
ノーコードで始めるAIデータ分析|初心者向け5ツール比較【2026年版】
ルミィ
AIの歩き方

ランダムフォレスト、XGBoostと来て、機械学習入門シリーズもいよいよ第6回。今回は、XGBoostと並ぶ勾配ブースティングのもう一つの定番、LightGBM(ライトジービーエム)です。
Kaggleや実務のテーブルデータ分析では、「とりあえずLightGBM」と言われるほどよく使われます。理由はシンプルで、速くて、軽くて、精度も高いから。この記事では、LightGBMの仕組み、XGBoostとの違い、使い分け、Pythonでの実装までを初心者向けに整理します。

名前のとおり「軽い(Light)」が最大の個性。大きなデータほど、ありがたみが分かるよ。
LightGBMは、Microsoft発のオープンソースの勾配ブースティング(Gradient Boosting)ライブラリです。XGBoostと同じく「弱い決定木を少しずつ改善しながら積み上げる」仕組みで、テーブルデータ(表形式データ)の予測で高い精度を出します。
ポジションを一言でいうと、「XGBoostと同じ系統で、大規模データをより速く・少ないメモリで処理できるように設計されたライブラリ」です。
LightGBMは、連続値の特徴量をそのまま使わず、一定数のビン(区間)に分けたヒストグラムに変換してから分割点を探します。細かい値を全部見比べる代わりに「ざっくりまとめてから探す」ので、計算量とメモリが大きく減ります。
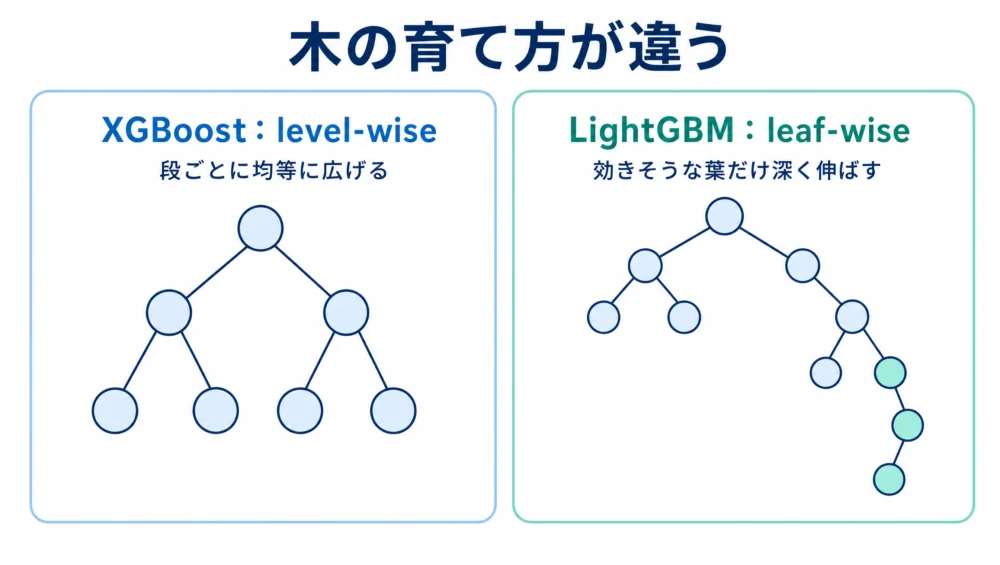
決定木の育て方には2つの流儀があります。XGBoostの従来方式はlevel-wise(段ごとに均等に広げる)、LightGBMはleaf-wise(損失が最も減る葉を選んで深く伸ばす)です。
leaf-wiseは同じ葉の数ならlevel-wiseより損失を小さくしやすい、つまり効率よく精度を上げられる方式です。そのぶん、データが少ないと深く伸びすぎて過学習しやすいという弱点があり、max_depthなどで深さを抑えるのがセットになります。
| XGBoost | LightGBM | |
|---|---|---|
| 開発元 | DMLC(オープンソース) | Microsoft発(オープンソース) |
| 木の育て方 | level-wise(段ごとに均等) | leaf-wise(効く葉を深く) |
| 速度 | 高速(hist設定でさらに高速) | 大規模データで特に速い |
| メモリ | 標準的 | 少なめ(ヒストグラム化) |
| 小さいデータ | 比較的安定 | 過学習しやすく調整が必要 |
| カテゴリ変数 | 基本は数値化が必要 | 直接指定して扱える |
なお、最近のXGBoostにもヒストグラム方式(tree_method="hist")があり、速度差は昔ほど大きくありません。「LightGBM=常に速い」ではなく、「大規模・横に広いデータで差が出やすい」と覚えるのが正確です。

実務では「どちらかが圧勝」というより、データ規模と前処理の手間で選ぶのが現実的です。精度はチューニング次第で拮抗することが多いです。
インストールはpipで一発です。
pip install lightgbmscikit-learnと同じ書き方(fit/predict)で使えます。
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
model = lgb.LGBMClassifier(
n_estimators=300,
learning_rate=0.05,
num_leaves=31,
random_state=42)
model.fit(X_train, y_train)
pred = model.predict(X_test)
print("accuracy:", accuracy_score(y_test, pred))LGBMClassifier(分類)とLGBMRegressor(回帰)の2つを覚えれば、シリーズでやってきたscikit-learnの流れがそのまま通用します。
| パラメータ | 意味 | 目安 |
|---|---|---|
| num_leaves | 葉の数(モデルの複雑さ) | 31から。上げすぎると過学習 |
| learning_rate | 1本ごとの学習の強さ | 0.05〜0.1で小さめに |
| n_estimators | 木の本数 | 300〜1000+早期打ち切り |
| max_depth | 木の深さの上限 | 過学習対策に。-1(無制限)から必要なら制限 |
| min_data_in_leaf | 葉に必要な最小データ数 | 増やすと過学習を抑えられる |
leaf-wiseの複雑さを直接決めるのはnum_leavesです。max_depthだけ調整してnum_leavesを放置すると意図どおりに効かないことがあるので、まずnum_leavesから触るのがLightGBM流です。
過学習っぽいな、と思ったら「num_leavesを下げる」「min_data_in_leafを上げる」。この2つが効き目わかりやすいよ。
LightGBMの隠れた主役が、カテゴリ変数(職業・地域・商品種別のような「種類」のデータ)をほぼそのまま扱えることです。他のモデルで定番のワンホットエンコーディング(種類ごとに列を増やす変換)を省けるので、前処理が劇的に楽になります。
やることは、pandasで列の型をcategoryに変えるだけです。
import pandas as pd
df["職業"] = df["職業"].astype("category")
df["地域"] = df["地域"].astype("category")
# あとは普通にfitするだけ。LightGBMがカテゴリとして認識する
model.fit(X_train, y_train)category型に変換してから「木を何本にするか(n_estimators)」を手で当てるのは大変です。実務では、検証データの精度が改善しなくなったら自動で学習を止める「早期打ち切り」を使います。
import lightgbm as lgb
model = lgb.LGBMClassifier(
n_estimators=1000, # 多めに設定しておく
learning_rate=0.05,
random_state=42)
model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)], # 検証データ
callbacks=[lgb.early_stopping(50)]) # 50回改善しなければ停止
print("実際に使われた木の本数:", model.best_iteration_)これで「n_estimatorsは多めに置いて、止めどころはデータに決めさせる」運用ができます。過学習防止と時間短縮を同時に達成できる、LightGBM運用の定番です。
学習後に「モデルがどの列を重視したか」を確認できます。分析の振り返りや、説明資料づくりに便利です。
import pandas as pd
importance = pd.Series(
model.feature_importances_,
index=X_train.columns).sort_values(ascending=False)
print(importance.head(10))注意:重要度は「モデルがよく使った」ことを示すだけで、因果関係(それが原因かどうか)までは語りません。「この列を変えれば結果が変わる」と読み替えないようにしましょう。
astype("category"))LightGBMは、ヒストグラム化とleaf-wise成長で「速く・軽く・高精度」を実現した勾配ブースティングライブラリです。XGBoostとの関係は、敵対というより同系統の使い分け。データが大きいほどLightGBMの強みが活き、小さいデータでは過学習への注意が必要です。
大規模・速度重視 → LightGBM。
小さめ・堅実 → XGBoost/ランダムフォレスト。
どちらも試して交差検証で比べるのが、いちばん確実。
シリーズの前回までは XGBoost・勾配ブースティング入門、ランダムフォレスト完全ガイド をどうぞ。
📚 機械学習入門シリーズ(全6回)
A. データが大きい・特徴量が多い・速度を重視する場合はLightGBM、小さめのデータで堅実に進めたい場合はXGBoostが目安です。精度はチューニング次第で拮抗することが多いため、両方試して交差検証で比べるのが確実です。
A. 特徴量をヒストグラム(ビン)にまとめてから分割点を探すことと、損失が最も減る葉だけを深く伸ばすleaf-wise成長の2つが主な理由です。計算量とメモリ使用量の両方を抑えられます。
A. 使えますが、leaf-wise成長の特性上、過学習しやすくなります。num_leavesを小さくする、min_data_in_leafを増やす、max_depthを制限するなどの調整が必要です。
A. 必須ではありません。LightGBMはCPUでも十分高速に動作します。大規模データでさらに高速化したい場合に、GPU版を検討する形で十分です。
※本記事は2026年6月時点の公式ドキュメント・公開情報をもとに整理しています。ライブラリの仕様・推奨設定は変わることがあるため、最新情報は公式ドキュメントでご確認ください。
🧩 仕組みの根っこを知る:LightGBMは「アンサンブル学習」の代表例です。なぜ弱い学習器をたくさん束ねると強くなるのか——その背骨の考え方(バギングとブースティングの違い)は、アンサンブル学習とは?で図解しています。





