
Excelでできる!重回帰分析の使い方【2026年最新版・初心者向け】
ルミィ
AIの歩き方


ランダムフォレスト、決定木の親戚って聞くけど、何が強いの?
ランダムフォレストは決定木を「大量に作って多数決」させるアンサンブル学習の代表格で、Kaggle や実務で長年活躍する、機械学習の主力モデルの1つです。XGBoost・LightGBM が台頭した今でも、解釈性と安定性で選ばれ続けています。
私もね、Kaggle で最初にメダル取れたのがランダムフォレストだったんだ
この記事は、ランダムフォレストを初心者から実務レベルまで使いこなすための完全ガイドです。仕組み(バギング・特徴量サンプリング)、Python での実装(scikit-learn)、ハイパーパラメータチューニング、特徴量重要度、XGBoost との使い分けまで網羅。機械学習を本気で実務に活かしたい全ての人向けの実践チュートリアルです。
本記事では、ランダムフォレストを「決定木の集合知」という直感的な比喩から、内部の数理(バギング・ランダム特徴選択)、scikit-learnでの実装、ハイパーパラメータチューニングまで、初心者でも追えるように順を追って解説します。読み終わるころには、自分のデータに対して「ランダムフォレストを使うべきか、別のアルゴリズムを使うべきか」を判断できるようになります。
「ランダム」と「フォレスト(森)」って、どういう意味なんだろう?
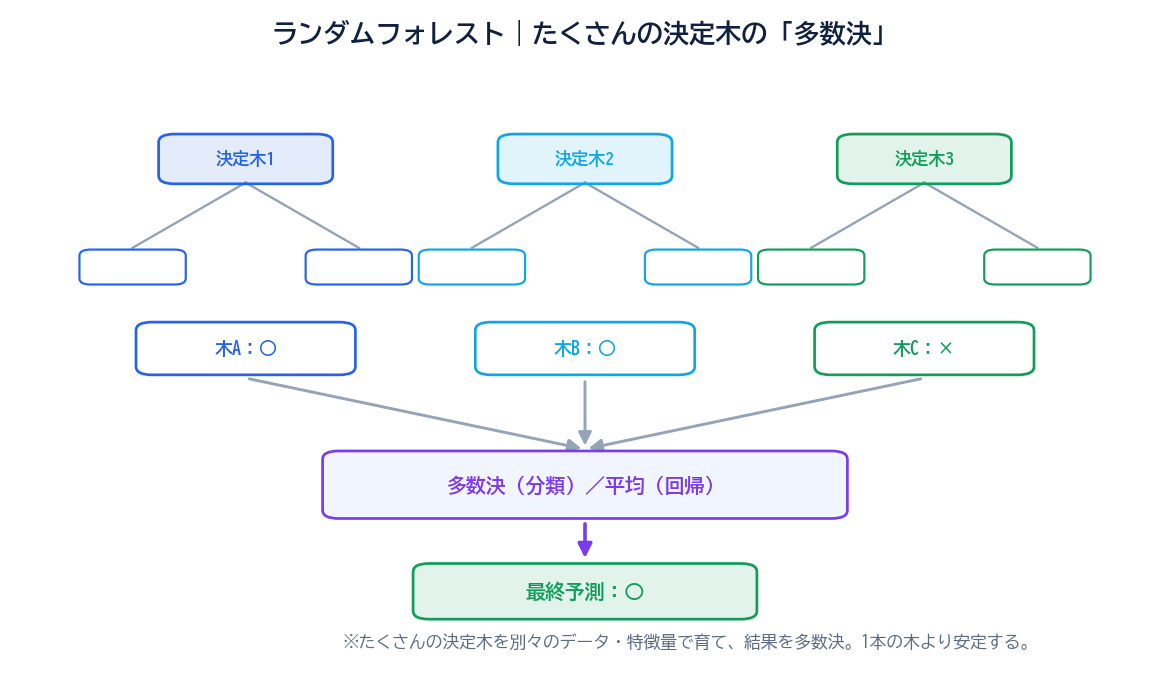
ランダムフォレストは、たくさんの決定木(Decision Tree)を作り、その多数決(または平均)で予測する機械学習アルゴリズムです。「ランダム」に作った「決定木」が「森(Forest)」のように集まっているので、ランダムフォレストと呼ばれます。
イメージとしては、こんな状況を想像してみてください。あなたが「この患者さんは病気かどうか」を判定したいとき、1人の医師の意見だけ聞くのと、100人の医師に別々に診てもらって多数決を取るのとでは、どちらが信頼できるでしょうか?――おそらく後者ですよね。一人ひとりは見落としをするかもしれませんが、100人の見立ての多数決なら、特定の医師の偏見やミスが希薄化されます。
ランダムフォレストはまさにこの発想です。「1本の決定木」よりも「100本の決定木の多数決」のほうが安定して当たる。これがランダムフォレストの核心アイデアです。
ルミィ:「1人の天才より、100人の凡人の多数決のほうが当たることもあるんだね。」
ランダムフォレストを理解するには、まず決定木(Decision Tree)の復習が必要です。決定木は「Yes/Noの質問を繰り返してデータを分類する」仕組みのアルゴリズムで、こんな構造をしています。
たとえば、ある患者が糖尿病かどうかを判定する決定木は、こんな質問の連鎖になります:
決定木の最大の魅力は解釈のしやすさ。「BMIが30以上で、年齢が50歳以上で、血糖値が126以上」という具体的な分岐ルールが目に見えるので、人間が判断根拠を理解しやすいのです。
ところが、単独の決定木には致命的な弱点があります。それが過学習(オーバーフィッティング)です。
決定木は、深く分岐させればさせるほど、訓練データに対する精度が上がります。極端な話、訓練データの全サンプルを完璧に分類するまで分岐を続ければ、訓練精度は100%になります。しかし、そうやってできた木は訓練データの細かいノイズまで学習してしまっており、新しいデータ(テストデータ)には全く当たらないという事態が起きます。「訓練データには100点、テストデータには60点」――これが過学習の典型例です。
この問題を解決するために考案されたのが、ランダムフォレストです。「木を1本だけ作って深掘りするのではなく、適度な深さの木をたくさん作って多数決を取る」ことで、過学習を抑え、汎化性能(未知のデータへの精度)を高めます。
「決定木をたくさん作る」と聞くと「同じデータから同じ木が何本もできるだけでは?」と思うかもしれません。実際、ただ単に決定木を100本作っても、すべて同じ木になってしまい多様性がありません。多様性のない多数決は、1人の意見と変わりません。
そこでランダムフォレストは、2種類の「ランダム」を導入して、各木に異なる視点を持たせます。
1つ目のランダムは、ブートストラップサンプリングと呼ばれる手法です。元の訓練データから、同じサンプル数だけ「復元抽出」(一度引いたサンプルを戻して再度引ける)でランダムに取り出した新しいデータセットを、各木のために用意します。
たとえば訓練データが1000件あれば、1本目の木のためには「1000件中、重複を許して1000件をランダム抽出」したデータを使います。2本目の木のためには「また同じやり方で別の1000件」を抽出します。この作業を木の数だけ繰り返します。
結果として、各木は少しずつ異なるデータで訓練されることになります。確率的にいうと、ブートストラップサンプリングでは、元データの約63.2%のユニークサンプルが含まれ、残りの約36.8%は含まれません(含まれなかったサンプルは後述の「OOB誤差」で活用されます)。
このようにブートストラップで作ったデータで学習させて、結果を集約(Aggregate)する手法をバギング(Bagging = Bootstrap Aggregating)と呼びます。
2つ目のランダムは、各分岐ノードで使う特徴量をランダムに制限する仕組みです。
通常の決定木は、各分岐で「全特徴量の中で最も情報利得が高い特徴量」を選びます。たとえば特徴量が10個あれば、毎回その10個全てを比較します。一方、ランダムフォレストでは、各分岐ごとに「全特徴量からランダムに選んだ一部だけ」を使うのです。
具体的には、特徴量の総数を p とすると:
max_features='sqrt' がデフォルトmax_features=1.0(全特徴量を候補にする)です。実務では 1.0、0.5、'sqrt' などを比較して決めるのがよいでしょうたとえば特徴量が16個ある分類問題なら、各分岐で4個(√16 = 4)を毎回ランダムに抽選し、その中から最良のものを選びます。これによって、「常に同じ特徴量が分岐の支配的役割を果たす」事態を防ぎ、各木が異なる視点を持つようになるのです。
たとえば100本の木を作ったとして、最終予測は次のように行います:
これだけです。シンプルでしょう?――でも、この単純な仕組みが、実務で驚くほど強力な精度を生み出します。
ランダムフォレストの強さには、3つの根拠があります。
機械学習の予測誤差は、バイアス(系統的な偏り)とバリアンス(予測のばらつき)に分解できます。単独の決定木は深く分岐させると、バイアスは小さい(訓練データへの当てはまりは良い)ものの、バリアンスが大きい(少しデータが変わるだけで予測が大きく変わる)モデルになります。
ランダムフォレストは多様な木の予測を平均することで、各木のバリアンスを相殺し、全体のバリアンスを大きく下げます。これが「過学習に強い」と言われる数学的な根拠です。
ブートストラップサンプリングで各木を作るとき、約36.8%のサンプルは抽出されません。このサンプルをOOB(Out-of-Bag)と呼びます。
OOBサンプルはその木の訓練に使われていないので、その木に対しては「未知のデータ」として機能します。各サンプルについて、それを訓練に使わなかった木だけで予測し、誤差を集計したものがOOB誤差。これは交差検証(クロスバリデーション)に似た役割を果たし、別途検証データを用意しなくても、汎化性能を見積もれるのがランダムフォレストの便利な特徴です。
ランダムフォレストは、「どの特徴量が予測にどれくらい貢献しているか」を数値化できます。これが特徴量重要度(Feature Importance)です。
計算方法には2つの主流があります:
MDI重要度は計算が速いがバイアスがあり、カテゴリ数が多い特徴量や連続値特徴量に重要度が偏る傾向があります。Permutation重要度はその偏りが少ないですが、計算コストが高くなります。実務では、まずMDI重要度で全体感をつかみ、重要そうな特徴量についてPermutation重要度で再確認する流れが定石です。
理屈が分かったら、実装してみましょう。Pythonとscikit-learnを使います(バージョンは1.x想定。最新版でも基本APIは同じ)。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# データ準備(X: 特徴量、y: ターゲット)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# モデル構築
rf = RandomForestClassifier(
n_estimators=100, # 木の数
max_depth=None, # 木の最大深さ(Noneで制限なし)
min_samples_split=2, # 分岐に必要な最小サンプル数
min_samples_leaf=1, # 葉ノードの最小サンプル数
max_features='sqrt', # 各分岐で考慮する特徴量数
oob_score=True, # OOB誤差を計算
random_state=42,
n_jobs=-1 # 並列処理(-1で全コア使用)
)
rf.fit(X_train, y_train)
# 評価
y_pred = rf.predict(X_test)
print(f"テスト精度: {accuracy_score(y_test, y_pred):.4f}")
print(f"OOBスコア: {rf.oob_score_:.4f}")
print(classification_report(y_test, y_pred))たったこれだけで、業界標準クラスの予測モデルが作れます。「線形回帰だと数十%の精度しか出なかったデータが、ランダムフォレストに変えるだけで80%超になる」というのは、よくある経験です。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
rf = RandomForestRegressor(
n_estimators=100,
max_depth=None,
max_features=1.0, # 回帰では全特徴量を使うことも多い(または1/3)
oob_score=True,
random_state=42,
n_jobs=-1
)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"RMSE: {rmse:.4f}")
print(f"R²: {r2_score(y_test, y_pred):.4f}")import pandas as pd
import matplotlib.pyplot as plt
# MDI重要度(不純度減少に基づく重要度)
importances = pd.DataFrame({
'feature': X.columns,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
print(importances.head(10))
# 可視化
plt.figure(figsize=(10, 6))
plt.barh(importances['feature'][:10][::-1], importances['importance'][:10][::-1])
plt.xlabel('Importance')
plt.title('Top 10 Feature Importances')
plt.tight_layout()
plt.show()実務では、ここで得た重要度を見て「思ったより効いていない特徴量を除く」「上位特徴量だけで再学習してみる」といった改善サイクルに入ります。
MDI重要度は高速ですが、連続値やカテゴリ数の多い特徴量を過大評価しやすい弱点があります。重要な意思決定(医療診断や金融与信など)に使う場合は、Permutation重要度でも確認するのがおすすめです。
from sklearn.inspection import permutation_importance
result = permutation_importance(
rf,
X_test,
y_test,
n_repeats=10,
random_state=42,
n_jobs=-1
)
perm_importances = pd.DataFrame({
'feature': X.columns,
'importance_mean': result.importances_mean,
'importance_std': result.importances_std
}).sort_values('importance_mean', ascending=False)
print(perm_importances.head(10))Permutation重要度は「テストデータで該当の列の値をランダムにシャッフルし、予測精度がどれだけ落ちるか」を測ります。値が大きいほど、その特徴量がモデルの精度に貢献している指標です。MDIで上位だった特徴量がPermutationでは振るわない場合、その重要度はカテゴリ数や連続値の影響で過大評価されていた可能性があります。
ここまでの例は X, y がすでに整っている前提でした。しかし実際のデータでは、数値列とカテゴリ列が混在し、欠損値もあり、One-hot Encodingも必要というのが普通です。これを毎回手で処理するのは煩雑な上、訓練データとテストデータで処理がズレる原因にもなります。
scikit-learnの Pipeline と ColumnTransformer を使うと、前処理とモデルをひとつのオブジェクトとしてまとめて管理できます。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
numeric_features = ['age', 'income', 'score']
categorical_features = ['sector', 'region']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median'))
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocess = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
model = Pipeline(steps=[
('preprocess', preprocess),
('rf', RandomForestClassifier(
n_estimators=300,
random_state=42,
n_jobs=-1
))
])
model.fit(X_train, y_train)
predictions = model.predict(X_test)このパターンの強みは3つ。(1) テストデータで前処理がズレない(学習時の中央値・最頻値・カテゴリ集合がそのまま使われる)、(2) GridSearchCVで前処理パラメータも一緒に最適化できる、(3) 一行のmodel.predict()で前処理から予測まで完結する――この3つです。「読んで終わり」ではなく「自分のデータで実用できる」レベルにする鍵は、このPipeline化にあります。
なお、Pipelineを使う場合、特徴量重要度の確認方法が少し変わります。One-hot Encoding でカテゴリ変数が複数列に展開されるため、元の X.columns と feature_importances_ の長さが一致しなくなるからです。Pipeline後は get_feature_names_out() で変換後の特徴量名を取得します。
# Pipeline後の特徴量重要度の取得
feature_names = model.named_steps['preprocess'].get_feature_names_out()
importances = model.named_steps['rf'].feature_importances_
importance_df = pd.DataFrame({
'feature': feature_names,
'importance': importances
}).sort_values('importance', ascending=False)
print(importance_df.head(10))10行くらいで強いモデルが作れちゃうんだ!?
ランダムフォレストには多数のハイパーパラメータがありますが、実際に精度に影響するのは5つくらいです。これだけ覚えれば実用上は十分です。
| パラメータ | 意味 | 推奨初期値 | 調整の方向 |
|---|---|---|---|
n_estimators | 木の数 | 100〜500 | 多いほど安定、500を超えると効果は鈍化。計算コスト増大 |
max_depth | 各木の最大深さ | None(無制限) | 過学習が疑われるなら10〜30に制限 |
min_samples_split | 分岐に必要な最小サンプル数 | 2 | 過学習なら5〜20に上げる |
min_samples_leaf | 葉ノードの最小サンプル数 | 1 | 過学習なら2〜10に上げる |
max_features | 各分岐で考慮する特徴量数 | sqrt(分類)/1.0(回帰) | 多様性が足りなければ減らす、不足なら増やす |
5つを同時に動かすとパラメータ空間が爆発します。実務では次の順で調整するのが効率的です:
n_estimators=100、他はデフォルトで動かして基準性能を測るmax_depthとmin_samples_leafで抑えるmax_featuresを変えて多様性を調整(’sqrt’ / ‘log2’ / 0.3 / 0.5などを試す)n_estimatorsを増やす(500、1000など)。性能向上が頭打ちになる点を見極めるfrom sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 300, 500],
'max_depth': [None, 10, 20],
'min_samples_leaf': [1, 5, 10],
'max_features': ['sqrt', 'log2', 0.5]
}
grid = GridSearchCV(
RandomForestClassifier(random_state=42, n_jobs=-1),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
grid.fit(X_train, y_train)
print(f"最良パラメータ: {grid.best_params_}")
print(f"最良CVスコア: {grid.best_score_:.4f}")注意:上記の探索は3 × 3 × 3 × 3 × 5(CV分割)= 405回の学習になります。データが大きいと数十分〜数時間かかるので、まずはRandomizedSearchCVでランダム探索してから絞り込むのが現実的です。
もう1つの注意点は並列化の二重指定です。上記コードでは GridSearchCV(n_jobs=-1) と RandomForestClassifier(n_jobs=-1) の両方で全コア使用を指定しています。動作はしますが、環境によっては並列処理が重なってCPU使用率が跳ね上がり、かえって遅くなることがあります。重い処理が止まる場合は、GridSearchCVを n_jobs=-1、モデル側を n_jobs=1 にする(またはその逆)と安定します。どちらか一方で並列化するのが原則です。
SimpleImputer による補完が無難predict_proba で出る確率は校正されているとは限らないため、医療判定や金融スコアリングのように確率値そのものを意思決定に使う場合は CalibratedClassifierCV などで校正することを検討「ランダムフォレストが万能なら、線形モデルは不要では?」と思うかもしれませんが、そんなことはありません。線形モデルにはランダムフォレストにない強みがあります。
| 場面 | おすすめ |
|---|---|
| 関係が直線的(線形)と分かっている | 線形回帰/ロジスティック回帰 |
| 係数の意味(「Xが1増えるとYがどれだけ増えるか」)を知りたい | 線形回帰/ロジスティック回帰 |
| 特徴量同士に強い相関がある(多重共線性) | 線形モデル+正則化(Ridge/Lasso) |
| 非線形な関係や交互作用が多そう | ランダムフォレスト |
| とりあえず精度を出したい | ランダムフォレスト |
| 学習データの範囲外を予測したい | 線形モデル |
| 説明責任が問われる業務(金融審査・医療判定) | 線形モデル+必要に応じてランダムフォレストでクロスチェック |
多重共線性の話は、多重共線性の完全ガイドで詳しく扱っています。線形回帰を使うなら必読の論点です。
実務での王道は、「まず線形モデルでベースライン精度を出し、その後ランダムフォレストでどれだけ上振れるかを確認する」流れ。線形モデルとランダムフォレストの精度差が大きければ「データに非線形性が強い」、ほぼ同じなら「線形モデルで十分」と判断できます。
ランダムフォレストは、決算指標から株価動向を予測するファンダメンタル分析の自動化でもよく使われます。例として、こんな問題設定が考えられます。
目的:決算データから「6ヶ月後に市場平均(TOPIX)を上回るリターンを出す銘柄」を分類する。
特徴量の例:
ターゲット:6ヶ月後リターンがTOPIXを上回ったか(1)、下回ったか(0)。
このような問題で、ランダムフォレストは「PERが低い × ROEが高い × 営業利益率が改善傾向」のような交互作用を自動で拾い上げてくれるのが強みです。線形回帰では明示的に交互作用項を作らないと捉えられない関係を、決定木の分岐構造が勝手に表現するためです。
ランダムフォレストを使いこなせるようになったら、次に学ぶべきは勾配ブースティング系(Gradient Boosting)のアルゴリズムです。具体的にはXGBoost、LightGBM、CatBoostの3つ。
ランダムフォレストが「独立に作った木の多数決」だったのに対し、勾配ブースティングは「前の木の間違いを次の木が補正していく」逐次学習型のアンサンブルです。一般に、ランダムフォレストよりさらに高い精度を出せることが多く、Kaggleなどのデータ分析コンペでは長らく主役を担ってきました。
使い分けの目安:
勾配ブースティングについては、XGBoost・勾配ブースティング入門|仕組み・実装・チューニングを初心者向けにやさしく解説で詳しく扱っています。LightGBMとの違いと使い分けはLightGBMとは?で解説しています。
多くの場合、100〜500本で十分です。木を増やしすぎても精度向上は鈍化し、計算コストだけが増えます。OOBスコアや交差検証スコアが頭打ちになる点を実験的に見極めるのが正解です。
不要です。決定木ベースのアルゴリズムは「Xが閾値以上か未満か」で分岐するだけなので、特徴量のスケールに依存しません。線形回帰や距離ベースの手法(k近傍法、SVMなど)と違って、前処理が省けるのは大きな利点です。
scikit-learnのRandomForestは、バージョン1.4以降で欠損値をネイティブに扱えるようになりました。それ以前のバージョンや確実な処理が必要な場合は、SimpleImputerで平均・中央値・最頻値による補完を行うのが定石です。
scikit-learnのRandomForestは数値しか扱えないので、カテゴリ変数は事前に数値化する必要があります。よく使われる方法は、One-hot Encoding(カテゴリ数が少ない場合)または Target Encoding(カテゴリ数が多い場合)。LightGBMやCatBoostはカテゴリ変数をネイティブに扱えるため、カテゴリ変数が多いデータでは有利です。
scikit-learnのRandomForestはメモリと計算時間が大きな課題になります。100万件超のデータではLightGBMやXGBoostへの切り替えを検討してください。これらはランダムフォレスト相当の精度を、数倍〜数十倍速い学習時間で達成できます。
ランダムフォレストは、機械学習を学ぶ上で最も費用対効果の高いアルゴリズムと言ってよいでしょう。最後にこの記事のポイントをおさらいします。
はじめての機械学習プロジェクトでは、「まず線形回帰/ロジスティック回帰でベースラインを作り、ランダムフォレストで上振れを確認し、必要ならXGBoostで詰める」という3段構えで進めるのが、最も安全で効率的な道のりです。
ルミィ:「”1人の天才”じゃなくて”100人の凡人の多数決”が現実解、覚えておくね!」
📚 機械学習入門シリーズ(全6回)
🧭 もっと広い地図で眺める:この手法は機械学習という大きな地図の一部です。教師あり・教師なし・強化学習という全体像や、クラスタリング・PCA・過学習・評価指標といった“使いこなし”は、連載「機械学習の地図」(概念編・全5回)で図解しています。
🧩 仕組みの根っこを知る:ランダムフォレストは「アンサンブル学習」の代表例です。なぜ弱い学習器をたくさん束ねると強くなるのか——その背骨の考え方(バギングとブースティングの違い)は、アンサンブル学習とは?で図解しています。





