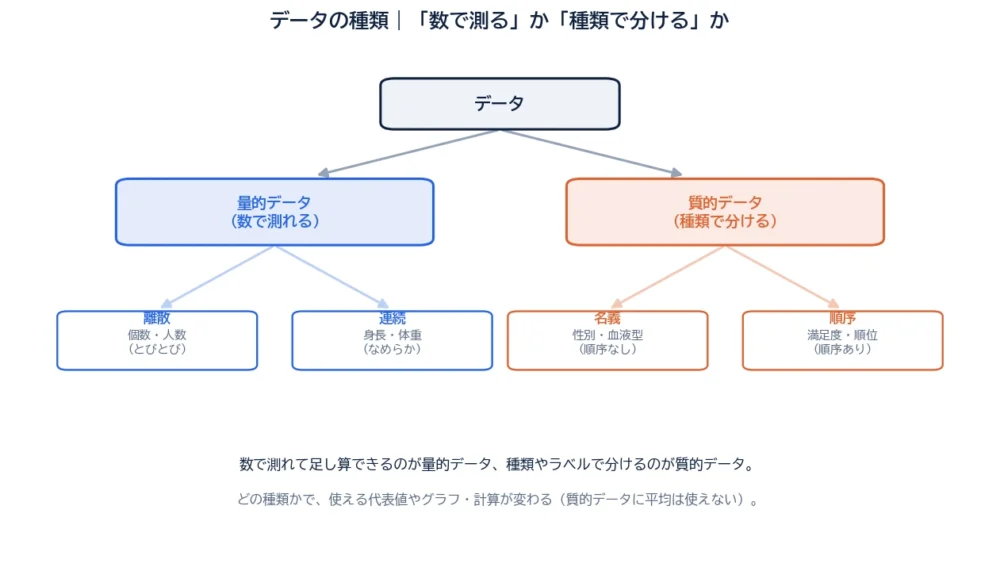
データは、まず大きく2つに分けられます。
ざっくり、「足し算・平均してみて意味があるか?」が見分けのカギです。身長の平均は意味があるけれど、血液型の平均(A型とB型を足して2で割る?)は意味がありません。この2つはさらに、それぞれ2つに枝分かれします。
数で測れる量的データは、さらに離散と連続に分かれます。
「数えるもの」が離散、「測るもの」が連続、と考えると分かりやすいです。
種類で分ける質的データは、名義と順序に分かれます。違いは「順番に意味があるか」です。
順序データは「並び順」はありますが、間隔は等しいとは限りません。「満足→普通」と「普通→不満」が同じ“1段階”とは限らないからです。ここが、次に出てくる尺度水準の話につながります。
もう一段くわしく分けると、データは4つの尺度水準に整理されます。少し専門的ですが、表で押さえておくと役立ちます。
| 尺度 | 種類 | 特徴 | 例 |
|---|---|---|---|
| 名義尺度 | 質的 | 区別だけ(順序なし) | 性別・血液型 |
| 順序尺度 | 質的 | 順序はある(間隔は不定) | 満足度・順位 |
| 間隔尺度 | 量的 | 間隔が等しい(0は基準点) | 気温(℃)・西暦 |
| 比例尺度 | 量的 | 間隔が等しく、0が“無”を表す | 身長・体重・売上 |
下にいくほど“情報が豊か”になり、使える計算が増えます。間隔尺度と比例尺度の違いは少しややこしいですが、「0が“まったく無い”を意味するか」がポイント。気温0℃は「温度が無い」わけではない(間隔尺度)が、身長0cmは「無い」を意味する(比例尺度)、という具合です。もっとも、日々の分析でここまで厳密に4尺度を区別する場面は多くありません。まずは『量的か質的か』、その質的が『順序ありか・なしか』——この大きな3分類さえ押さえておけば、実用上は十分です。
データの種類を意識することは、分析の“事故”を防ぎます。具体的には、こんな場面で効いてきます。
「性別の平均」のような意味のない計算をしないために、分析の最初に“このデータは何尺度か”を確かめる——これがデータ分析の基本作法です。
難しく考えなくても、次の問いを投げかければ、だいたい見分けられます。
この2つの問いだけで、目の前のデータがどの種類かは、ほぼ判断できます。慣れてくれば、データの一覧をぱっと見ただけで、各列がどの種類かを直感的に振り分けられるようになります。まずはここから始めましょう。
実際にやってみると、ぐっと身につきます。あるお店のアンケートを例に、各項目がどの種類かを分類してみましょう。
同じアンケートでも、項目ごとに種類が違うのが分かります。この仕分けができると、「年齢は平均が出せる」「満足度は中央値や最頻値で見る」「性別は最頻値(いちばん多い回答)で見る」と、各項目の扱い方が自然に決まります。
データの種類が分かれば、使える道具が決まります。表で対応づけておきましょう。
| データの種類 | 使える代表値 | 向くグラフ |
|---|---|---|
| 量的(離散・連続) | 平均・中央値・最頻値すべて | ヒストグラム・箱ひげ図・折れ線 |
| 質的・順序 | 中央値・最頻値 | 棒グラフ(順序を保つ) |
| 質的・名義 | 最頻値のみ | 棒グラフ・円グラフ |
「種類が分かれば、使う道具が決まる」。この対応が頭に入っていると、データを前にして「何を計算し、どう描けばいいか」で迷わなくなります。だからこそ、分析の最初に種類を確かめるのが大切なのです。
データの種類は、統計だけでなく機械学習でも超重要です。モデルに渡す材料(特徴量)が量的か質的かで、前処理のしかたが変わるからです。
数値(量的データ)はそのままモデルに渡せますが、「都道府県」「血液型」のような質的データは、そのままでは渡せません。「東京=1, 大阪=2…」と番号をふっても、モデルが「大阪は東京の2倍」と誤解してしまうからです。そこで、カテゴリを0と1の列に変換する“ワンホットエンコーディング”などの前処理をします。「これは量的か質的か」を最初に見る——この習慣は、データ分析でもAIの前処理でも、まったく同じように効いてくるのです。
最後に、まぎらわしい例を押さえておきましょう。見た目は数字でも、実は質的データというケースがあります。
見分けのコツは、やはり「その数字を足したり平均したりして、意味があるか?」。背番号の平均や郵便番号の平均は、ナンセンスですよね。見た目の数字にだまされず、中身で判断する——これさえ意識すれば、まぎらわしいデータも正しく仕分けられます。
データは大きく、数で測れる「量的データ」(離散・連続)と、種類で分ける「質的データ」(名義・順序)に分かれ、さらに4つの尺度水準に整理されます。種類によって、使える代表値・グラフ・手法が変わります。
「足し算・平均して意味があるか」を問えば、量的か質的かはすぐ見分けられます。分析を始める前に、まずデータの種類を確かめる——この一手間が、的外れな計算を防ぎ、正しい分析の出発点になります。次回は、量的データの“真ん中”を表す代表値(平均・中央値・最頻値)に進みます。
地味なテーマに見えるかもしれませんが、「データの種類を見分ける」は、データ分析のいちばん最初の関門です。ここを飛ばして平均やグラフに飛びつくと、知らないうちに“意味のない計算”をしてしまいます。逆に、種類さえ正しく見分けられれば、その先で何をすればいいかは、自然と決まっていきます。すべての分析は、ここから始まるのです。そして、ここで身につけた『データの種類を見分ける目』は、この先ずっと使えます。新しいデータに出会うたび、まず『これは量的? 質的?』と問う——そのひと手間が、あなたを“なんとなくの分析”から卒業させてくれます。
データ=量的(数で測る:離散・連続)+質的(種類で分ける:名義・順序)。
さらに4つの尺度水準(名義・順序・間隔・比例)に整理できる。
種類で使える代表値・グラフ・手法が変わる。質的データに平均は使えない。
A. 量的データは身長や点数のように「数で測れて、足し算や平均に意味がある」データです。質的データは性別や血液型のように「種類で分けるラベル」で、数として計算する意味はありません。『平均して意味があるか』が見分けの目安です。
A. 離散データは人数や個数のように、とびとびの値しかとらないもの(1.5人はない)です。連続データは身長や時間のように、どこまでも細かく測れるなめらかな値です。『数えるもの』が離散、『測るもの』が連続と考えると分かりやすいです。
A. どちらも質的データですが、名義データは性別や血液型のように順番に意味がないラベル、順序データは満足度や順位のように順番に意味があるものです。ただし順序データは、各段階の間隔が等しいとは限りません。
A. データを名義・順序・間隔・比例の4段階に分けた分類です。下にいくほど情報が豊かで使える計算が増えます。間隔尺度(気温など)と比例尺度(身長など)の違いは、0が『まったく無い』を意味するかどうかです。
A. 種類によって使える代表値・グラフ・手法が変わるためです。たとえば名義データに平均を出しても意味がなく、相関や回帰は量的データが前提です。分析の最初に種類を確かめることで、意味のない計算を防げます。
A. なりません。数字を割り当てても、それはただのラベル(名義データ)のままです。男=1・女=2の平均1.5に意味がないことからも分かります。見た目が数字でも、足し算や平均に意味があるかで判断します。
A. まず『足し算・平均して意味があるか』を問い、あれば量的データ、なければ質的データです。質的データなら、さらに『順番に意味があるか』を問い、あれば順序、なければ名義データと判断できます。
※本記事は2026年6月時点の一般的な統計の考え方を初心者向けに整理したものです。Excelの機能名やボタン位置はバージョンにより異なる場合があります。





