

決定木とは?仕組み・ジニ不純度・剪定までやさしく解説【機械学習入門】
ルミィ
AIの歩き方


線形回帰、聞いたことはあるけど、結局なにに使うの?
「線形回帰」と聞いて「あの y = ax + b ね」と即答できる人は多いですが、「で、実際の仕事で何に使うの?」と聞かれると詰まる人が大半です。実は売上予測・価格設定・健康管理まで、ビジネスのあらゆる場面で線形回帰が動いています。
私もね、最初は数学の話だと思ってたけど、家計簿に応用できるって知って距離が縮まったんだ
この記事は、線形回帰分析を「数式の話」ではなく「実務で使える分析手法」として身につけるための初心者向けチュートリアルです。仕組みの直感的理解、Excelでの実装、Pythonでの実装、評価指標の読み方まで順番に解説します。データ分析を本気で始めたい人にとって、最初に押さえるべき1記事です。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
📅 最終更新:2026年6月13日(公開:2025年8月)
✅ 線形回帰分析の基礎から実践までを完全解説
✅ 数学が苦手な人でも理解できる図解中心の構成
✅ ビジネス現場での活用事例も豊富に紹介
✅ よくあるトラブル・エラー対処法も収録
✅ 散布図・残差の図解を追加(2026年6月)
✅ 2026年時点でも使える、線形回帰の基本と実践ポイントを整理
「線形回帰分析って何?」「どうやればいいの?」
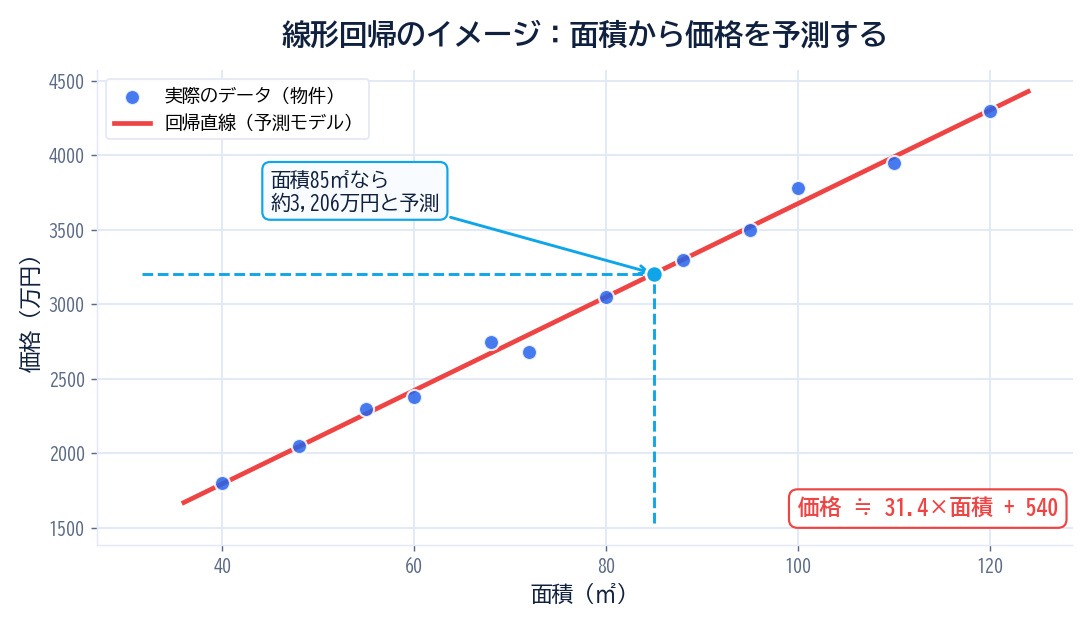
線形回帰は「ある要因と結果の関係」を数値で表す、データ分析の基本中の基本。中学校で習った一次関数の延長で考えられて、Excelの分析ツールでも数クリックで実行できます。AI時代だからこそ、結果を説明できる線形回帰の価値は高まっています。
この記事では、データ分析の基礎である線形回帰分析について、定義から実際のやり方、活用例まで一通り解説します。数学が苦手な方でも、考え方から順番に追えるように、できるだけ具体例を使って説明します。私自身も最初は「a×x + b」の式を見て身構えていましたが、Excelで実データを動かしてみたら「あ、要は要因と結果の関係を1本の直線で表しているだけだ」と腑に落ちました。この記事ではその感覚を共有したいと思っています。
そもそも線形回帰とは、ある値(説明変数)から別の値(目的変数)を予測するための、もっとも基本的な統計・機械学習手法のひとつです。本記事を読み終えると、次のことが理解できるようになります。
「線形回帰分析って難しそう…」って感じたかな?でも安心してね。実は中学校で習った一次関数の延長みたいなもので、一歩ずつ進めれば理解できるよ。この記事では数式よりも「考え方」を中心に解説していくから、初めての人でも置いてけぼりにならない構成にしてあるんだ。
線形回帰分析とは、「ある要因と結果の関係を数値で表す分析手法」です。
もっと簡単に言うと:
こんな疑問に数値で答えるのが線形回帰分析です。
身近な例で理解してみましょう 🏠
住宅価格を考えてみてください:
これらの関係を数式で表したものが線形回帰分析です。
住宅価格 = 面積 × 係数A + 駅距離 × 係数B + 築年数 × 係数C + 定数
実は身の回りの価格って、いろんな要因の積み重ねで決まっているんだ。線形回帰はその「要因と結果の関係」を数値で見える化する手法なんだよ。
基本的な数式はこちら 📐
y = a₁x₁ + a₂x₂ + … + aₙxₙ + b
各項の意味を整理すると:
y:予測したい値(目的変数)🎯x₁, x₂, ...:影響する要因(説明変数)📊a₁, a₂, ...:影響の強さ(回帰係数)⚖️b:基準値(切片)📍数式に苦手意識があっても全然大丈夫。覚える必要はなくて、大事なのは「要因と結果の関係を数値化する」っていう考え方の方だよ。計算はExcelやPythonがやってくれるからね。ビジネスや研究の現場では、ツールが計算した結果を「どう読み取るか」が一番大事。だからこの記事では、結果の見方や解釈方法を丁寧に解説していくよ。
データの点を1本の直線で表すとき、線の引き方は無数に考えられます。そこで使うのが最小二乗法という考え方です。各データ点について「実際の値」と「直線が予測する値」の差を残差と呼び、この残差を二乗して合計した値がいちばん小さくなる直線を選びます。言いかえると、すべての点からの予測のズレが全体として最小になる線が回帰直線です。
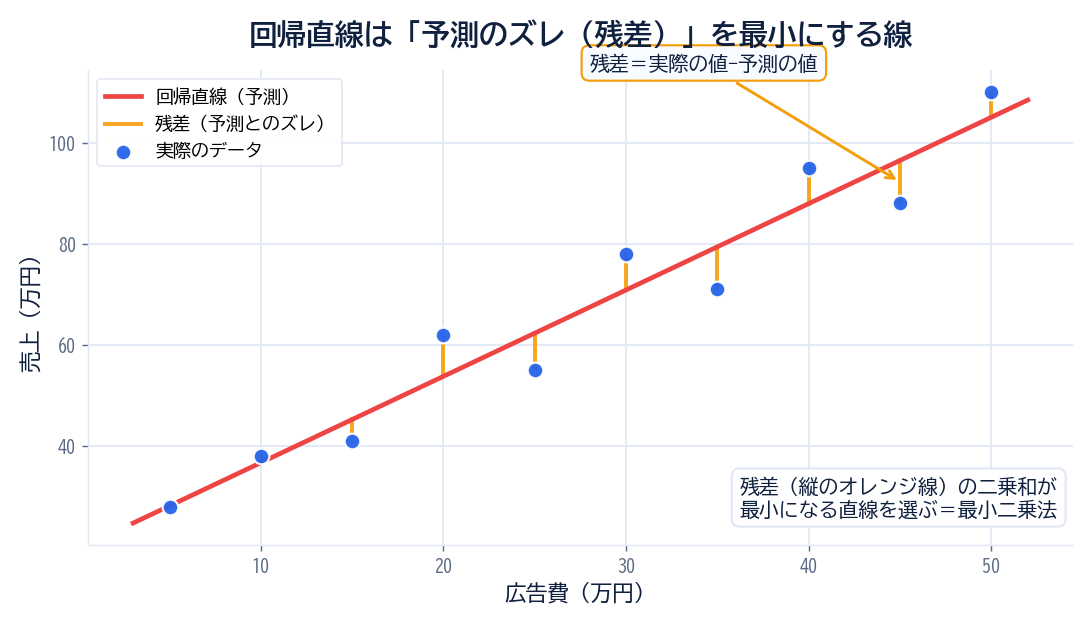
難しい計算はExcelやPythonが自動でやってくれるので、私たちは「残差をいちばん小さくする直線を選んでいる」というイメージだけ持っておけば十分です。
線形回帰分析の特徴を、他の手法と比較してみましょう。
主要な分析手法の比較表 📋
| 手法 | 予測対象 | 解釈性 | 計算速度 | 使用場面 |
|---|---|---|---|---|
| 線形回帰 📊 | 連続値 | ◎高い | ◎高速 | 売上予測、価格推定 |
| ロジスティック回帰 🎯 | 確率・分類 | ○良い | ○速い | 購入予測、合否判定 |
| 決定木 🌳 | 両方可 | ◎高い | ○速い | ルール発見、分類 |
| ランダムフォレスト 🌲 | 両方可 | △普通 | △普通 | 高精度予測 |
| 深層学習 🧠 | 両方可 | ×低い | ×低速 | 画像・音声認識 |
線形回帰分析のメリット:
線形回帰分析が活用されるシーンを見てみましょう。
ビジネスでの活用例:
学術・研究での活用例:
線形回帰は、医療・マーケティング・不動産・スポーツ・気象予測まで、色々な分野で使われているんだ。シンプルだからこそ、応用範囲が広い。「要因と結果の関係を整理したい」場面では、まず線形回帰から始めるのが定番だよ。結果の解釈もしやすいから、最初の一手として向いているんだ。
📘 Excelで実際にやってみたい人はこちら
住宅価格データを使った線形回帰分析の手順を、Excel画面付きで一歩ずつ解説しているよ。理論を学んだ後の実践編としてピッタリ!
👉 Excelでできる!住宅価格データの線形回帰分析入門
いよいよ実際のやり方を学んでいこう!ここでは、誰でもできる具体的な手順を紹介するよ。
線形回帰分析を始める前に準備するものを整理しましょう:
実は線形回帰、Excelで十分実践できるんだ。プログラミング不要で、ボタンをポチポチするだけで本格的な分析ができるから、初心者の最初の挑戦にはピッタリ。まずはExcelで手を動かして基本を掴んでから、必要に応じてPythonやRに進むのがおすすめだよ。
プログラミング不要で実際に試したい方は、住宅価格データを使ったExcel実践記事も参考にしてください。

まず、データの状態を確認しましょう。
確認すべきポイント:
こうやってデータの「おかしなところ」を探して整える作業を 「前処理」 って呼ぶよ。実は分析時間の大半が前処理に使われるって言われるくらい、重要な工程なんだ。
前処理の具体的作業:
✅ 欠損値の対処
- 削除:少数の場合
- 補完:平均値、中央値で埋める
- 分析:欠損パターンに意味がある場合
✅ 外れ値の対処
- 確認:散布図で視覚的にチェック
- 判定:±3σルール、四分位範囲法
- 対応:削除、変換、別途分析
✅ データ形式の統一
- 単位の統一(円、万円、億円など)
- 日付形式の統一
- カテゴリ変数の数値化
データの関係性を可視化して理解しましょう。
基本的な可視化手順:
Excelでの実行方法:
1. データ選択 → 挿入 → グラフ → 散布図
2. データ分析 → 相関 → 変数を選択
3. 結果の解釈:相関係数が±0.7以上なら強い関係
いよいよ線形回帰モデルを作成します。
Excelでの手順:
1. データ分析ツールを有効化
ファイル → オプション → アドイン → 分析ツール
2. 回帰分析の実行
データ → データ分析 → 回帰分析
3. 設定
- Y範囲:目的変数の列を選択
- X範囲:説明変数の列を選択
- 信頼度:95%(デフォルト)
- 残差プロット:チェック
Pythonでの手順:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# データ読み込み
data = pd.read_csv('your_data.csv')
# 変数設定
X = data[['説明変数1', '説明変数2']] # 説明変数
y = data['目的変数'] # 目的変数
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル構築
model = LinearRegression()
model.fit(X_train, y_train)
# 予測
predictions = model.predict(X_test)分析結果をビジネスに活かせる形で理解しましょう。
重要な指標の読み方:
🎯 決定係数(R²)
📊 回帰係数
⚡ p値
作成したモデルが信頼できるかチェックしましょう。
必須の検証項目:
🔍 残差分析
✅ 残差プロットの確認
- ランダムに散らばっている → OK
- パターンがある → モデルに問題
✅ 正規性の確認
- 残差のヒストグラム作成
- 正規分布に近い → OK
📊 予測精度の確認
✅ テストデータでの評価
- 訓練データとテストデータの精度比較
- 大きな差がある → 過学習の可能性
✅ 実際データでの検証
- 可能なら新しいデータで予測精度確認
「検証なんて面倒…」って感じる気持ちはわかる。でも実はこの検証ステップが、分析の信頼性を左右する一番大事な部分なんだ。良いモデルを作るには「検証→修正→再検証」のサイクルを回すのがコツ。一度で完璧を目指さず、少しずつ精度を上げていく感覚で進めると挫折しにくいよ。
メリット:
手順詳細:
1. データ準備
A列:説明変数1(例:広告費)
B列:説明変数2(例:気温)
C列:目的変数(例:売上)
2. 分析実行
データ → データ分析 → 回帰分析
3. 結果確認
- 決定係数をチェック
- 係数の符号をチェック(論理的に正しいか)
- p値をチェック(<0.05が目安)
メリット:
完全なコード例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
# 1. データ読み込み
data = pd.read_csv('sales_data.csv')
print(data.head()) # データ確認
# 2. 前処理
data = data.dropna() # 欠損値削除
X = data[['advertising', 'temperature']]
y = data['sales']
# 3. データ分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 4. モデル構築
model = LinearRegression()
model.fit(X_train, y_train)
# 5. 予測
y_pred = model.predict(X_test)
# 6. 評価
r2 = r2_score(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"決定係数 (R²): {r2:.3f}")
print(f"RMSE: {rmse:.2f}")
# 7. 係数確認
for i, coef in enumerate(model.coef_):
print(f"{X.columns[i]}: {coef:.3f}")
print(f"切片: {model.intercept_:.3f}")
# 8. 可視化
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
plt.xlabel('実際値')
plt.ylabel('予測値')
plt.title('予測精度の確認')
plt.show()※ dropna() は欠損値を含む行を削除する処理です。実務では、削除してよい欠損か、平均値・中央値などで補完すべきかを確認してから使うようにしましょう。
あなたの興味に合わせて、次のステップへ進めます。
理論とやり方を学んだところで、実際のビジネスシーンでどう活用されているかを見てみましょう。以下の事例は、実際の取り組みをもとにした代表的な使い方として整理したイメージ例で、数値は典型的なケースを想定したものです。
🏢 想定:オンライン雑貨ショップ
「来月の売上を予測して在庫管理を改善したい」
使用データと分析結果(架空例):
説明変数:
- 広告費(万円)
- 気温(℃)
- プロモーション実施フラグ(0 or 1)
- 前月売上(万円)
目的変数:売上(万円)
結果:
売上 = 2.3×広告費 + 1.8×気温 + 15×プロモーション + 0.4×前月売上 + 50
決定係数:R² = 0.82
ビジネスインパクトの例:
線形回帰の式って、実はすごくシンプル。「価格 = a × 面積 + b × 部屋数 + …」みたいに、変数の足し算で表現されるだけだから、結果も理解しやすい。ビジネス現場では「説明できないAI」より「解釈できる線形回帰」の方が重宝される場面も多いんだ。意思決定の根拠を示せるのは大きな強みだよ。
🏢 想定:中堅不動産会社
「営業担当者の経験に頼るだけでなく、客観的な価格査定の参考値も欲しい」
使用データと分析結果(架空例):
説明変数:
- 専有面積(㎡)
- 築年数(年)
- 駅距離(分)
- 階数(階)
- 南向きフラグ(0 or 1)
目的変数:成約価格(万円)
結果:
価格 = 8.5×面積 - 12×築年数 - 25×駅距離 + 15×階数 + 180×南向き + 1200
決定係数:R² = 0.89
活用イメージ:
具体的な計算例:
物件例:70㎡、築10年、駅徒歩8分、5階、南向き
計算:
価格 = 8.5×70 - 12×10 - 25×8 + 15×5 + 180×1 + 1200
= 595 - 120 - 200 + 75 + 180 + 1200
= 1,730万円
🏭 想定:食品メーカー
「製造条件と品質の関係を明確にして、不良品率を下げたい」
使用データと分析結果(架空例):
説明変数:
- 温度(℃)
- 湿度(%)
- 混合時間(分)
- 原料ロット(カテゴリ変数)
目的変数:品質スコア(0-100点)
結果:
品質 = -0.8×温度 + 0.3×湿度 + 2.1×混合時間 + ロット係数 + 定数
決定係数:R² = 0.75
活用イメージ:
🚕 想定:地方タクシー会社
「効率的な配車で売上を伸ばしつつ、待機時間も減らしたい」
使用データと分析結果(架空例):
説明変数:
- 時間帯(0-23時)
- 曜日(1-7)
- 天気(晴れ=1, 雨=2, 雪=3)
- イベント開催フラグ(0 or 1)
- 前週同時刻の需要
目的変数:1時間あたりの配車依頼数
結果:
需要 = 時間帯係数 + 曜日係数 + 1.5×天気 + 8×イベント + 0.6×前週需要
決定係数:R² = 0.71
活用イメージ:
「決定係数R²が0.7以上って高いの?」って気になるよね。ビジネスデータで0.7以上が出れば一定の手応えがあると言われるけど、良い数値は分野によって変わるよ。重要なのは「完璧な予測」じゃなくて「現状より良い意思決定ができるか」。R²が低くても、判断材料として価値があるなら十分意味があるんだ。
これらの活用パターンに共通する要素を整理してみましょう:
実際に線形回帰分析を行う際によく遭遇する質問や問題について、具体的な解決策をご紹介します。
答え:分野によって大きく異なります。以下は一般的な目安です。
分野別の目安表 📊
以下はあくまでざっくりした目安です。データの質、予測対象、目的、検証方法によって評価は大きく変わります。
| 分野 | 良好とされる範囲(目安) | 理由 |
|---|---|---|
| 物理・工学 🔧 | 0.9以上 | 制御された環境、少ない変数 |
| 経済・金融 💰 | 0.3-0.7 | 市場ノイズや外部要因が大きく、R²だけで実用性は判断しにくい |
| マーケティング 📈 | 0.5-0.8 | 人間行動、ブランド要因など |
| 医学・生物学 🧬 | 0.4-0.7 | 個体差、未知の要因が多い |
| 社会科学 👥 | 0.2-0.5 | 人間行動、文化的要因など |
重要なポイント:
「R²が0.3って低すぎ?使えない?」って思うかもしれないけど、実はそうとも言い切れないんだ。例えば株価予測みたいに「予測が当たる確率がちょっと上がるだけで意味がある」分野では、R²が低くても価値があることも。「統計的に意味があるか(p値)」「実務でどう使うか」も合わせて考えることが大事だよ。
答え:サンプル数との関係で決まります。
初心者向けの目安:
✅ 安全寄りの目安:説明変数1つあたり10〜20件以上のサンプル
例:5変数なら50〜100行以上のデータがあると安心
✅ 最低限の目安:説明変数1つあたり5〜10件以上のサンプル
(これを下回ると、係数が不安定になりやすい)
✅ いずれの場合も、「意味のある変数だけ」を厳選するのがコツ
変数が多すぎる場合の対処法:
答え:ダミー変数化して数値に変換します。
具体例:天気データの処理
元データ:
天気 | 売上
-----|-----
晴れ | 100
雨 | 80
曇り | 90
変換後:
晴れフラグ | 雨フラグ | 売上
---------|--------|----
1 | 0 | 100
0 | 1 | 80
0 | 0 | 90
注意点:
IF関数、Pythonならpd.get_dummies()で変換症状: 係数が大きく変動する、標準誤差が異常に大きい
原因: 説明変数同士が強く相関している
診断方法:
# Pythonでの診断
from statsmodels.stats.outliers_influence import variance_inflation_factor
# VIF計算
vif_data = pd.DataFrame()
vif_data["Variable"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif_data)
# VIFが5〜10を超えるなら多重共線性の可能性あり
対処法:
症状: 残差プロットにパターンが見える(ランダムでない)
原因: 線形性の仮定が満たされていない
対処法:
症状: 一部のデータポイントがモデルを大きく歪める
診断方法:
# 外れ値の検出
from scipy import stats
z_scores = np.abs(stats.zscore(data))
outliers = data[z_scores > 3] # ±3σ を超える値対処法:
1. 特徴量エンジニアリング
# 交互作用項の作成
data['広告費×気温'] = data['広告費'] * data['気温']
# 比率変数の作成
data['売上率'] = data['売上'] / data['前年売上']
# 時系列特徴量
data['月'] = data['日付'].dt.month
data['曜日'] = data['日付'].dt.dayofweek2. データ変換
# 対数変換(右に裾の長い分布に有効)
data['log_売上'] = np.log(data['売上'])
# 標準化(スケールの違う変数混在時)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)3. 交差検証
from sklearn.model_selection import cross_val_score
# 5-fold交差検証
scores = cross_val_score(model, X, y, cv=5, scoring='r2')
print(f"平均R²: {scores.mean():.3f} ± {scores.std():.3f}")
1. 係数の標準化
# 標準化回帰係数(重要度比較に有効)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model_scaled = LinearRegression()
model_scaled.fit(X_scaled, y)
# 標準化係数 = 変数の重要度
print("変数重要度:", model_scaled.coef_)
2. 信頼区間の計算
import statsmodels.api as sm
# 詳細な統計情報付きモデル
X_with_const = sm.add_constant(X)
model_stats = sm.OLS(y, X_with_const).fit()
print(model_stats.summary())
# 係数の信頼区間
print(model_stats.conf_int())エラーがたくさん出ると心が折れそうになるよね。でも大丈夫、最初は誰でもそう。エラーは「ここを直してね」っていう親切な案内文みたいなもの。一度に全部直そうとせず、一つずつ解決していくこと。そして「完璧なモデルはこの世に存在しない」と知っておくこと。「現状より良い」を目標にすると気が楽になるよ。
線形回帰分析は、説明変数と目的変数の関係を数値で表す、データ分析の基本となる手法です。売上予測、価格推定、広告効果の分析、品質管理など、さまざまな場面で使われます。
大切なのは、数式を丸暗記することではありません。「どの要因が結果にどれくらい影響しているのか」を考え、結果をどう読み取るかです。最初はExcelで十分です。散布図を作り、回帰直線を引き、決定係数R²や回帰係数を見ながら、データの関係を確認してみましょう。慣れてきたら、重回帰分析、Pythonでの実装、ロジスティック回帰、決定木などに進むと、機械学習の理解にもつながります。
線形回帰はシンプルですが、データ分析の考え方を学ぶうえで重要な入口です。
ChatGPTやClaudeのようなAIツールが普及した今、線形回帰のような基本手法をわざわざ学ぶ必要はあるのでしょうか。この疑問はとても自然です。ここでは、AI時代における線形回帰の位置づけを整理しておきます。
1. ビジネス現場の現実 🏢
実際の企業では:
- 複雑なAIモデルは「なぜそう予測したか」の説明が難しい
- 線形回帰なら「広告費1万円→売上2.3万円増」と明確
- 意思決定者は「説明できる根拠」を求める場面が多い2. AIだけでは難しい場面 🛡️
ChatGPT等の汎用AIが扱いにくい領域:
- 自社固有のデータ分析
- 継続的なモデル運用・更新
- 法的責任が伴う意思決定の根拠提示3. AIを使いこなすための基礎知識 🧠
線形回帰の知識があると:
- AIの出力が妥当かを判断しやすい
- 「このデータなら線形回帰で十分」という判断ができる
- AIに的確な指示を出しやすくなる逆に、データ分析が業務に関わる人、意思決定に関わる立場の人、AI関連の仕事をしていきたい人にとっては、線形回帰は学んでおく価値の高い基礎知識です。
「AI時代に線形回帰なんてもう必要ないんじゃ?」って思うかもしれないけど、実は逆。AIが普及した今こそ、結果を理解して説明できる線形回帰の価値が見直されているんだ。「AIに使われる人」より「AIを使いこなす人」になりたいなら、基礎知識は心強い味方になるよ。
今日からできる最初の一歩:
1. Excelに自分の業務に近い数値データ(売上・コスト・時間など)を10〜30行用意する
2. 散布図で「これとこれは関係ありそう」という変数の組み合わせを探す
3. データ分析ツール → 回帰分析 を実行し、R²と係数の符号だけまず確認してみる
🚀 次のステップに進みたい人へ
「基礎は分かった、次は何を学べばいい?」という人向けの定番書。Excelをそのまま使って機械学習の代表的な手法を体験できるから、Python移行前の橋渡しとしても役立つよ。
📈 回帰と並ぶ“予測”のもう一つの柱:売上や来客数のように時間で変化するデータの先を読む時系列予測(連載・全3回)も、データ分析の必須スキルです。回帰とあわせて押さえておきましょう。
📊 回帰の“土台”を固める:回帰分析やデータ分析を“意味が分かって”使うには、統計の基礎が効いてきます。標準偏差・正規分布・相関・仮説検定を、連載「統計のきほん」(全4回)で数式少なめに図解しています。





