AI開発は1つのAIに丸投げしない|複数AIを組み合わせる進め方
ルミィ
AIの歩き方

「AIに会社の資料を読ませて答えさせたい」「自分のメモを覚えてくれたらいいのに」——そう思ったことはありませんか。NotebookLMに資料を読み込ませたり、Claudeのプロジェクトにファイルを置いたりしたとき、裏側で動いているのが今回のテーマ、RAG(ラグ)です。
RAGは Retrieval-Augmented Generation(検索拡張生成) の略。一言でいうと、質問のたびに、手元の資料から関連する部分を探し出して、AIに渡してから答えさせる仕組みです。
この記事では、RAGがなぜ必要なのか、仕組みの4ステップ、ファインチューニングとの違い、そして身近なRAGの例までをやさしく整理します。

「AIに資料を読ませる」のほとんどはRAG。仕組みが分かると、AIの答えの精度も上げやすくなるよ。
ChatGPTやClaudeのようなAIは、学習した時点までの一般知識しか持っていません。つまり、そのままでは次のものを知りません。
「じゃあ資料を全部貼り付ければ?」と思いますが、資料が増えると全部は渡しきれませんし、毎回全部読ませるのは無駄が多い。そこで、「質問に関係する部分だけを、その都度探して渡す」という発想が生まれました。これがRAGです。
RAGの中身は、準備2ステップ+回答2ステップに分けると分かりやすいです。
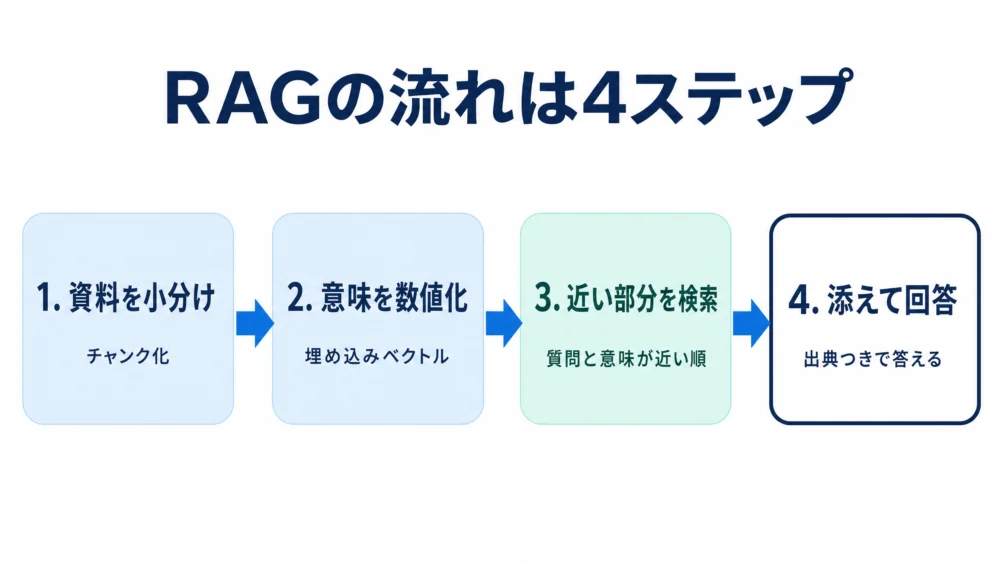
②の埋め込み(エンベディング)は、文章に「意味の地図上の住所」を割り振る技術です。「猫の餌やり」と「キャットフードの量」は言葉こそ違いますが、意味の地図では近所に置かれます。だから、キーワードが一致しなくても「意味が近い」資料を探せる——これがRAGの検索がただの文字検索と違うところです。
RAGは「AIを賢くする魔法」ではなく、「AIに正しいカンペを渡す仕組み」です。カンペの整理が、答えの質を決めます。
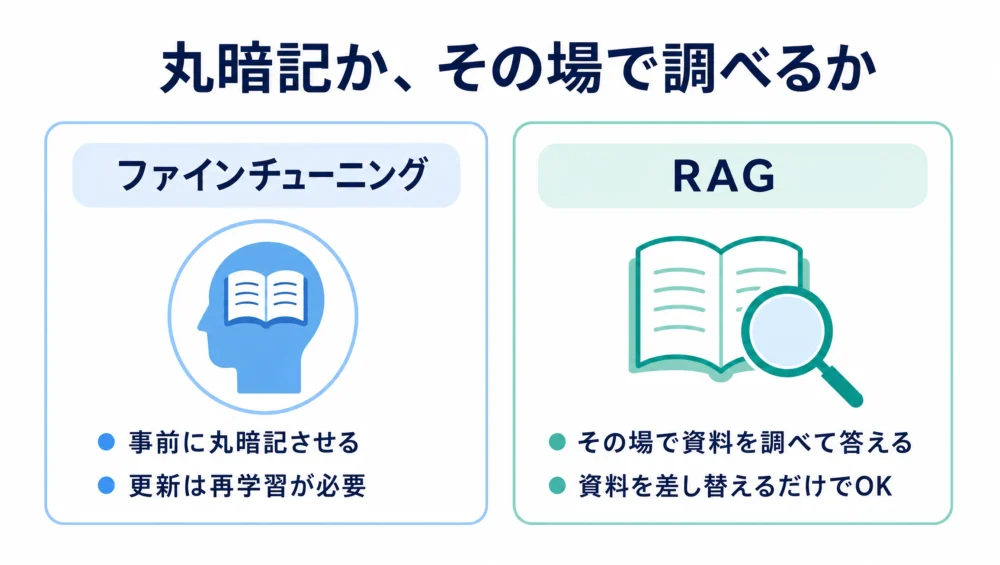
「AIに知識を足す」方法としてよく並ぶのが、ファインチューニング(追加学習)です。違いはシンプルです。
| ファインチューニング | RAG | |
|---|---|---|
| イメージ | 事前に丸暗記させる | その場で資料を調べて答える |
| 知識の更新 | 再学習が必要で大変 | 資料を差し替えるだけ |
| 出典の提示 | 難しい | 得意(どの資料か示せる) |
| 向いている用途 | 口調・形式・専門の型を覚えさせる | 事実・社内知識に基づいて答えさせる |
「プロンプトで渡す・RAG・ファインチューニングをどう使い分けるか」は、2026年のLLM活用設計で詳しく整理しています。
「RAGを入れたのに、思ったほど賢くない」——これは導入した人がほぼ必ず通る道です。原因の多くは仕組みではなく「探す」工程の質にあります。効く順に3つ挙げます。
資料を機械的に「500文字ずつ」のように切ると、表の途中や説明の途中で分断されて、検索に引っかかっても文脈が欠けた断片が渡ります。見出し単位・段落単位など、人間が読んでも意味が通る単位で切るのが基本です。NotebookLMのような既製サービスはここを自動でやってくれますが、資料側の構造(見出しがちゃんと付いているか)が良いほど精度も上がります。
意味検索(ベクトル検索)は言い換えに強い一方、型番・固有名詞・条文番号のような「完全一致してほしい言葉」を取りこぼすことがあります。実務のRAGでは、キーワード検索と意味検索を併用するハイブリッド検索が定番です。既製サービスを使う場合も、「質問に固有名詞をそのまま入れる」だけで検索の精度はかなり変わります。
RAGの答えには出典が付きます。答えだけ読んで満足せず、出典側を1クリックして原文を見る——この習慣があるだけで、読み違い・古い資料の参照にすぐ気づけます。
RAGは万能ではなく、質問のタイプによって得意・不得意がはっきりしています。ここを知っておくと、「RAGがダメ」なのか「question の出し方が悪い」のかを切り分けられます。
| 質問のタイプ | 相性 | 理由 |
|---|---|---|
| 「○○の手順は?」(資料のどこかに答えがある) | ◎ | 該当箇所を探して答える、まさに本領 |
| 「この規程で△△は可能?」(根拠の参照) | ◎ | 出典つきで答えられる |
| 「資料全体を要約して」 | ○ | 対応するサービスが多いが、長大な資料は粗くなりがち |
| 「全文書を横断して件数を集計して」 | △ | 検索は「探す」のが仕事で、全件の集計は苦手 |
| 「資料にない新しい企画を考えて」 | × | 創作はRAGの担当外。通常のAIに聞く方がよい |
コツは、「資料のどこかに答えが書いてある質問」に絞ること。それ以外は普通のAIとして聞き分ける——この切り替えができると、RAGの満足度は一気に上がります。
いきなりステップ3から始めると挫折しやすいので、1→2→3の順がおすすめです。多くの人はステップ2まででも十分に元が取れます。
まず体験したい人は、NotebookLMの使い方から触ってみるのが近道です。どのAIがPDF読解に強いかはPDFを読ませるならどれ?で比較しています。
NotebookLMで「出典つきで答えてくれた!」と感動したアレ、裏側はRAGの考え方なんだよ。
ここまで読んで「それって社内検索と何が違うの?」と思った方へ。違いは返ってくるものの形です。
つまりRAGは「検索の置き換え」ではなく、検索の上に“読んで要約して答える”工程を足したもの。だからこそ、土台の検索が外れると答えも外れる——前の章の「探すの質がすべて」という話につながるわけです。
仕組みを理解した人が、それでも踏みがちな失敗を3つだけ。どれも技術ではなく運用の問題です。
まとめると、RAGの運用は「資料の手入れ」がすべてです。仕組みが立派でも、本棚が散らかっていれば良い答えは返ってきません。
RAG(検索拡張生成)は、質問のたびに資料から関連部分を探してAIに渡す仕組みです。資料を小分けにし、意味を数値化して保存し、質問に近い部分を検索し、添えて答えさせる——この4ステップがすべての基本です。
AIの「知らない」を、検索で補う。
出典を示せて、資料の差し替えも簡単。
ただし答えの質は「資料の整理」で決まる。
「AIに自分の知識を持たせたい」と思ったら、まずファインチューニングではなくRAG的な方法(NotebookLMやプロジェクト機能)から。それがいまの現実的な順番です。
A. Retrieval-Augmented Generation(リトリーバル・オーグメンテッド・ジェネレーション)の略で、日本語では「検索拡張生成」と訳されます。検索(Retrieval)で資料を探し、それを添えて生成(Generation)する仕組みです。
A. 事実や社内知識に基づいて答えさせたいならRAG、口調や出力の型を覚えさせたいならファインチューニングが目安です。知識の追加・更新のしやすさと出典の提示では、RAGが有利です。
A. できます。NotebookLMに資料を読み込ませる、Claudeのプロジェクトにファイルを置く、といった機能がRAG的な仕組みで動いています。
A. いいえ。検索が適切な資料を見つけられなければ答えも外れますし、資料の読み違いも起こりえます。元資料の整理と、重要な判断では原文確認をセットにするのが安全です。
A. 長い資料を検索しやすくするために分割した「かたまり」のことです。段落や見出し単位など、意味が通る単位で切るほど検索の精度が上がります。
A. 文章の「意味」を数値化したもの(埋め込みベクトル)を保存し、意味が近い順に探せるようにした専用のデータベースです。RAGの「検索」を高速に行うための裏方で、NotebookLMのような既製サービスでは意識する必要はありません。
※本記事は2026年6月時点の公開情報をもとに整理しています。各サービスの機能・仕様は変わることがあるため、最新情報は公式サイトでご確認ください。






