

ヒストグラムとは?作り方と見方・棒グラフとの違いをやさしく図解
ルミィ
AIの歩き方


決定係数 R²、見たことあるけど、結局どこまで高ければOK?って迷うよね
回帰分析の出力で必ず出てくる R²(決定係数)。「高いほど良い」と覚えている人は多いですが、「0.8以上ならOK」「0.5でも分野によっては優秀」など、判断基準は分野や用途で大きく異なります。
私もね、最初は『R² = 0.7 で大丈夫?』って毎回不安になってたんだ
この記事は、決定係数 R² の正しい読み方を、初心者向けに丁寧に解説するガイドです。R² の定義、調整済み R² との違い、業界別の目安、過学習との関係、R² が高くてもダメな例、補完すべき他の指標(MSE・MAE・AIC)まで網羅。回帰分析の結果を自信を持って解釈したい全ての人向けです。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
📅 最終更新:2026年6月13日(図解を追加)
✅ 数式が苦手な人でもわかる図解中心の解説
✅ 分野別の「良いR²の目安」一覧表付き
✅ 補正R²との違いも完全カバー
✅ よくある誤解・落とし穴も収録
✅ FAQで疑問を一気に解消
決定係数R²は「モデルがデータのばらつきをどれくらい説明できるか」を示す指標。ただし、良い数値の基準は分野によってまったく違います。R²=0.2でも優秀なモデルがあれば、R²=0.9でも過学習の疑いがある場合もあります。
「決定係数R²ってよく聞くけど、結局何を表してるの?」「いくつあれば良いの?」
回帰分析を学んでいると必ず出会う「決定係数R²」。実はこの数値、線形回帰モデルがデータのばらつきをどれくらい説明できているかを見る代表的な指標なんだ。でも分野によって「良い基準」が違ったり、補正R²との使い分けが難しかったりして、初心者がつまずきやすいポイントでもあるよ。私自身も最初は「R²=0.7って良いの悪いの?」と迷った経験があるので、その悩みをまとめてほぐしていくよ。
この記事では、決定係数R²の意味から見方、分野別の目安、補正R²との違い、よくある誤解まで一気に解説していくよ。読み終わるころには、回帰分析の結果を自信を持って解釈できるようになっているはず!
📘 そもそも線形回帰って何?という人はこちら
R²は線形回帰の精度を表す指標。回帰分析全体の流れと一緒に理解すると、R²の意味がぐっと腹落ちするよ。
👉 線形回帰分析とは?やり方から活用法まで徹底解説
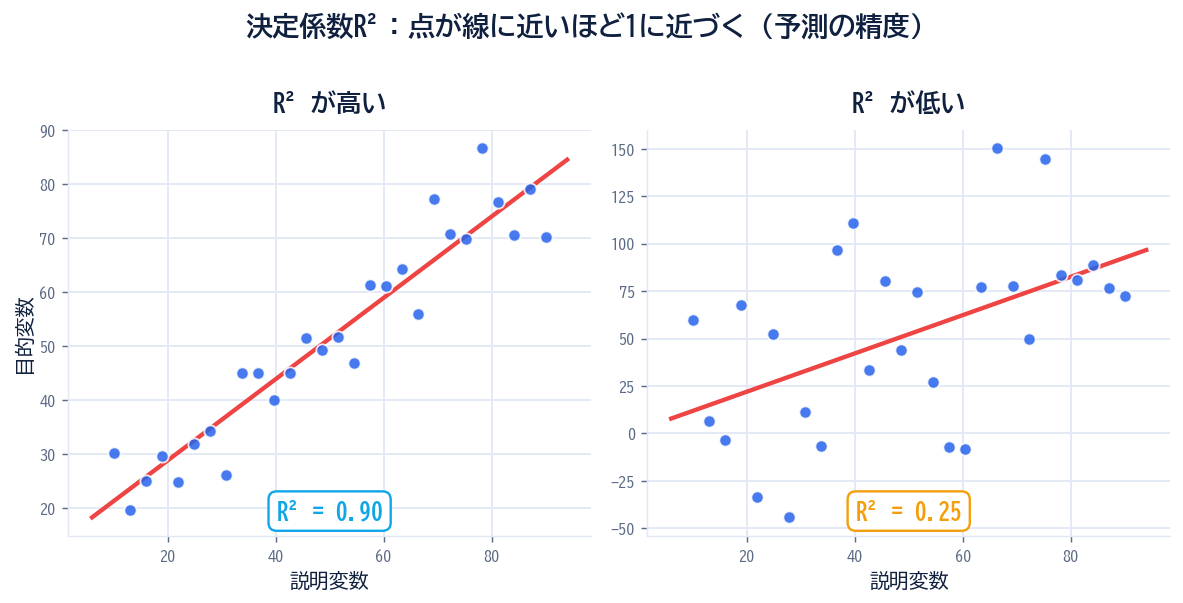
決定係数R²は、回帰モデルが目的変数のばらつきをどれくらい説明できているかを示す指標だよ。
R²=0.75 だったら、「このモデルはデータのばらつきの75%を説明できている」って意味だよ。残りの25%は、モデルに含まれていない他の要因で動いている部分、と考えるとイメージしやすいかも。
数式で書くとこんな感じだけど、覚える必要はないよ。
R² = 1 - (残差の二乗和) / (全変動の二乗和)
= 1 - SSres / SStot
意味:
- SSres:モデルで説明できなかったばらつき
- SStot:データ全体のばらつき
- R²:説明できたばらつきの割合要するに「全体のばらつきのうち、モデルで説明できた部分の割合」ってこと。直感的にわかりやすいよね。
「R²はいくつあれば良いの?」という質問の答えは、分野によって全然違うんだ。以下はあくまでざっくりした目安で、実際にはデータの種類・予測期間・ノイズの大きさ・目的によって評価は変わるよ。
| 分野 | 良好な範囲 | 理由 |
|---|---|---|
| 物理・工学 | 0.9 以上 | 法則性が明確で、ノイズが少ないため |
| 化学・生物 | 0.8 以上 | 実験データで再現性が高い |
| ビジネス・経済 | 0.5 〜 0.7 | 多くの外部要因が関わるため |
| マーケティング | 0.4 〜 0.6 | 消費者行動のばらつきが大きい |
| 株価・金融 | 低めになりやすい | 市場ノイズや外部要因が大きく、R²だけで実用性は判断しにくい |
| 社会科学・人間行動 | 0.2 〜 0.4 | 複雑な要因が絡むため |
金融分野ではR²が低く出ることも多いけど、それだけで良し悪しは判断できないよ。予測期間、取引コスト、リスク管理、テストデータでの成績まで合わせて見るのが大事なんだ。
実はそうとは限らないんだ。R²が極端に高い(0.95以上など)場合は、過学習の可能性があるよ。
「R²=0.99だ!完璧!」って喜んでいたら、テストデータでR²=0.4だった、なんてことも普通に起きるよ。
これも違う場合がある。例えば株価予測でR²=0.2でも、その予測精度で十分利益が出ることもあるんだ。重要なのは:
R²の数値だけ見て「ダメなモデル」と決めつけるのはもったいないよ。実は「現状より少し当たる」だけで、ビジネスに大きなインパクトが出る場面はたくさんあるんだ。
R²が示すのは「相関」と「予測精度」だけ。因果関係(原因→結果の関係)は示さないよ。
補正R²(adjusted R²)は、変数の数を考慮して調整した決定係数だよ。
補正R² = 1 - (1 - R²) × (n - 1) / (n - k - 1)
n:サンプル数
k:説明変数の数普通のR²には、「変数を増やすほど機械的に上がる」という欠点があるんだ。
補正R²は変数の数にペナルティを課すから、意味のある変数だけ残しているかを判断できるんだ。
| シーン | 使う指標 |
|---|---|
| 単回帰分析(変数1つ) | R² |
| 重回帰分析(変数複数) | 補正R² |
| 変数選択の判断 | 補正R² |
| モデル間の比較 | 補正R² |
変数が複数あるなら、普通のR²だけでなく補正R²も必ず見よう。さらに、テストデータでのR²、RMSE、MAE、残差プロットも合わせて確認すると安心だよ。
📈 重回帰分析でのR²の扱いはこちら
説明変数が複数の重回帰では、補正R²の方が重要。重回帰分析の実践記事と一緒に読むと理解が深まるよ。
👉 Excelでできる!重回帰分析の使い方
複数のモデル(変数の組み合わせを変えたもの)を作ったとき、どれが一番良いかを比較するのに使えるよ。
変数を1つ追加して補正R²が大きく上がるなら有用、変わらないか下がるなら不要、と判断できるよ。
「このモデルはR²=0.78で、ビジネス指標を78%説明できます」のように、説得力のある根拠として使えるよ。
=RSQ(目的変数の範囲, 説明変数の範囲)
例:=RSQ(B2:B100, A2:A100)単回帰の場合のみ使える簡易な方法だよ。
🐍 PythonでR²を算出してみたい人はこちら
scikit-learnで線形回帰を実装する方法を解説。R²もコード1行で計算できるよ。
👉 Pythonで線形回帰分析をやってみよう【scikit-learn入門】
回帰分析の結果を見たら、R²について以下をチェックしよう。
📊 実際にR²を見てみたい人はこちら
住宅価格データを使ったExcel実践記事。本記事で学んだR²の知識を、実データで体感できるよ。
👉 Excelでできる!住宅価格データの線形回帰分析入門
分野次第だよ。物理学なら低すぎ、ビジネスなら平均的、株価予測なら優秀、というふうに評価が変わるんだ。「分野の常識的水準と比べてどうか」が判断基準だよ。
単回帰の場合、R² = r² の関係にあるよ。例えば相関係数 r=0.8 なら、R² = 0.64 になるんだ。重回帰では「重相関R」という別の値になるけど、関係性は似ているよ。
テストデータでの評価では起こり得るよ。「平均値で予測するより悪い」状態を意味するから、モデルがデータに対して全く機能していない、つまり特徴量の見直しが必要だよ。
テストデータのR²を信じよう。訓練データは「答えを見ながら勉強した結果」、テストデータは「初見の問題で解いた結果」みたいなもの。実用上の精度はテストデータの方が正直だよ。
補正R²は変数の数にペナルティを課すため、通常のR²以下になります。R²と補正R²の差が大きい場合は、変数を入れすぎていないか、不要な変数が混ざっていないかを確認しましょう。差が気になるときは、変数を一つずつ外してみて補正R²がどう変わるか確認するのがコツだよ。
決定係数R²は、回帰モデルの精度を判断する重要な指標のひとつ。でも数値だけで判断せず、文脈と一緒に解釈するのが正解だよ。
今回押さえたポイント:
今すぐ試せる次の一歩:
1. 手元のデータで回帰分析を実行して、R²と補正R²の両方を確認する
2. 異なる変数セットでモデルを2〜3個作り、補正R²で比較する
3. 訓練データとテストデータに分けて、R²の差が大きくないか確認する
R²のことが分かってくると、回帰分析の結果が立体的に見えてくるよ。次のステップに進みたい人には、下の本がおすすめ。Excelをそのまま使って、機械学習の評価指標を実例ベースで理解できる定番書なんだ。Pythonに進む前のステップとしてもバッチリだよ。
🚀 評価指標を使いこなしたい人へ
Excelで機械学習を体験できる定番書。R²をはじめとした評価指標を実データで腹落ちさせたい人にぴったりの1冊だよ。
📊 関連:決定係数R²は、単回帰では相関係数を二乗した値に一致します。その大もとの考え方は相関とは?相関係数と「相関≠因果」で図解しています。





