
Claude Codeの使い方|ターミナルで動くAI開発エージェントを初心者向けに解説
ルミィ
AIの歩き方

「Claude CodeとCodexを両方使っているけれど、毎回〈今回はどっちを使う?〉で迷ってしまう」――そんな状態でこのページを開いた方も多いのではないでしょうか。
📍 この記事は、Claude Code・Codex・Obsidianを「別々に育てる」のをやめて、1つの知識基盤に統合する手順をまとめたものです。各ツールそのものの比較から入りたい方は AIコーディング比較|Cursor・Codex・Claude Code・GitHub Copilot をどうぞ。
この記事の関連ハブ
Claude CodeとCodexを両方使っていると、毎回「今回はどっちを使う?」で迷います。でも、ある程度使い込むと、この問いだけでは足りなくなります。
本当に効くのは、どちらを選ぶかではなく、両方が同じ知識・同じルール・同じスキルを参照できる状態を作ることです。スキルもナレッジも設定も1か所に集めて、Claude CodeとCodexが同じ実体を読みに行く。これだけで片方で覚えた知見がそのままもう片方で使えるようになって、ツール選定の悩みがだいぶ小さくなります。
この発想の元ネタは、Andrej Karpathyが2026年4月に公開した「LLM Wiki」という考え方です。彼の比喩がよくできていて、こう言っています。
Obsidianは IDE、LLMはプログラマー、wikiはコードベース。
LLM Wikiはもともと「知識ベースをLLMが保守する」という発想ですが、本稿ではそれをさらに一歩進めて、Obsidian VaultだけでなくClaude CodeとCodexの skills / rules / handoff まで同じ基盤に載せます。配置を整理するとこうなります。
_shared-ai/ = 両者が共有するヘッダーファイル群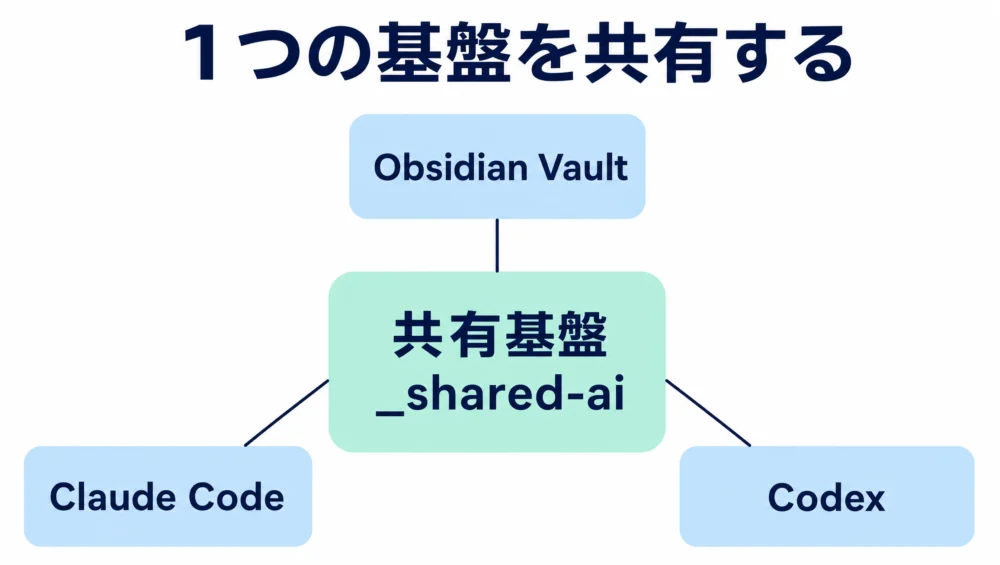
「個別最適」から「統合最適」へ。手順だけじゃなく、なぜそうするのかの理屈もセットで書いていきます。

「どっちを使う?」じゃなくて「どっちも同じ知識を見てる」状態を作るのがゴールだよ。
ここ数ヶ月でClaude CodeとCodexを併用する人が一気に増えました。OpenAIの発表では、Codexは2026年3月時点で週間アクティブユーザー200万人超(直近3か月で約5倍、月次70%以上の伸び)、4月初旬に300万人超、その約2週間後の4月21日には400万人超に達しています。Claude CodeもJetBrainsの2026年1月調査で満足度(CSAT)91%・推奨度(NPS)+54と、いまの開発ツールの中では頭ひとつ抜けた数字です。
ちなみに同じJetBrains調査では、Codexは同時点で業務利用3%程度にとどまっています。ただしこれはCodexのデスクトップアプリ公開やChatGPT内での露出拡大より前のスナップショットで、その後の急伸(上の200万→400万の流れ)を踏まえると「両方伸びている」と読むのが妥当です。だから「乗り換えるか継続か」ではなく「両方をどう共通化するか」を考えた方がいい、というのが出発点です。
Claude Code、Codex、Obsidianという3環境を別々に育てると、だいたい3つの問題が同時に起きます。
1つ目はMCPの入れすぎでコンテキストが重くなること。 これは実測でかなりはっきり出ています。ScalekitのMCP vs CLIベンチでは、GitHub操作タスクでMCPがCLIより1.3〜80倍多くトークンを使う結果が出ています。MCPはツール定義を毎セッション読み込む設計なので、便利だからと入れ続けるとメタデータでコンテキストが埋まって、肝心のコード文脈が押し出されます。
ただし注意が必要で、MCP批判は「プロトコル自体が不要」という話と、「肥大化したMCPサーバー運用が非効率」という話が混ざりがちです。2026年初頭に “MCP is dead. Long live the CLI”(Eric Holmes)が話題になりましたが、実務上の結論は「不要」ではありません。CLIで十分なものはCLI、外部サービス連携・権限管理・リアルタイム連携が必要なものはMCP、という使い分けが現実的です。
2つ目はClaudeとCodexの切り替えコストが積み上がること。 設定・スキル・許可リストが別ディレクトリだと、片方の知見が再利用できません。
3つ目はObsidianのVaultが活かしきれないこと。 せっかくメモを資産化したのに、AI側からは「ただのフォルダ」扱いになりがちです。
そしてこれ、スケールするほど壊れます。ルール・スキル・MCPを増やすほど、自分のシステムを自分で把握できなくなる。だから最初から大きく作らず、小さく始めて昇格させる設計にします。
実装に入る前に見取り図を。スキルをどこに置くかは、この3層で決めます。

| 層 | 置き場所 | 呼ばれる範囲 | 例 |
|---|---|---|---|
| L1(プラグイン固有) | プラグイン内 | 1ツール内で完結 | そのプラグイン専用の処理 |
| L2(共通)★主役 | _shared-ai/skills/ → 各ツールにリンク | 2ツール共通 | 後述の共通スキル4本 |
| L3(プロジェクト固有) | 各リポジトリの .claude/skills/・.agents/skills/ | 1案件で閉じる | その案件専用スクリプト |
判断は1つの問いだけ。「これは何個のツール/案件から呼ばれるか」。1ツール内で完結ならL1、2ツール共通ならL2、1案件専用ならL3です。
迷ったらL1から始めるのが正解です。理由は、L1は影響範囲が局所的だから後でL2に昇格させるのが楽で、逆方向(L2→L1)は参照箇所を全部書き換えないといけなくて面倒だから。「まずL1で書いて、2ツールから呼ばれることが実証されたらL2に昇格」を基本フローにすると、手戻りが減ります。
この3層が成立するのは、ClaudeもCodexもskillsが「段階的開示(progressive disclosure)」になっているからです。スキルのメタデータ(nameとdescriptionとパス)だけが起動時に読まれて、本体の指示文は発動時、追加リソースは実行時に初めて読まれる。だからCLAUDE.md / AGENTS.mdに長い手順を直書きするより、スキルに切り出した方がコンテキスト効率が高いのです。
ただし「無制限に増やしてよい」という意味ではありません。スキル1本ごとに待機時の小さなコスト(目安で数十〜百トークン程度)がかかりますし、Codexでは初期スキル一覧にコンテキスト上限(おおよそ2%・8,000字程度)があり、数が多いとdescriptionが短縮されたり一部が初期一覧から省かれたりします。共通スキルは増やせるけれど、後述の棚卸しはやはり必要、と覚えておいてください。
そしてもう1つ重要なのが、Anthropicフォーマットで書いた SKILL.md をCodexがほぼそのまま読めること。この互換性が、1か所に集約する根拠です。ここからステップごとに、コマンド込みで書いていきます。
_shared-ai/ を作る最初にやるのは、共通ファイルの物理的な置き場所を決めることです。クラウドドライブ(Google DriveやOneDriveの同期領域)の配下に _shared-ai/ を切ります。
なぜクラウドドライブか。 理由は2つで、ローカルマシン依存にならず複数台から参照できること、そしてClaude CodeとCodexの両方が後述のjunction / symlinkで同じ実体を読めることです。
中身はこんな構造にします。
| フォルダ | 役割 |
|---|---|
skills/ | L2共通スキル群(Step 3で作る。中に bestpra-checker / cli-vs-mcp-audit / factcheck-ai-cross / codex-handoff の4本) |
knowledge/ | 共通ノウハウ(公式ベスプラ・判断材料) |
prompts/ | プロンプトテンプレート |
scripts/ | 共通スクリプト(文字数チェック等) |
README.md | 運用ルール(Step 6で埋める) |
そして、これをクラウドドライブ直下でPARA構造と並列に置きます。下の _shared-ai/ と Obsidian-Vault/ が今回の主役です。
| フォルダ | 役割 |
|---|---|
00-Projects/ | 進行中の案件 |
01-Areas/ | 締切なし継続業務 |
02-Resources/ | 参考素材・テンプレ |
03-Archive/ | 終了 / 凍結 |
_inbox/ | 仮置き |
_shared-ai/ ★ | 共通ファイル領域(PARAと独立した第5階層) |
Obsidian-Vault/ | 中央ナレッジハブ |
PARAはTiago Forteの「プロジェクト/エリア/リソース/アーカイブ」の4分類です。ここでのコツは、_shared-ai/ をPARAとは独立した第5階層として扱うこと。
理由を一応説明すると、_shared-ai/ をProjectsの中に置くと案件終了時にArchiveに飛んで他から参照できなくなるし、Resourcesに置くと素材と共通スキルが混ざって判断軸がぼやける。_shared-ai/ は「時間でアーカイブされない・案件固有じゃない・素材じゃなくて実行可能な資産」なので、独立させる必要があるわけです。
最後に README.md に運用ルールを書いておきます。半年後の自分が「なんでこのスキルがここにあるんだっけ」を再構築しなくて済むように、最低この4つ。各ディレクトリの責務、新規スキルのL1/L2/L3判断フロー、信頼ソースの基準(自作か公式か)、棚卸し頻度です。これは最後のStep 6で埋めます。
_shared-ai/skills/ を作ったら、Claude CodeとCodexの両方が同じskill実体を読めるようにします。
ここで一番大事なのは、両者の公式ディレクトリが違うことです。
~/.claude/skills/<skill-name>/SKILL.md、プロジェクト用は .claude/skills/<skill-name>/SKILL.md~/.agents/skills/<skill-name>/SKILL.md(リポジトリ内に置く場合は .agents/skills/)どちらも起動時にこのディレクトリを自動スキャンします(Claude Codeは新規追加後に再起動が必要な場合あり)。なので、クラウドドライブ上の _shared-ai/skills/ にskill本体を置き、各skillディレクトリをそれぞれの公式ディレクトリにjunction / symlinkで貼るのが正解です。「片方は自動、もう片方は手動Read」みたいに非対称にする必要はありません。
CLOUD_SKILLS="<クラウドドライブパス>/_shared-ai/skills"
mkdir -p "$HOME/.claude/skills" "$HOME/.agents/skills"
for d in "$CLOUD_SKILLS"/*; do
[ -d "$d" ] || continue
name="$(basename "$d")"
ln -sfn "$d" "$HOME/.claude/skills/$name"
ln -sfn "$d" "$HOME/.agents/skills/$name"
done$CloudSkills = "<クラウドドライブパス>\_shared-ai\skills"
New-Item -ItemType Directory -Force "$env:USERPROFILE\.claude\skills" | Out-Null
New-Item -ItemType Directory -Force "$env:USERPROFILE\.agents\skills" | Out-Null
Get-ChildItem $CloudSkills -Directory | ForEach-Object {
$claudeTarget = "$env:USERPROFILE\.claude\skills\$($_.Name)"
$codexTarget = "$env:USERPROFILE\.agents\skills\$($_.Name)"
if (-not (Test-Path $claudeTarget)) {
cmd /c mklink /J "$claudeTarget" "$($_.FullName)"
}
if (-not (Test-Path $codexTarget)) {
cmd /c mklink /J "$codexTarget" "$($_.FullName)"
}
}Windowsでjunction(mklink /J)を使うのは、symlinkより権限要件がゆるく、別ドライブ間でも貼れるからです。Mac/Linuxの ln -sfn は、再実行時にリンクを貼り直せる安全な形にしてあります。ただし、同名の実ディレクトリがすでに ~/.claude/skills/ や ~/.agents/skills/ にある場合は、上書きせず中身を確認してから退避してください(既存ディレクトリを消す自動化は避ける)。
これで、_shared-ai/skills/bestpra-checker/SKILL.md を1回更新するだけで、Claude CodeとCodexの両方が同じskillを参照できます。
なお、~/.codex/ 自体はskillsではなくCodexの設定用です(グローバルなAGENTS.mdや config.toml)。たとえば特定スキルを消さずに無効化したいときは ~/.codex/config.toml の [[skills.config]] で enabled = false にする、といった使い方をします。L3(案件固有スキル)を使いたいときは、_shared-ai ではなくそのリポジトリ内の .claude/skills/ と .agents/skills/ に置けばOKです。
貼れたら確認します。
# Codex 側
ls ~/.agents/skills/
# → bestpra-checker / cli-vs-mcp-audit / ... が見えればOK
# Claude Code 側
ls ~/.claude/skills/
# Claude Code を再起動後、/(スラッシュ)から skill 名が呼べれば成功物理的な接続はこれで完了。あとは中身を書くだけです。
_shared-ai/skills/ に何を置くか。これを決めると、Claude CodeとCodexが同じ判断軸で動くようになります。逆にここをミスると2ツールで挙動が割れます。
まず最小単位のおさらい。1つのスキルは「指示文 + メタデータ + (必要なら)補助リソース」の3点セットで、SKILL.md の先頭にこのYAMLを置きます。ディレクトリ名と name は揃えます。
---
name: skill-name-kebab-case
description: This skill should be used when the user asks to "phrase1", "phrase2", or discusses [topic].
# version は公式の必須項目ではない。運用管理用の独自メタデータとして任意で付ける
version: 0.1.0
---この name と description が、起動時に読まれる部分です(Codex互換を重視するなら、必須はこの2つと考えておけば安全。version は付けても付けなくても動きます)。設計の鉄則は4つだけ覚えておけばOKです。1スキル1責任・指示文優先(決定的な処理が要るときだけスクリプト)・入出力を冒頭で明示・信頼できるソースのみ(自分が書いたか公式由来か)。最後のは地味に大事で、スキルはコード実行権限を持つので、「共通だから安全」じゃなくて「自分が書いたから/公式だから安全」が判断基準です。
で、実運用で効く4本がこれです。
書いたスキルが公式仕様に沿ってるかを自動チェックするスキルです。これがあると新規スキルの品質ブレが減ります。チェックするのは8項目くらい。frontmatterの必須キーが揃ってるか / descriptionがトリガー形式になってるか / 本文が長すぎないか / I/Oが明示されてるか / 補助データが分離されてるか / MCP依存になってないか / 1責任になってるか / 信頼ソースの注意が入ってるか、です。
ポイントは、「動くスキル」と「正しく書かれたスキル」は別物ってこと。後者は人の判断より機械チェックの方が再現性が高いんです。
登録中のMCPを列挙して「CLIで代替できないか」を判定するスキル。さっきのコスト差の話があるので、定期的に棚卸しする文化を持つと無駄なコンテキスト消費を抑えられます。やることは、現在のMCP一覧を取得 → 各MCPにCLI代替があるか確認 → あれば置換手順を提示、なければ理由を記録(リアルタイム性が必要 / UI操作必須 / 認証フローが特殊 など)。月1回か、コンテキスト消費が気になり始めたタイミングで回す設計にします。
重要な成果物(事業計画の数値、記事のファクト、法律条文の引用など)をClaudeとCodexの2系統で検証するスキル。流れはシンプルで、Claudeで第1次回答を作る(ソース記録)→ Codexで独立検証 → 一致なら採用、不一致ならユーザー判断、一次ソースに届いてなければ再依頼、です。
現実的な落とし所は「最終確認はClaude、計算検証はCodex」みたいな役割分担で、両者の出力を統合する箇所だけスキル化しておく形です。
Claudeで「設計・判断」をやってCodexに「実装・実行」を渡す、その引き継ぎを定型化するスキル。必要な要素は5つ。タスクの目的 / 制約条件(使う技術・避ける手法) / 受け入れ基準 / 参照ファイル / 完了報告の形式です。これをテンプレ化しておくと、毎回ゼロから書かなくて済みます。
新規スキルは①で品質保証、MCPは②で棚卸し、重要成果物は③で2系統検証、Claude→Codexは④で定型化。つまり「共通スキル領域そのものの品質維持」と「2ツール連携の品質」の両方が、スキル4本で回るようになります。「スキルでスキルを管理する」入れ子構造ですね。書いた瞬間は仕事を増やしてるように見えるけど、数週間後には戻れなくなります。
「スキルを管理するスキル」って入れ子で、最初は変な感じ。でも回り始めると、これなしには戻れないよ。
物理接続が終わったら、司令塔ファイルの整理です。Claude Codeは CLAUDE.md(プロジェクト直下、グローバルは ~/.claude/CLAUDE.md)、Codexは AGENTS.md(プロジェクト直下、グローバルは ~/.codex/AGENTS.md)を司令塔として読みます。別々に書くとメンテが倍になるし、判断基準がズレていく。なので「同じ思想の別実装」として、共通部分と分離部分を切り分けます。
共通化していい3つ。
_shared-ai/skills/(=~/.claude/skills/ と ~/.agents/skills/ にリンク済み)」と書く_shared-ai/knowledge/cli-vs-mcp.md のような共通ファイルを見る形にすると、判断がブレません逆に分離すべき3つ。
AGENTS.md に書かない、Codex側のplugin packagingを CLAUDE.md に混ぜない、という分離ですそして一番大事な原則。司令塔ファイルは薄く保つ(200行くらいが目安)。 詳細は rules/ に委任します。
| ファイル | 役割 |
|---|---|
CLAUDE.md / AGENTS.md | 司令塔。薄く保つ(何を誰に任せるかだけ書く) |
rules/shared-conventions.md | 両ツール共通のルール |
rules/claude-specific.md | Claude Code 固有 |
rules/codex-specific.md | Codex 固有 |
理屈はこうです。エンジニアリングの本質は実装そのものより計画とレビューにあって、AIエージェント運用だと体感「計画が大半・実装は一部」くらいの比率になります。司令塔が「自分で全部やろう」とすると、サブエージェントやスキルに権限を渡せなくなって、全部が司令塔に集約されてコンテキストが肥大する。だから司令塔は「何を誰に任せるか」だけ書いて、中身は委任先に任せます。
なお、Claude Codeの CLAUDE.md は @path でファイルを取り込めますが、Codexの AGENTS.md はグローバル/プロジェクトの階層を上から連結して読む方式で、同じimport構文が前提とは言えません。完全に自動連動させたい場合は、_shared-ai/rules/ の共通ルールから両ファイルを生成するスクリプトを用意するのが確実です(後述)。
ここでObsidianが中央リポジトリとして効いてきます。「ただのノートアプリ」として扱うか「中央ハブ」として設計するかで、伸び方が変わります。
KarpathyのGistでは、Vaultの中を3層で整理する設計が提案されています。
この分離の何が効くかというと、「AIが暴走してもRaw sourcesは無傷」という安全装置になること。Wiki層はAIが日々書き換えていいけど、Rawは人間が置いたものにAIは触りません。
実運用ではこんな感じに落とします。
| フォルダ | 役割 |
|---|---|
Knowledge/ | AI生成ノート(Wiki層) |
Library/ | 外部素材(Raw層) |
Daily/ | デイリーノート |
Sessions/ | セッションダイジェスト |
Tasks/ | タスク履歴 |
Library の素材には信頼度のtier(1=一次データ 〜 5=ソーシャル/逸話)を付けて、Knowledge のAI生成ノートには source: claude-code みたいなfrontmatterを必須にします。これで「どの情報をどれだけ信用していいか」「これはAI生成か自分が書いたか」が後から判定できます。
ここで効くのがObsidianのCLIです。早期アクセスはv1.12.0(2026年2月10日)、全ユーザー向けの無料提供はv1.12.4(2月27日)から始まりました。公式ヘルプでは現在、installerを1.12.7以降に更新し、Settings → General → Command line interfaceを有効化して「Register CLI」する手順が案内されています。これで obsidian search(Vault検索)、obsidian backlinks、obsidian orphans などが使えます。
速度面では、ある実測ポストでgrepより大幅に速いという結果が共有されています(orphanノート検出でgrep 15.6秒に対しCLI 0.26秒、通常検索でgrep 1.95秒に対しCLI 0.32秒、という測定例)。Obsidianが持つ検索インデックスをそのまま使うので速い、というカラクリです(grepは毎回全ファイルを走査する)。ただしこれは特定環境での測定値なので、自分のVaultでは数字が変わります。実測を引用するなら測定環境か元ポストを明記しておくのが安全です。
CLIを使わせるなら、CLAUDE.md にこう書いておくのがおすすめです。
## Vault操作
- Vault検索はgrep/findでなく `obsidian` CLIを使う
- `obsidian search` を優先(全文走査より高速・低トークン)
- バックリンク/孤立ノートは `obsidian backlinks` / `obsidian orphans`注意点として、CLIは起動中のObsidianアプリと通信する仕組みなので、Claude Code(bashでコマンドを叩ける)からは使えますが、claude.aiやデスクトップアプリから直接は触れません。初期版で日本語パスに問題があったのがv1.12.4で直っているので、バージョンは最新にしておきましょう。
トークンがさらに気になる場面では、VaultとAIの間にRAG(NotebookLMなど)を挟んで、フルVaultをコンテキストに載せない構成も有効です。NotebookLMの使い方は NotebookLMの使い方|PDF・YouTube・資料をAIで要約する方法 にまとめています。
設計と接続が終わったら最後。統合は構築した瞬間が一番きれいで、数週間後に荒れます。これを防ぐ運用ルールを最初に決めておきます。
頻度を分けて回します。MCPは月1回(②のcli-vs-mcp-auditで代替候補を判定)、スキルは隔週(発動してないスキルを洗い出す。Codexの初期一覧上限の話もあるので、増えすぎたら整理する)、ephemeralは四半期(cache / debugの蓄積を確認、半年以上更新ないものを削除)。「やる時間をカレンダーに入れる」のが現実的です。
AnthropicのClaude Code Routines(2026年4月公開、研究プレビュー)を使うと、cronスケジュール / API呼び出し / GitHubイベント(PRやIssue)の3トリガーで自動実行できます。クラウド側で走るので、自分のPCが落ちてても動きます。
実行回数には、通常の利用枠に加えてアカウント単位の日次上限があります(公開時点の目安でPro 5・Max 15・Team / Enterprise 25回/日。最新値や残り回数は claude.ai/code/routines またはusage settingsで確認を)。上限に達したあとは、usage creditsが有効な組織なら従量超過で継続でき、そうでなければリセットまで追加実行は拒否されます。たとえば「毎週月曜の朝にMCP棚卸し → 結果をVaultのDailyに保存」みたいな自動化を組むと、棚卸しが「カレンダーで決める」から「勝手に走る」に変わります。
エージェントを組み合わせるときの基本は、機能で役割を分けること。設計・判断・コンテキスト管理はClaude Code、実装・並列処理・軽量タスクはCodex、という噛み合わせが自然です。
そのうえで、重要成果物の検証はStep 3 ③の通り別系統でクロスチェックします(Claudeの回答をCodexに独立検証させる、または逆)。同じモデル系統どうしだと得意・不得意のクセも似るので、事実誤りやハルシネーションはあえて別系統に当てた方が拾いやすい。「役割は分ける、検証は別系統で重ねる」がシンプルで効きます。
いきなり全自動を狙うと壊れます。この順で上げていくのが安全です。
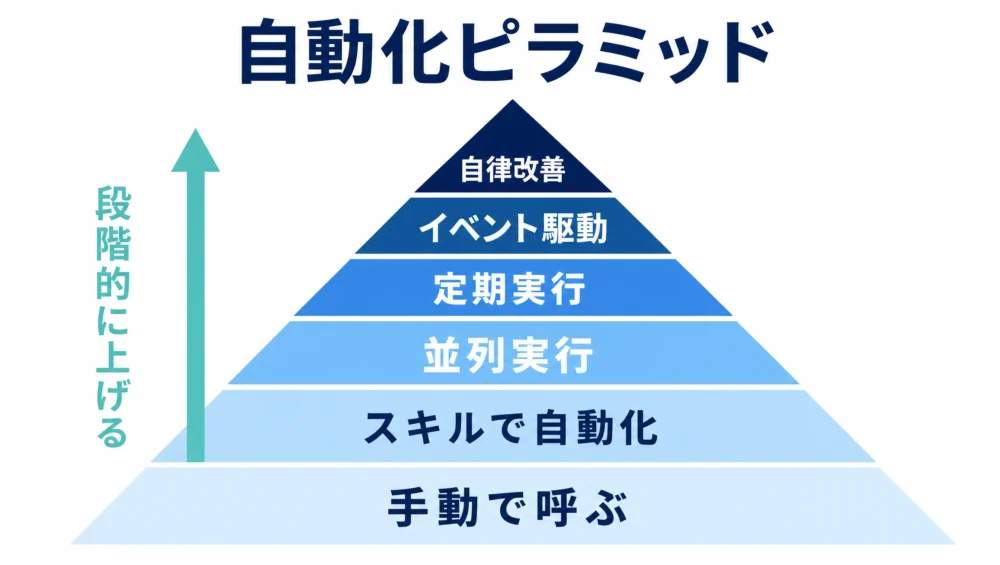
重要なのは、Lv.2〜3で安定運用を作ってから、定常化したものだけを少しずつ上げること。最上位の自律改善ループ(エージェントが自分でワークフローを直し続ける形)は魅力的ですが、「最初からLv.6」が、さっきの破綻パターンそのものです。
最後に、ここまでの運用ルールを _shared-ai/README.md に書き込みます。棚卸しの3サイクル、Routinesのスケジュール一覧、Claude/Codexの役割分担と検証ルール(検証は別系統で)、自動化ピラミッドの現在位置です。これがあると半年後の自分が現在地と次の一手をすぐ把握できます。
いきなりLv.6(全自動)を狙うと、だいたい崩れるの。Lv.2〜3で土台を固めてから、少しずつ上げてね。
長くなったので圧縮すると、こういう階層です。
Obsidian Vaultが中央リポジトリ、Claude Codeが設計担当、Codexが実装担当、_shared-ai/ が共有ヘッダー、CLAUDE.md / AGENTS.md が司令塔、共通スキル4本が品質・棚卸し・検証・引き継ぎの基盤、運用3サイクルで維持。
これが組み上がると、スキルを1本追加するだけでClaudeとCodexの両方がその瞬間から使える(同じ実体を ~/.claude/skills/ と ~/.agents/skills/ にリンクしているから)。Vaultに書いたノートが両者の共有知になる。司令塔ファイルの共通ルールは _shared-ai/rules/ に一元化して、完全に自動連動させたいなら共通ルールから両ファイルを生成するスクリプトを用意する。
「別々に育てる」から「1つの基盤を育てて両方が共有する」への切り替え。ここまで来ると、「ClaudeかCodexか」の悩みが小さくなって、「両方を使い倒す」運用に着地できます。
全部いっぺんにやらなくて大丈夫です。まずこれだけ。
_shared-ai/skills/ を作るbestpra-checker/SKILL.md を1本だけ書く~/.claude/skills/ と ~/.agents/skills/ の両方にリンクするこれでClaude CodeとCodexの両方から「公式ベスプラ準拠チェック」が呼べます。2週目にcli-vs-mcp-audit、3週目にfactcheck-ai-cross、4週目にcodex-handoff。1ヶ月で骨格が完成します。
まずは15分。_shared-ai/skills/ を作って、スキルを1本だけ。そこから1週1本ずつでいいよ。
数値はいずれも公開時点(2026年前半)のものです。引用前に各一次ソースで最新を確認することをおすすめします。
~/.claude/skills/ / プロジェクト用 .claude/skills/ の出典.agents/skills のスキャン挙動・段階的開示・初期一覧上限~/.codex/AGENTS.md ほか読み込み順A. この記事の立場は「絞らない」です。どちらを選ぶかより、両方が同じスキル・ルール・ナレッジを参照できる状態を作るほうが効果的だからです。スキルもナレッジも設定も1か所(_shared-ai)に集めて両ツールが同じ実体を読みに行くようにすると、片方で覚えた知見がそのままもう片方でも使え、ツール選定の悩み自体が小さくなります。
A. Google DriveやOneDriveなどクラウドドライブの同期領域の直下に置くのがおすすめです。理由は2つで、ローカルマシン依存にならず複数台から参照できること、そしてClaude CodeとCodexの両方からjunctionやsymlinkで同じ実体を読めることです。PARA(Projects/Areas/Resources/Archive)とは別の独立した第5階層として扱うと、案件終了でアーカイブされたり素材と混ざったりせずに済みます。
A. 迷ったらL1(プラグイン固有)から始めるのが正解です。L1は影響範囲が局所的なので、後でL2(共通)に昇格させるのが簡単な一方、逆方向の格下げは参照箇所を全部書き換える必要があり面倒だからです。「まずL1で書き、2ツールから呼ばれることが実証できたらL2へ昇格」を基本フローにすると手戻りが減ります。
A. いいえ。MCP批判には「プロトコル自体が不要」という主張と「肥大化したMCP運用が非効率」という主張が混ざりがちですが、実務上の結論は不要ではありません。CLIで十分なものはCLI、外部サービス連携・権限管理・リアルタイム連携が必要なものはMCP、という使い分けが現実的です。定期的な棚卸しでCLIに置き換えられるものだけ移す、という運用にすると無駄なコンテキスト消費を抑えられます。
A. 完全に1ファイルにはしませんが、共通部分は一元化できます。L2スキル定義・AI×AIファクトチェック手順・CLI vs MCPの優先順位といった共通部分は_shared-ai/rules/にまとめ、プラグインや配布形式・Sandboxや権限設定・モデル選択ロジックといったツール固有部分は分離します。完全に自動連動させたい場合は、共通ルールから両ファイルを生成するスクリプトを用意するのが確実です。
A. Anthropicフォーマットで書いたSKILL.mdは、Codexがほぼそのまま読めます。これが1か所に集約できる根拠です。ただしCodexには初期スキル一覧のコンテキスト上限(おおよそ2%・8,000字程度)があり、スキル数が多いとdescriptionが短縮されたり一部が初期一覧から省かれたりします。共通スキルは増やせますが、隔週程度の棚卸しはやはり必要です。





