ノーコードで始めるAIデータ分析|初心者向け5ツール比較【2026年版】
ルミィ
AIの歩き方

Python で機械学習、始めたいけど、最初の1コードでつまずきがちじゃない?
Python で線形回帰を実装するなら scikit-learn が定番ですが、「import の書き方」「学習データの準備」「fit と predict の流れ」を一度経験しないと、なかなか身につきません。エラーで止まる人が多い、最初の壁です。
私もね、最初の scikit-learn コードで5回くらいエラー出して、心が折れかけたんだ
この記事は、Python + scikit-learn で線形回帰を実装するハンズオンチュートリアルです。環境構築、データ準備、学習、予測、評価指標(R²・MSE・MAE)、可視化まで、コードを1行ずつ丁寧に解説します。Python で機械学習を本気で始めたい初心者にとって、最初の壁を越えるための実践ガイドです。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
📅 最終更新:2026年4月26日(新規公開)
✅ Python 3.11以上 / scikit-learn 1.4以上を想定(基本のfit/predictの流れは最新版でも同じです)
✅ コピペで動くサンプルコード掲載
✅ Google Colab / Jupyter Notebook対応
✅ 実データを使った演習形式
✅ モデル評価・可視化まで完全カバー
scikit-learnの線形回帰は「import → fit → predict」の3ステップ。コードは10行以下で完成します。Excelで基礎がわかっていれば、Pythonへの移行は思ったより簡単です。
「線形回帰、Excelでは試したけど次はPythonでやってみたい」「scikit-learnって難しそう…」
そう思っている人、安心してください。実はscikit-learnでの線形回帰は、たった数行のコードで実装できるほどシンプルです。Excelで基礎が分かっていれば、Pythonへの移行はそれほど難しくありません。私自身、最初は「scikit-learnって何から始めればいいの?」と戸惑いましたが、fit/predictの流れを一度覚えると、他のモデルにも同じ感覚で進めました。
この記事では「Pythonで線形回帰をやってみたい」人向けに、scikit-learnを使った実装手順を一歩ずつ解説していくよ。コードもコピペで動くから、読みながら手を動かしてみてね!
📘 線形回帰の基礎をおさらいしたい人はこちら
そもそも線形回帰って何?という疑問から、実世界での活用事例まで丁寧に解説しているよ。Pythonに進む前のおさらいに最適!
👉 線形回帰分析とは?やり方から活用法まで徹底解説
Excelは「探索的に試してみる」場面では便利だけど、本格的な分析や繰り返し実行が必要になるとPythonに軍配が上がるよ。両方を使い分けられるようになると、データ分析の選択肢がグッと広がるんだ。
scikit-learn(サイキット・ラーン)は、Pythonで機械学習を扱う際の業界標準ライブラリだよ。
「インストールが面倒…」って人には、Googleが提供するGoogle Colabが断然おすすめだよ。ブラウザでアクセスするだけで、Pythonと必要なライブラリが全部入った環境がすぐ使えるんだ。
ブラウザで「Google Colab」と検索 → 新規ノートブックを作成、で準備完了。
初めてPythonに触る人は、迷わずGoogle Colabがおすすめ!環境構築でつまずくのが学習の最大の壁だから、それを丸ごとスキップできるのは大きなメリットだよ。
自分のPCで動かしたい人は、以下のいずれかでOK。
ここからは実際にコードを動かしていくよ。コピペで動くようになっているから、自分の環境で試しながら読み進めてね!
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_scoreそれぞれの役割:
まずは小さな例で動作確認してみよう。
# サンプルデータ:勉強時間と試験点数の関係
data = {
'勉強時間': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'点数': [50, 55, 65, 70, 75, 80, 82, 88, 90, 95]
}
df = pd.DataFrame(data)
print(df)もちろん、自分のCSVファイルを読み込むこともできるよ。
# CSVファイルから読み込む場合
df = pd.read_csv('your_data.csv')
df.head()X = df[['勉強時間']] # 説明変数(2次元にするためダブル[[]])
y = df['点数'] # 目的変数ここで X はダブル角括弧、y はシングル角括弧で囲むのがポイント。Xは「複数列を入れることがある」前提で2次元配列にする必要があるんだ。これを忘れるとエラーになるから注意してね!
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)test_size=0.2 で「データの20%をテスト用に分ける」という意味。random_state=42 はデータの分け方を毎回同じにするための設定で、数値は42でなくても構いません。
上記の10行データは、コードの流れを理解するためのミニサンプルです。テストデータが2行しかないためR²やMSEの値は参考程度に留め、本格的な評価は実際のデータで行ってください。
# モデルを作成
model = LinearRegression()
# 訓練データで学習
model.fit(X_train, y_train)
print('係数(傾き):', model.coef_)
print('切片:', model.intercept_)たった3行で線形回帰の学習が完了!scikit-learnのfit()メソッドが、内部で最適な係数を計算してくれるんだ。
# テストデータで予測
y_pred = model.predict(X_test)
# 結果を比較
results = pd.DataFrame({
'実測値': y_test,
'予測値': y_pred
})
print(results)# 平均二乗誤差(MSE)
mse = mean_squared_error(y_test, y_pred)
print('MSE:', mse)
# 決定係数(R²)
r2 = r2_score(y_test, y_pred)
print('R²:', r2)ここまでで基本実装はOK!「Pythonで機械学習って意外と簡単じゃん」って感じたかな?R²の意味や「良い値の基準」は分野によって違うから、気になった人は決定係数R²の解説記事もチェックしてみてね。
説明変数を増やせば、そのまま重回帰分析になるよ。コードはほぼ同じで、Xの列を増やすだけ。
# 重回帰用のサンプルデータ(3つの説明変数を含む)
data_multi = {
'勉強時間': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'出席率': [60, 65, 70, 75, 80, 85, 88, 90, 95, 98],
'前回点数': [45, 50, 58, 62, 70, 72, 78, 80, 85, 90],
'点数': [50, 55, 65, 70, 75, 80, 82, 88, 90, 95]
}
df_multi = pd.DataFrame(data_multi)
X = df_multi[['勉強時間', '出席率', '前回点数']] # 3つの変数
y = df_multi['点数']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
# 各変数の係数を表示
for name, coef in zip(X.columns, model.coef_):
print(f'{name}: {coef:.2f}')
print('切片:', model.intercept_)Pythonの強みはここから!変数を10個でも100個でも、同じコードでサッと処理できるんだ。Excelだとデータ範囲を選び直す必要があるけど、Pythonなら列名のリストを変えるだけで済むよ。
📈 Excelで重回帰分析を試したい人はこちら
複数の説明変数を扱う重回帰分析を、Excelで体験できる解説記事。Pythonに進む前のステップとしてもおすすめだよ。
👉 Excelでできる!重回帰分析の使い方
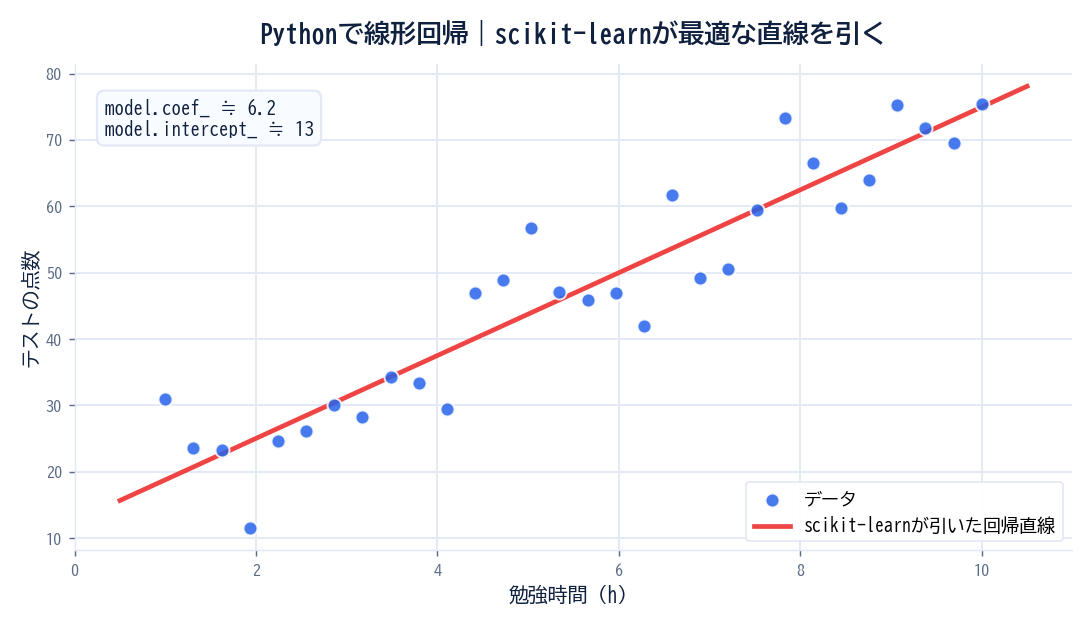
matplotlibを使えば、予測結果の可視化も簡単にできるよ。
import matplotlib.pyplot as plt
import numpy as np
# 散布図(実測値)
plt.scatter(X_test, y_test, label='実測値', color='blue')
# 回帰直線:X全体のmin〜maxで滑らかなラインを作る
x_line = np.linspace(X['勉強時間'].min(), X['勉強時間'].max(), 100).reshape(-1, 1)
x_line_df = pd.DataFrame(x_line, columns=['勉強時間'])
y_line = model.predict(x_line_df)
plt.plot(x_line, y_line, label='回帰直線', color='red')
plt.xlabel('勉強時間')
plt.ylabel('点数')
plt.title('線形回帰の予測結果')
plt.legend()
plt.show()np.linspace でXの最小値〜最大値の間に均等な100点を作り、回帰直線を滑らかに描いているよ。train_test_split後のX_testは順番がバラバラなため、そのままplt.plot()すると直線がガタガタに見えることがあるんだ。
Xとyの行数が一致していないときに出るエラー。データを確認して、両方の長さを揃えよう。
Xを df['col'](シングル角括弧)で渡すと出るエラー。df[['col']](ダブル角括弧)か X.values.reshape(-1, 1) を使おう。
カテゴリ変数(文字列)が含まれているとき。pd.get_dummies() でダミー変数化してから渡そう。
# カテゴリ変数のダミー化
X = pd.get_dummies(df[['性別', '学年']], drop_first=True)drop_first=True は、ダミー変数の列を1つ減らして重複した情報を避けるための設定です(多重共線性の対策)。
df.dropna() で欠損値を削除df.fillna(df.mean()) で平均値補完scikit-learnなら、これらすべてが 同じ fit/predict のお作法で扱えるよ。線形回帰のコードを書ければ、他のモデルにもすぐ移行できるんだ。
📊 Excelで実践した経験がある人はこちら
住宅価格データを使ったExcelでの実践記事。Pythonに移行する前にExcelで基礎を固めたい人におすすめ!
👉 Excelでできる!住宅価格データの線形回帰分析入門
ステップ別に説明してきたコードを、一つにまとめたバージョンを置いておくよ。まずはこれをColabにコピペして、動く感覚をつかんでみてね。
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# サンプルデータ
data = {
'勉強時間': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'点数': [50, 55, 65, 70, 75, 80, 82, 88, 90, 95]
}
df = pd.DataFrame(data)
# 変数を分ける
X = df[['勉強時間']]
y = df['点数']
# 訓練・テスト分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
print('係数:', model.coef_[0])
print('切片:', model.intercept_)
print('MSE:', mean_squared_error(y_test, y_pred))
print('R²:', r2_score(y_test, y_pred))
# または: print('R²:', model.score(X_test, y_test))最後の行で使った model.score(X_test, y_test) も、R²を返す便利なscikit-learn組み込みの方法だよ。
「1回限りの分析」ならExcelで十分。でも「同じ分析を毎月実行したい」「数万行以上のデータを扱う」「他の機械学習手法にも発展させたい」場合はPythonが有利だよ。両方使い分けるのがベストだね。
Python基本文法(変数・リスト・関数)と、pandasの基本操作が分かれば十分実装できるよ。むしろ「線形回帰をやりたい」という具体的な目的があると、Python学習が一気に進むからおすすめ!
初心者ならGoogle Colab(インストール不要)が始めやすいです。慣れてきたらJupyter Notebook(対話的)かVS Code(本格開発)に移行するのがおすすめだよ。
動かないわけじゃないけど、信頼性が低くなるよ。最低でも30行、理想的には説明変数の数×10倍以上のサンプル数があると安心。少ないデータでは交差検証(cross_val_score)を使うのも手だよ。
過学習を抑えたいだけならRidge、不要な変数を自動で削除したいならLassoが目安。両方の良いとこ取りがElasticNet。データの状況に応じて試行錯誤するのが一般的だよ。
読めるよ。pd.read_excel('file.xlsx') でExcelファイルを直接読み込めるんだ。Excel→Python→分析→結果をExcelに書き戻す、みたいな流れも可能だよ。
Pythonとscikit-learnを使えば、たった数行のコードで線形回帰が実装できるよ。
今回学んだこと:
今すぐ試せる次の一歩:
1. Google Colabを開いてこの記事のコードをコピペで動かしてみる
2. サンプルデータを自分のCSVに差し替えて、同じ流れで実行する
3. 変数を1つ増やして重回帰に拡張し、係数の変化を確認する
お疲れさま!Pythonでの線形回帰、ここまで来れば自分のデータで色々試せるはず。「次はどんな手法を学べばいい?」って迷ったら、下の本が良いガイドになるよ。Excelで体験する形式だから、Pythonの背景知識を補強するのにぴったりなんだ。
🚀 機械学習の世界をもっと知りたい人へ
線形回帰の先にある手法を、Excelで直感的に学べる定番書。Pythonでコードを書く前に概念を整理したい人にもおすすめだよ。