

主成分分析(PCA)とは?次元削減で情報を大事な軸に圧縮する仕組みを解説
ルミィ
AIの歩き方

📅 最終更新:2026年5月10日(公開:2025年8月)
✅ Excel 2024 / Microsoft 365で動作確認済み
✅ プログラミング不要・30分〜1時間で実践しやすい構成
✅ サンプルCSVデータ無料配布
✅ 重回帰分析への発展編・FAQも収録

Excel だけで本格的なデータ分析ができるって、知ってた?
「データ分析は Python じゃないとできない」と思い込んでいる人が多いですが、実は Excel の「分析ツール」アドインを使えば、線形回帰・重回帰・分散分析まで本格的にできます。Pythonの環境構築でつまずく前に、まずExcelから始めるのが最短ルートです。
私もね、最初に Excel で回帰やってから Python に移ると、すごく理解が早かったんだ
この記事は、Excelの「分析ツール」を使って、住宅価格データで線形回帰を実装するハンズオン記事です。データ準備、回帰の実行、出力結果の読み方、決定係数・p値・回帰係数の解釈まで丁寧に解説します。データ分析の最初の一歩を、Excel という馴染みのあるツールで踏み出したい人向けの実践チュートリアルです。
この記事は「機械学習入門」シリーズの1本です。AIの全体像から知りたい方はAIの地図|目的別にAIツールを探せる一覧ガイド【2026年】、分析手法を順番に学びたい方はデータ分析・機械学習カテゴリもあわせてご覧ください。
Excelの「分析ツール」を使って、住宅価格データから「面積・部屋数・築年数・駅距離・階数」がどう価格に効くかを線形回帰で分析する手順を、画面付きで解説します。サンプルCSVデータも無料配布。プログラミング不要で、結果のR²・回帰係数・P値の読み方まで一通り押さえられます。
この記事では、Excelを使って住宅価格データの線形回帰分析を行う手順を、初心者向けに解説します。
「線形回帰分析って難しそう…」と思っていませんか?
実は、お馴染みのExcelを使えば、プログラミングの知識がなくても本格的な統計分析ができます。今回は、住宅価格データを使って、面積や部屋数などの条件が価格にどう影響するかを分析してみましょう。私自身も最初は「統計分析=Pythonを書ける人だけのもの」と思い込んでいましたが、Excelで実際に動かしてみたら、回帰係数とP値を見ながらデータと対話するという感覚が一番つかみやすかったです。最初の一歩はExcelで十分です。
線形回帰分析とは、「ある要因と結果の関係」を数値で表す統計手法です。
例えば:
こういった関係性を、データから客観的に読み取ることができます。
「線形」って聞くと「直線で大丈夫なの?」って思うよね。不動産価格は本来かなり複雑だけど、まずは線形回帰で大まかな傾向をつかむのが分かりやすいんだ。必要に応じて、変数を増やしたり、非線形モデルに進んだりすれば大丈夫。シンプルだけど、ビジネスの現場でよく使われている手法だよ。
📚 線形回帰の理論的な背景や、Excel以外のツール(Python、Rなど)でのやり方をもっと深く知りたい人は、こちらの記事も参考にしてみてください。
👉 線形回帰分析とは?やり方から活用法まで徹底解説
なお、この記事では説明変数を5つ使うため、正確には線形回帰の中でも「重回帰分析」を行います。線形回帰は大きなカテゴリで、説明変数が1つなら単回帰、2つ以上なら重回帰と呼びます。手順自体は単回帰でも重回帰でも同じなので、ここでは「線形回帰分析」とまとめて扱います。
今回使用するのは、架空の住宅価格データです。以下の項目が含まれています:
| 列名 | 説明 |
|---|---|
area_sqm | 専有面積(㎡) |
rooms | 部屋数 |
age_years | 築年数 |
station_distance_min | 最寄り駅からの距離(分) |
floor | 階数 |
price_million_yen | 価格(万円)← 目的変数Y、これを予測したい |
今回はCSV形式のサンプルデータを用意したよ。下のリンクからダウンロードして、一緒に手を動かしながら進めてみてね。ダウンロードしたら、まずはどんなデータか中身をざっくり眺めてみよう。全体像をつかんでから分析に入ると、結果の解釈がぐっと楽になるよ。
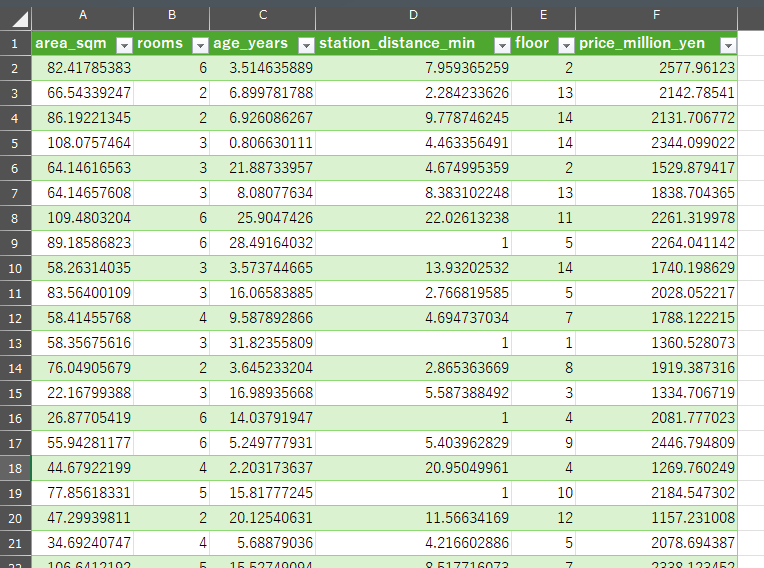
下の表は最小・最大・平均・中央値をまとめたものだよ。例えば部屋数なら、最小1部屋、最大6部屋、平均3.54部屋、中央値3部屋って感じ。こうやって統計の基本指標を見ると、データの偏りがすぐに分かるんだ。
| 変数名 | 最小値 | 最大値 | 平均 | 中央値 |
|---|---|---|---|---|
| area_sqm | 20.658006 | 149.085423 | 84.813023 | 86.711287 |
| rooms | 1.000000 | 6.000000 | 3.534000 | 3.000000 |
| age_years | 0.011876 | 49.967675 | 25.937612 | 26.498170 |
| station_distance_min | 1.009643 | 29.868934 | 15.197620 | 15.179237 |
| floor | 1.000000 | 14.000000 | 7.462000 | 7.000000 |
| price_million_yen | 506.648657 | 2989.904066 | 1749.926 | 1733.422 |
まずは、ExcelにCSVデータを読み込みましょう。そのままCSVを開いてもいいのですが、文字化けすることがあるので、今回はExcelのデータタブから開きます。
まずは、PC内でインストールされているExcelを開いてください。
リボンのデータタブ内にある「テキストまたはCSVから」を選択して、対象のファイルを選んで「インポート」を押してください。
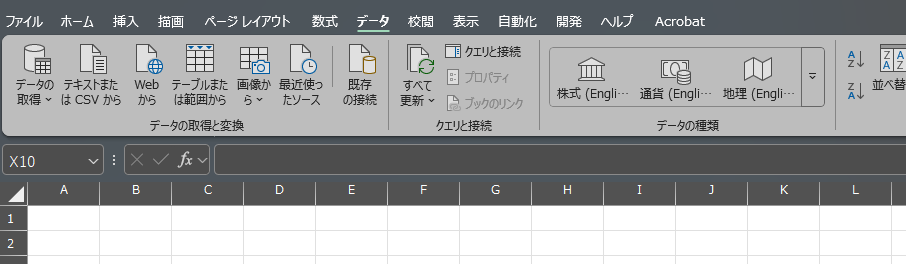
今回はそのまま読み込めそうなので「読み込み」を押して、データを反映させます。
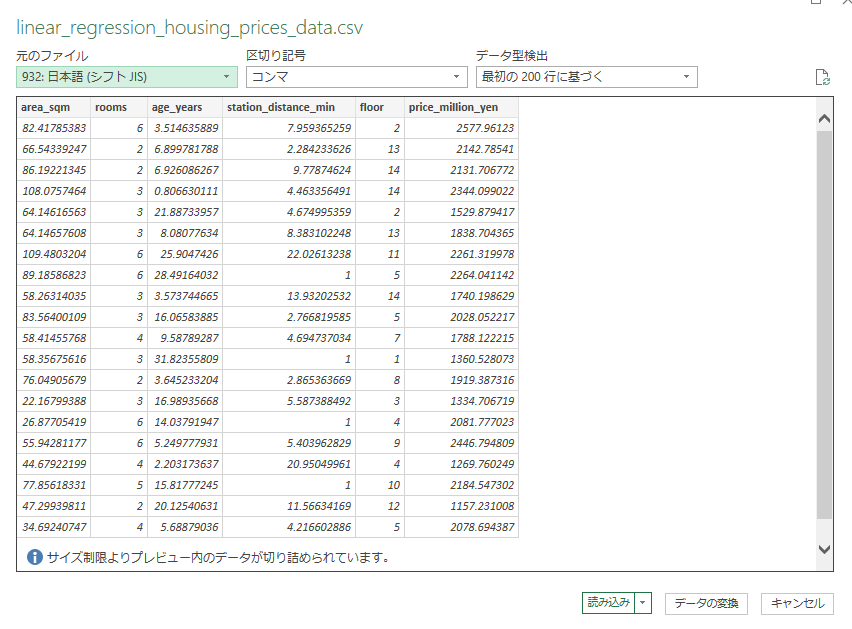
※バージョンによって使えなかったり、方法が違う場合があります。
※また、1行目に項目名(ヘッダー)があることを確認してください。
Excelの「分析ツール」は初期状態では無効になっています。以下の手順で有効化しましょう。
Excelを開いた状態で左上にある「ファイル」を押します。すると画面が変わり、保存や印刷などのメニューが左に出てきます。一番下に「オプション」があるので、こちらをクリックしてください。

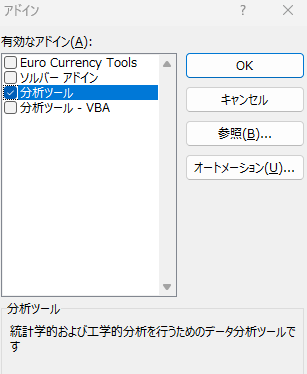
オプション内には数式やデータなど色々ありますが、下のほうに「アドイン」があります。アドイン内の下部にある「管理」欄を「Excelアドイン」にして「設定(G)…」をクリックしてください。
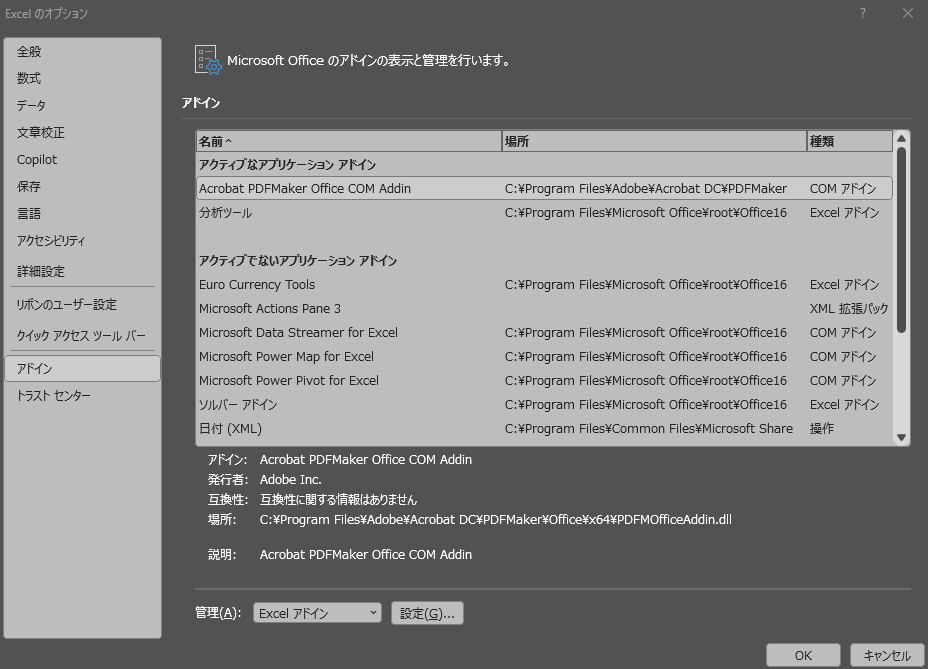
設定内では有効なアドインを選択できます。ここで、「分析ツール」を選んでチェックを入れてください。「OK」をクリックすると選択が反映されます。
トップ画面に戻り、データタブ内の右側に「データ分析」のボタンが反映されていれば設定完了です。
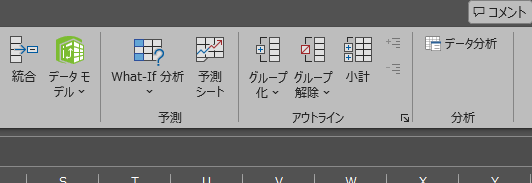
すると、「データ」タブに「データ分析」ボタンが追加されます。
ちょっと注意ポイント!Microsoft 365やExcel for Macだと、分析ツールの場所が少し違うことがあるんだ。バージョンによっては「分析ツール – VBA」も一緒にチェックを入れておくと安心だよ。
いよいよ分析開始です。
回帰分析を選択状態にして「OK」をクリックします。
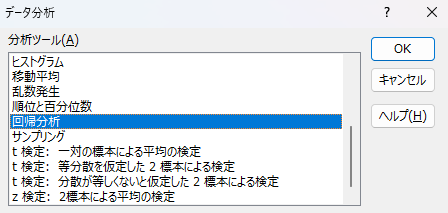
すると、回帰分析用の入力欄として次のような画面が出てきます。
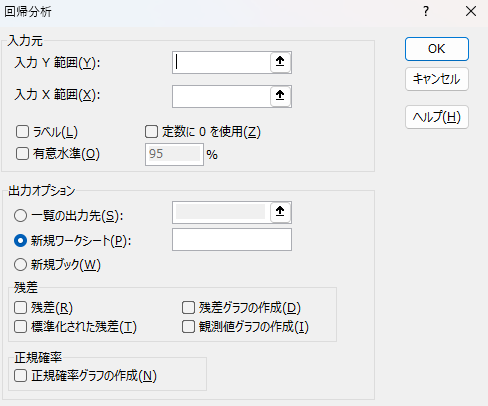
ここでは大きく分けて4つ、さらに詳細な入力欄に分かれています。
$F$1:$F$501(目的変数:価格)$A$1:$E$501(説明変数:面積、部屋数、築年数、駅距離、階数)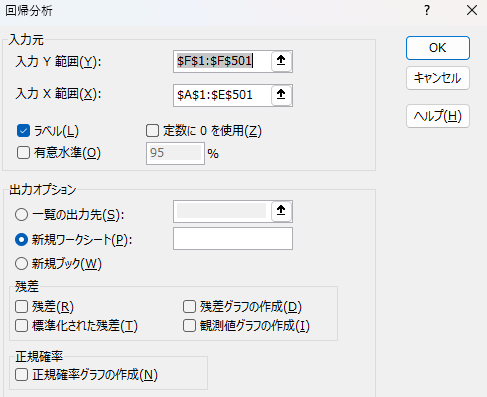
基本的にはチェック不要ですが、知っておくと便利なオプション:
分析が完了すると、新しいシートに結果が表示されます。重要なポイントを見ていきましょう。
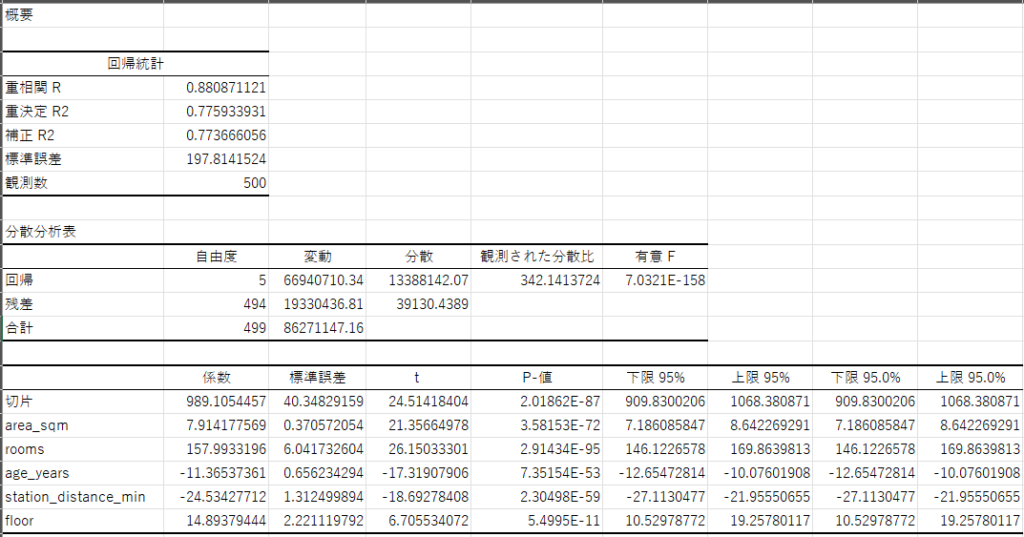
■ 回帰統計
| 指標 | 値 |
|---|---|
| 重相関 R | 0.8809 |
| 重決定 R² | 0.7759 |
| 補正 R² | 0.7737 |
| 標準誤差 | 197.81 |
| 観測数(n) | 500 |
■ 分散分析(ANOVA)
| 分類 | 自由度 | 変動 | 分散 | F値 | 有意確率(P値) |
|---|---|---|---|---|---|
| 回帰 | 5 | 66,940,710.34 | 13,388,142.07 | 342.14 | 7.03 × 10⁻¹⁵⁸ |
| 残差 | 494 | 19,330,436.81 | 39,130.44 | ||
| 合計 | 499 | 86,271,147.16 |
まずはざっくり:各変数が価格にどう効いているか
| 変数 | 係数 | 意味 |
|---|---|---|
| 面積 | +7.91 | 1㎡広いと価格が上がる傾向 |
| 部屋数 | +157.99 | 1部屋多いと価格が上がる傾向 |
| 築年数 | -11.37 | 1年古いと価格が下がる傾向 |
| 駅距離 | -24.53 | 駅から遠いほど価格が下がる傾向 |
| 階数 | +14.89 | 階数が高いほど価格が上がる傾向 |
もう少し細かい統計量(標準誤差・P値・信頼区間)が知りたい方は、下の表もあわせて確認してみてください。
■ 回帰係数と統計量
| 説明変数 | 係数 | 標準誤差 | t値 | P値 | 95%信頼区間(下限) | 95%信頼区間(上限) |
|---|---|---|---|---|---|---|
| 切片(定数) | 989.11 | 40.35 | 24.51 | 2.02 × 10⁻⁸⁷ | 909.83 | 1068.38 |
| area_sqm(面積) | 7.91 | 0.37 | 21.36 | 3.58 × 10⁻⁷² | 7.19 | 8.64 |
| rooms(部屋数) | 157.99 | 6.04 | 26.15 | 2.91 × 10⁻⁹⁵ | 146.12 | 169.86 |
| age_years(築年数) | -11.37 | 0.66 | -17.32 | 7.35 × 10⁻⁵³ | -12.65 | -10.08 |
| station_distance_min(駅距離) | -24.53 | 1.31 | -18.69 | 2.30 × 10⁻⁵⁹ | -27.11 | -21.96 |
| floor(階数) | 14.89 | 2.22 | 6.71 | 5.50 × 10⁻¹¹ | 10.53 | 19.26 |
主要な数値の見方:
「決定係数77.6%って高いの?低いの?」って気になるよね。ビジネスデータでは0.7〜0.8前後なら一定の手応えがあると言われるけど、良い数値の目安は分野によって変わるんだ。逆にR²が1.0に近すぎる場合は「データを覚えただけ」の過学習を疑った方がいいよ。今回の結果は、住宅価格の主な変動要因が説明変数で説明できている状態と考えていいね。
各変数が価格に与える影響:
| 変数 | 係数 | 意味 | P値 |
|---|---|---|---|
| 面積 | +の数値 | 1㎡増えると価格上昇 | < 0.05 |
| 部屋数 | +の数値 | 1部屋増えると価格上昇 | < 0.05 |
| 築年数 | -の数値 | 1年古いと価格下落 | < 0.05 |
| 駅距離 | -の数値 | 駅から1分遠いと価格下落 | < 0.05 |
| 階数 | +の数値 | 1階高いと価格上昇 | < 0.05 |
P値が0.05未満なら、その変数と価格の関係は「統計的に有意」(偶然では説明しにくい)と判断できます。
「P値ってよく聞くけど何?」ってなるよね。簡単に言うと、「本当は関係がない」と仮定したときに、今回のような結果がどれくらい起こりにくいかを見る指標だよ。だから小さいほど「偶然では説明しにくい関係がある」と判断するんだ。一般的には0.05(5%)未満を一つの目安にするよ。今回はP値がかなり小さいので、このデータ上では価格との関係が確認しやすい状態と言えるね。ただし、係数の大きさを読むときは、多重共線性や外れ値、モデルに入れていない要因にも注意しよう。
今回の分析結果から分かったこと:
これらは直感的にも納得できる結果ですね。
平均価格が約1,700万円のデータで、ばらつきの目安が±200万円。「これくらいの精度で予測できれば一般的な傾向把握には使える」って判断の目安だね。今回はあえて前処理をしてないから、外れ値に近いデータも混ざっているかも。そういうイレギュラーを除いたり、変数を増やして重回帰にしたりすると、さらに当てはまりを上げることもできるよ。
この分析結果を使って:
⚠️ 不動産投資・売買判断への利用について:線形回帰は「過去データから見えた傾向」を示すものであり、将来の価格を保証するものではありません。立地の細かい条件、市場動向、金利、災害リスク、個別の物件状態など、モデルに含まれない要因が多くあります。実際の売買・投資判断は、不動産鑑定士、宅地建物取引士、税理士、ファイナンシャルプランナーなど、有資格の専門家のアドバイスとあわせて行ってください。本記事は分析手法の学習を目的とした内容です。
「これで不動産投資で儲けられる!」って思っちゃうかもしれないけど、ちょっと待ってね。あくまでこれは「傾向」を示すもので、立地の細かい条件、市場の変化、経済情勢など、モデルに含まれない要因もたくさんあるよ。判断材料の一つとして、慎重に活用してね。
不動産や物件選びにデータ分析を活かしたいなら、Excelで使える分析手法をもう少し広く押さえておくと選択肢が広がるよ。下の本は、線形回帰だけじゃなくて他の機械学習手法もExcelで試せる内容になっているから、実務に応用しやすいんだ。
ここまでは「面積から価格を予測する」という単回帰分析(変数1つ)的な見方を中心に説明してきました。実務では、もっと多くの要因を組み合わせて分析の精度を上げる「重回帰分析」がよく使われます。なお、今回の例は最初から複数変数を入れているので、実際には重回帰分析を実行しています。
単回帰:価格 = a × 面積 + b
重回帰:価格 = a × 面積 + b × 部屋数 + c × 築年数 + d × 駅距離 + e
Excelでも分析ツールで全く同じ手順で実行可能。「入力X範囲」に複数列を選択するだけで重回帰分析になります。重回帰の詳しい手順はExcelでできる!重回帰分析の使い方もあわせてどうぞ。
1. 不動産査定の参考データ作成
不動産仲介業者が物件査定をする際、過去の取引事例から重回帰分析で「相場感の参考値」を算出する手法が使われることがあります。Excelだけでも、町丁目単位の取引データがあれば自社用の参考モデルを試作できます。
2. 価格交渉の参考材料
売主・買主どちらの立場でも、複数の類似物件データから重回帰モデルを作ると「この物件はモデル予測より◯◯万円高い/安い」と数値で示せます。感覚だけでなく、データに基づく参考情報として使えます。
3. 賃貸物件の家賃設定の検討
家賃 = a × 面積 + b × 駅距離 + c × 築年数 + d × 階数 + e のような式で、所有物件の相場感のある家賃を検討する材料になります。
4. 投資検討時の客観化
不動産投資では「立地が良いから」「築浅だから」と感覚で判断しがちですが、重回帰分析を使うと「このエリアの平均より◯%割安・割高」と数値化できます。複数候補を客観的に比較する補助材料として有効です(最終判断は専門家のアドバイスを併用してください)。
① 多重共線性(マルチコ)に注意
面積と部屋数のように、強く相関する変数同士を同時に入れると、係数が不安定になる現象が起きます。VIF値が5〜10を超えたら注意した方が良いとされます。詳しくは多重共線性とは?を参照してください。
② サンプル数の目安
重回帰では「説明変数1つあたり10〜20件以上のサンプル」が安全寄りの目安です。変数5つなら最低50件、できれば100件以上のデータを集めましょう。
③ 標準偏回帰係数で重要度を比較
変数によって単位が違う(面積は㎡、駅距離は分)ため、係数の大きさだけでは重要度を比較できません。「標準偏回帰係数」を見ることで「どの要因が比較的効いているか」を比較しやすくなります。
データ量が数百〜数万件で、報告書やプレゼンに使う「分析」ならExcelで十分です。一方、数十万件以上のデータを扱ったり、定期的に自動実行したい場合、または複数の手法を組み合わせたい場合はPythonが向いています。最初はExcelで原理を体感して、必要になったらPythonに移るのが王道のステップアップです。
分野やデータの種類によって基準は大きく異なります。物理・工学のように制御された環境では0.9以上が求められる一方、経済・社会・行動データでは0.3〜0.5でも有用な場合があります。あくまでざっくりした目安として、ビジネスデータでは0.6〜0.8前後なら一定の当てはまりがあると見ることもありますが、絶対的な基準ではなく、目的・データの質・検証方法によって判断が変わります。R²の意味と読み方は決定係数R²とは?でも詳しく解説しています。
「統計的に意味がある関係とは言い切れない」というだけで、絶対に使えないわけではありません。サンプル数が少ない場合や、業務上重要だと考えている変数なら、P値が0.1程度でも参考情報として残すこともあります。ただし論文や正式な報告書では0.05が一つの基準になります。
はい。線形回帰分析は売上予測、広告効果測定、需要予測、品質管理、医療データ分析など、幅広い分野で使われています。「ある数値を別の数値で予測したい・関係を見たい」という場面では、まず線形回帰を試すのが一つの定番アプローチです。
線形回帰の中で、説明変数(予測に使う変数)が1つのものを「単回帰」、2つ以上のものを「重回帰」と呼びます。どちらも「直線的な関係を見つける」という意味で線形回帰の一種です。実務では重回帰の方がよく使われます。
線形回帰では、説明変数1つあたり10〜20件以上のサンプルが安全寄りの目安です。例えば変数3つなら30〜60件以上、変数5つなら50〜100件以上が望ましいとされます。データが少ないと「たまたま当てはまった」だけの可能性が高くなり、新しいデータには使えない(汎化性能が低い)モデルになりやすいので注意しましょう。
Excelの分析ツールを使えば、プログラミングを使わなくても線形回帰分析を実践できます。今回の住宅価格データでは、面積、部屋数、築年数、駅距離、階数といった要因と価格との関係を、数値で確認しました。
重要なのは、Excelの出力結果をそのまま眺めることではありません。決定係数R²、回帰係数、P値を見ながら、「どの要因が価格にどう関係しているのか」を読み取ることです。
まずはサンプルデータで流れをつかみ、慣れてきたら自分の業務データや公開データでも試してみましょう。次のステップとして、重回帰分析、決定係数R²、多重共線性、Pythonでの実装に進むと、データ分析の理解がさらに深まります。
今日からできる最初の一歩:
1. 上のサンプルCSVをダウンロードして、ExcelでCSVから開いてみる
2. 「データ」→「データ分析」→「回帰分析」で、Y範囲=価格、X範囲=5つの説明変数を指定して実行
3. 出力されたR²・係数・P値を、本記事の表と見比べながら自分で1度読み解いてみる
Excelで基礎をつかんだら、次はもっと色んな手法に挑戦したくない?この本は、Excelをそのまま使って機械学習の代表的な手法を体験できる構成だから、PythonやRに進む前のステップとしてもちょうどいいんだ。次の一手に迷ってる人にはピッタリだよ。
🚀 次のステップに進みたい人へ
「Excelで基礎は分かった、でも次は何を学べばいい?」という人に。線形回帰の先にある分析手法をExcelで体験できるから、Python移行前の橋渡しとしても役立つ1冊です。
まずはサンプルデータで操作に慣れたうえで、自分の業務データや公開データでも試してみてください。
📈 同じExcelで“未来予測”も:回帰で「項目どうしの関係」を読んだら、次は「時間の流れ」から先を読む番です。Excelの移動平均・指数平滑・予測シートでできるExcelで時系列予測もどうぞ。





