ロジスティック回帰とは?線形回帰との違いを初心者向けに解説【分類問題への第一歩】
ルミィ
AIの歩き方


XGBoost、Kaggle で最強って聞くけど、結局どんな仕組み?
XGBoost は2014年に登場して以来、Kaggle のテーブルデータコンペで大きな存在感を持ち、実務でも「最初に試すべきモデル」として定着しています。一方で、「LightGBM・CatBoost と何が違う?」「決定木との関係は?」を即答できる人は意外と少なめです。
私もね、XGBoost を最初に動かした日に『これでもう機械学習は怖くない』って思ったんだ
この記事は、XGBoost と勾配ブースティングを初心者から実務レベルまで使いこなすための完全ガイドです。仕組み(決定木+ブースティング)、Python での実装、ハイパーパラメータチューニング、LightGBM・CatBoost との比較、ビジネスでの活用例まで網羅。Kaggle や実務で機械学習の精度を一段引き上げたい全ての人向けの実践チュートリアルです。
本記事では、機械学習を学び始めて「決定木」「ランダムフォレスト」までは理解した方を想定し、勾配ブースティングの仕組み→XGBoostの革新点→Python実装→ハイパーパラメータチューニング→実務での使いどころまでを、数式を最小限にやさしく解説します。読み終わるころには、なぜXGBoostがKaggleで人気なのか、どんな場面で使うべきかが明確になっているはずです。
Kaggleで強いって聞くけど、仕組みはちゃんと知らないかも……!
勾配ブースティングを理解する一番の近道は、「ランダムフォレストとは何が違うのか」を整理することです。両方とも「決定木をたくさん作って組み合わせる」アンサンブル学習という点では同じですが、作り方の発想がまったく違います。
ランダムフォレストはバギング(Bagging:Bootstrap Aggregating)という考え方に基づきます。データから少しずつサンプリングを変えてたくさんの独立した決定木を並列で作り、最後に多数決(分類)または平均(回帰)で予測を統合します。各木は他の木とは関係なく学習され、独立性が高いのが特徴です。
イメージとしては、「クラス全員に独立してテストを解いてもらい、多数派の答えを採用する」ようなものです。一人一人の精度はそこそこでも、集団の判断は安定します。
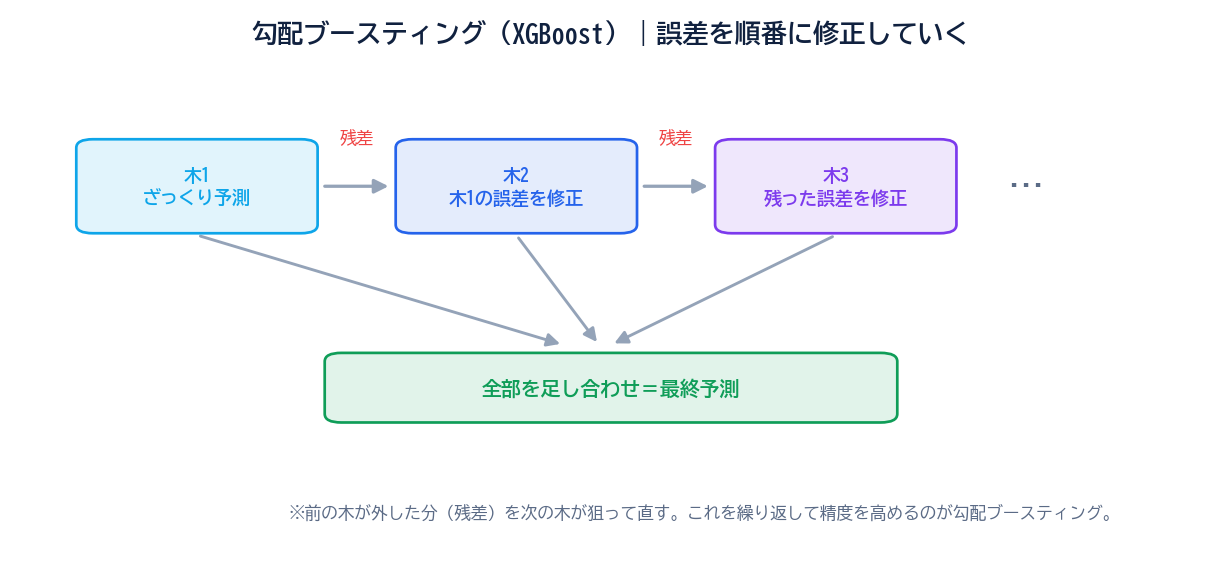
一方、ブースティングは「弱い学習器を順番に積み重ね、前の木が間違えた部分を次の木が補正する」という考え方です。
イメージとしては、「先生が一人ずつ順番に解説していき、前の先生がカバーしきれなかった部分を次の先生が補強していく」ような流れです。木は独立ではなく、前の木の結果に依存して順番に作られるのがバギングとの決定的な違いです。
「勾配ブースティング」の「勾配(Gradient)」は、ディープラーニングの勾配降下法と同じ考え方に由来します。簡単に言うと、損失関数(誤差を表す関数)を最小化する方向に少しずつ重みを更新していくという発想です。各木は「損失関数の勾配(誤差の傾き)」を予測するように学習し、それを既存の予測値に少しずつ足し合わせて改善していきます。
| 項目 | バギング(ランダムフォレスト) | ブースティング(XGBoost等) |
|---|---|---|
| 木の作り方 | 並列・独立 | 逐次・依存(前の結果を見て次を作る) |
| 学習の狙い | 多様な木の平均で分散を下げる | 誤差を順次補正して精度を上げる |
| 過学習リスク | 比較的低い | 高め(チューニング必須) |
| 学習時間 | 並列化しやすく速い | 逐次なので時間がかかりやすい |
| 精度の上限 | 中〜高 | 高(適切にチューニングすれば非常に強力) |
| パラメータ調整 | 比較的シンプル | 多数のパラメータがあり熟練度が必要 |
ここで「非常に強力」と書いたのは、テーブルデータに限った話です。画像・テキスト・音声などの非構造化データでは、ディープラーニング系の方が大きく上回ることが多いことを最後に補足します。
ブースティング系アルゴリズムは長い歴史があり、段階的に進化してきました。代表的な系譜を整理します。
2026年現在、実務ではXGBoost/LightGBM/CatBoostの3つが「勾配ブースティング三巨頭」として使われ続けています。基本概念はどれも同じ(勾配ブースティング)ですが、実装の最適化方針が異なります。記事の後半で違いを整理します。
勾配ブースティング自体は古くからある手法で、Friedmanによる1999年の原稿および2001年の論文に源流があります。Chen & Guestrinによる2016年の論文「XGBoost: A Scalable Tree Boosting System」で、XGBoostはスケーラブルな実装として広く知られるようになり、その後のKaggleブームの中心となりました。具体的な革新点を整理します。
XGBoostは目的関数にL1/L2正則化項を組み込んでいます。これは「木の複雑さにペナルティを課す」仕組みで、過学習を抑える効果があります。従来のGBMには明示的な正則化がなく、過学習しやすかった問題に対する答えでした。
ブースティングは「逐次処理」が本質ですが、XGBoostは「1つの木を作る中での分岐探索」を並列化することで高速化しました。特徴量ごとに最適な分岐点を探す処理がボトルネックだったので、それをCPUコアで分散させた発想です。さらにキャッシュ最適化やヒストグラム化など、低レベルな最適化が多数施されています。
従来は欠損値を前処理で埋める必要がありましたが、XGBoostは欠損値を「どちらの枝に振り分けるか」を学習時に自動決定します。データに欠損が多い実務シナリオで前処理コストが大幅に下がりました。
検証データの性能が改善しなくなったら学習を打ち切る早期停止を標準サポート。これにより「学習しすぎ(過学習)」を自然に防げます。木の本数を厳密にチューニングする必要が減り、運用が楽になりました。
スパース行列(ほとんどゼロの行列)を効率的に扱える設計。さらに、ヒストグラム法(連続値をビン化して高速分岐探索)、GPU対応、分散学習対応など、大規模データへの拡張性も高めています。
理屈の次は実装です。scikit-learnのGradientBoostingから始めて、XGBoost、LightGBMへと進みます。ここではボストン住宅価格データの代替として、scikit-learnに同梱されているカリフォルニア住宅価格データを使った回帰タスクを例にします。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
# データ読み込み
data = fetch_california_housing()
# まず train+valid と test に分ける(テストは最終評価専用)
X_train_valid, X_test, y_train_valid, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42
)
# 続いて train+valid を train と valid に分ける(valid は早期停止やチューニング用)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_valid, y_train_valid, test_size=0.25, random_state=42
)
# 学習
model = GradientBoostingRegressor(
n_estimators=200,
learning_rate=0.05,
max_depth=4,
random_state=42
)
model.fit(X_train, y_train)
# 予測と評価(テストデータは最後に一度だけ評価)
pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, pred))
print(f"Test RMSE: {rmse:.4f}")
scikit-learnのGradientBoostingは追加ライブラリ不要で動く反面、XGBoostやLightGBMより学習が遅く、大規模データでは実用的でないことが多いです。最初の感覚をつかむには十分です。
なお、scikit-learn内でより高速な勾配ブースティングを試したい場合は、HistGradientBoostingRegressor/HistGradientBoostingClassifierも選択肢になります。ヒストグラムベースの実装で、大きめのデータでは従来のGradientBoostingRegressorより実用的です。ただし、Kaggleや実務の定番としては、依然としてXGBoost/LightGBM/CatBoostがよく使われます。
import xgboost as xgb
from sklearn.metrics import mean_squared_error
import numpy as np
# 上で作った X_train / X_valid / X_test をそのまま使う
# 学習
model = xgb.XGBRegressor(
n_estimators=1000,
learning_rate=0.05,
max_depth=6,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
random_state=42,
early_stopping_rounds=30,
eval_metric="rmse"
)
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)], # 早期停止は検証データで判定
verbose=False
)
# 最終評価はテストデータで1度だけ
pred = model.predict(X_test)
print(f"Test RMSE: {np.sqrt(mean_squared_error(y_test, pred)):.4f}")
print(f"Best iteration: {model.best_iteration}")
ポイントはearly_stopping_rounds=30とeval_set。検証データ(X_valid)でスコアが30回連続改善しなければ学習を打ち切ります。これだけで過学習リスクが大きく下がります。XGBoost 3.x系では、early_stopping_roundsはfit()ではなくモデル定義時に渡す仕様になっています(バージョンによって異なるため公式ドキュメント要確認)。
重要なのは、テストデータ(X_test)は最終評価で一度だけ使うことです。早期停止やチューニングに使ったデータで最終評価すると、楽観的なスコアになります。「学習用/検証用/テスト用」の3分割は、勾配ブースティング系では必須の習慣です。
import lightgbm as lgb
from sklearn.metrics import mean_squared_error
import numpy as np
model = lgb.LGBMRegressor(
n_estimators=1000,
learning_rate=0.05,
num_leaves=31,
max_depth=-1,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
random_state=42
)
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)], # 早期停止は検証データで判定
callbacks=[lgb.early_stopping(30)]
)
# 最終評価はテストデータで
pred = model.predict(X_test)
print(f"Test RMSE: {np.sqrt(mean_squared_error(y_test, pred)):.4f}")
LightGBMの特徴はnum_leaves(リーフ数)でモデル複雑度をコントロールする点。XGBoostはmax_depth(深さ)中心ですが、LightGBMは「リーフ単位の成長(leaf-wise)」を採用しているため、リーフ数で制御する考え方になります。
コードは思ったよりシンプルだね!パラメータの意味が気になる……!
XGBoost/LightGBMには多くのハイパーパラメータがあり、これがチューニングの難しさの源です。実務でよく触る代表的なものに絞って整理します。
| パラメータ | 役割 | 典型的な範囲 | 調整方針 |
|---|---|---|---|
n_estimators | 木の本数 | 100〜2000 | 多めに設定し、早期停止で自動調整 |
learning_rate | 各木の寄与の小ささ | 0.01〜0.1 | 小さい方が安定。小さくしたら木を増やす |
max_depth | 木の深さ | 3〜10 | 深すぎると過学習。テーブルデータは4〜8が目安 |
min_child_weight | 葉ノードに必要な重みの最小値 | 1〜10 | 大きいほど保守的(過学習抑制) |
subsample | 各木で使うデータの割合 | 0.7〜1.0 | 1.0未満で過学習抑制。汎化性能↑ |
colsample_bytree | 各木で使う特徴量の割合 | 0.7〜1.0 | 特徴量が多いとき有効 |
reg_alpha (L1) | L1正則化 | 0〜1.0 | 不要な特徴量を抑える |
reg_lambda (L2) | L2正則化 | 0.1〜10 | 重みを滑らかにする |
num_leaves (LGBM) | リーフの最大数 | 15〜255 | 2^max_depthより小さく設定 |
パラメータの優先順位として実務でよく言われるのは、(1) learning_rate と n_estimators をセットで決める → (2) max_depth/num_leaves で木の複雑さを決める → (3) subsample/colsample_bytree で汎化性能を上げる → (4) 正則化(reg_lambda・reg_alpha)で微調整、という順序です。
手動でパラメータを試すのは限界があります。2026年現在、Optunaはハイパーパラメータ探索ライブラリとして広く使われています。探索空間を定義し、試行回数を指定するだけで、効率よく良いパラメータ候補を探してくれます(デフォルトはTPEというベイズ最適化系のサンプラーですが、グリッドサーチやランダムサーチなど他のサンプラーにも切り替え可能)。
import optuna
import xgboost as xgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import numpy as np
def objective(trial):
params = {
"n_estimators": 1000,
"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.1, log=True),
"max_depth": trial.suggest_int("max_depth", 3, 10),
"min_child_weight": trial.suggest_int("min_child_weight", 1, 10),
"subsample": trial.suggest_float("subsample", 0.7, 1.0),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.7, 1.0),
"reg_lambda": trial.suggest_float("reg_lambda", 0.1, 10, log=True),
"random_state": 42,
"early_stopping_rounds": 30,
"eval_metric": "rmse"
}
# 5-fold CVで平均RMSE
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = []
for train_idx, val_idx in kf.split(X_train):
X_tr, X_vl = X_train[train_idx], X_train[val_idx]
y_tr, y_vl = y_train[train_idx], y_train[val_idx]
model = xgb.XGBRegressor(**params)
model.fit(X_tr, y_tr, eval_set=[(X_vl, y_vl)], verbose=False)
pred = model.predict(X_vl)
scores.append(np.sqrt(mean_squared_error(y_vl, pred)))
return np.mean(scores)
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=50)
print("Best RMSE:", study.best_value)
print("Best params:", study.best_params)
このコードは、5分割クロスバリデーションで平均RMSEを最小化するパラメータをOptunaで50回試行します。GridSearchCVのような全探索より効率よく探索しやすく、実務でもよく使われる手法です。
XGBoostは精度が高い反面、「ブラックボックス」と思われがちです。しかし2017年に登場したSHAP(SHapley Additive exPlanations)により、各予測がどの特徴量にどれだけ影響を受けたかを定量化できるようになりました。
# 学習済みXGBoostモデルの特徴量重要度
import matplotlib.pyplot as plt
import xgboost as xgb
xgb.plot_importance(model, importance_type="gain", max_num_features=10)
plt.tight_layout()
plt.show()
importance_typeには"weight"(使われた回数)、"gain"(情報利得の合計)、"cover"(カバレッジ)があり、通常は”gain”を使うのが標準です。ただし、特徴量重要度は「全体の傾向」を見るには良いですが、「個別の予測の根拠」を説明することはできません。そこでSHAPが活躍します。
import shap
# SHAP値を計算
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# 全体的な特徴量重要度(SHAPベース)
shap.summary_plot(shap_values, X_test, feature_names=data.feature_names)
# 個別予測の説明(1サンプル目)
shap.force_plot(
explainer.expected_value,
shap_values[0],
X_test[0],
feature_names=data.feature_names,
matplotlib=True
)
SHAPの強みは「個別の予測について、各特徴量がどれだけプラス/マイナスに寄与したか」を一つ一つ可視化できることです。たとえば「この物件価格の予測が高い理由は、立地スコアが+0.5、築年数が-0.2、面積が+0.3寄与した結果」のように、要因分解ができます。金融・医療など「説明責任」が問われる分野では、SHAPがよく使われる解釈ツールとして広く採用されています。
勾配ブースティング三巨頭の特徴を整理します。どれも「テーブルデータで高精度」という基本性能は同じレベルで、選び分けは「学習速度・前処理コスト・パラメータ調整の好み」で決まります。
| 項目 | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| 開発元 | DMLC(オープンソース) | Microsoft | Yandex |
| 初版 | 2014年 | 2017年 | 2017年 |
| 木の成長 | level-wise(深さ単位) | leaf-wise(リーフ単位) | oblivious tree(対称な木) |
| 学習速度 | 中〜速い | 速い(大規模で有利) | 中 |
| メモリ効率 | 中 | 良い | 中 |
| カテゴリ変数 | 基本はエンコーディングして使うことが多い。近年はenable_categoricalでネイティブ対応も可能 | pandas categoryで対応可能。設定には注意 | カテゴリ変数の自動処理が強み(事前のone-hot encoding不要) |
| 過学習耐性 | 正則化で対応 | num_leavesに注意 | 対称木で過学習抑制 |
| 初心者向け | ドキュメント・記事が豊富 | 速くて気軽に試せる | 前処理が少なくて済む |
| Kaggle人気 | 定番中の定番 | 大規模コンペで強い | カテゴリ多めデータで強い |
実務では「まずXGBoostかLightGBMで1モデル作って性能を見る」のが定石です。3つ全てを試して比較するのは余裕がある場合の話で、最初は1つに絞った方が学習効率が上がります。
「ランダムフォレストとXGBoost、結局どっちを使えばいいの?」という質問はよくあります。回答は「シンプルさを取るならランダムフォレスト、精度を取るならXGBoost」です。
| 状況 | おすすめ | 理由 |
|---|---|---|
| 初学者の最初のモデル | ランダムフォレスト | パラメータが少なく扱いやすい |
| 分析の初期段階・ベースライン作り | ランダムフォレスト | 素早く精度感覚をつかめる |
| 本番運用で精度を最優先 | XGBoost/LightGBM | 適切にチューニングすればRFを上回ることが多い |
| Kaggleコンペで上位を狙う | XGBoost/LightGBM/CatBoost | 勾配ブースティングが定番 |
| 解釈性をある程度残しつつ精度も欲しい | ランダムフォレスト or XGBoost+SHAP | 両方とも特徴量重要度・SHAPで解釈可能 |
| 過学習を強く抑えたい・運用が楽な方が良い | ランダムフォレスト | デフォルト設定でも過学習しにくい |
「ランダムフォレストで70点を素早く取る → 必要ならXGBoostでチューニングして85点を狙う」というステップ式の進め方が、効率的なワークフローです。
XGBoostはテーブルデータでは強力ですが、どんなデータでも万能というわけではありません。以下のケースでは他の手法を選んだ方がよいです。
「テーブルデータでない」「予測そのものが目的でない」場合は、別の手法を検討するのが正解です。XGBoostは万能ではなく、得意領域があります。
XGBoostは強力なツールですが、誤った使い方で結果が悪くなることもあります。実務で気をつけたい代表的な落とし穴を整理します。
train_test_splitでランダム分割すると未来情報を学習する恐れ。時系列分割(TimeSeriesSplit)を使うscale_pos_weightやクラス重み、AUC・F1での評価が必要max_depth=20などにすると過学習。テーブルデータでは多くの場合4〜8で十分ChatGPTやClaudeのような生成AIが注目される現在でも、XGBoostやLightGBMは古くなったわけではありません。理由は、企業の実務データの多くが、売上、顧客属性、利用履歴、センサー値、決算数値のようなテーブルデータだからです。
画像・音声・文章そのものを扱うならディープラーニングやLLMが強い一方、行と列で整理されたデータから「解約するか」「売上が伸びるか」「不正かどうか」「与信が通るか」を予測する用途では、今でも勾配ブースティング系が有力です。むしろ実務では、LLMで特徴量や説明文を作り、XGBoostで予測するようなハイブリッド構成も考えられます。
「生成AI時代だからXGBoostを学ぶ意味はないのでは」と感じる必要はありません。LLM、画像生成、検索AIなどとは守備範囲が違うため、テーブルデータが業務にある限りXGBoostの価値は続きます。むしろ、AI時代の機械学習エンジニアには、両方を使い分けるスキルが期待されます。
勾配ブースティング自体は10年以上の歴史を持つ枯れた手法ですが、周辺技術は変化が続いています。2026年後半に注目される動向を整理します(あくまで一つの見方です)。
決定木とランダムフォレストの基本を理解しておくと、XGBoostの仕組みがすんなり入ります。「決定木→アンサンブル学習(バギング)→ランダムフォレスト→ブースティング→XGBoost」という流れで段階的に学ぶのがおすすめです。本サイトのランダムフォレスト解説記事も合わせて読むと理解が深まります。
初学者にはXGBoostをおすすめします。理由は「日本語の入門記事・本・チュートリアルが豊富」なこと。つまづいたときに調べやすく、学習効率が高いです。XGBoostに慣れたあとでLightGBMを試すと、共通概念が多いのでスムーズに移行できます。
テーブルデータでは依然として勾配ブースティングが優勢です。理由は「データ量が少なくても高精度」「学習が速い」「解釈しやすい」「ハイパーパラメータが少ない」など実用面の利点が多いから。画像・テキスト・音声はディープラーニング、テーブルデータはXGBoost/LightGBM、というのが2026年時点の実務的な使い分けです。
使えますが、特徴量エンジニアリングが鍵になります。ラグ特徴量(過去N日の値)、移動平均、差分、季節性、外部要因(祝日、イベント等)を特徴量として作成し、それをXGBoostに渡す形が一般的です。生の時系列予測専用ならProphet・LSTM・Transformer系の方が手間が少なく、ハイブリッドな構成も多く採用されます。データ漏洩には特に注意(未来情報を特徴量に含めない)。
必須ではありませんが、推奨はします。理由は「GridSearchCVより試行が効率的」「コード量が少ない」「並列化や枝刈り(Pruning)が組み込まれている」から。ただし、Optunaを使う前に手動で5〜10パターン試してパラメータの効き方を体感するのがおすすめです。理屈を理解しないまま自動化に頼ると、結果の解釈ができなくなります。
学習済みモデルをmodel.save_model("model.json")またはjoblib.dump()で保存し、本番サーバーで読み込んで推論する形が基本です。前処理(カテゴリエンコーディング、特徴量作成)も本番で再現できるようパイプライン化(scikit-learn Pipeline、MLflow、BentoML等)するのが安全です。本番性能の継続的なモニタリング(データドリフト検出)も忘れずに。
XGBoostは2014年ごろから普及し、2016年の代表論文以降、テーブルデータに対する機械学習の定番手法として使われ続けています。最後にこの記事のポイントをおさらいします。
これから学ぶ方には、「ランダムフォレストで感覚をつかむ → XGBoostで精度を上げる → Optunaでチューニング → SHAPで解釈」のステップが、もっとも効率的な学習順序です。コツは「万能の1モデル」を探すより「ベースラインから着実に積み上げる」発想に切り替えること。それが2026年の機械学習との向き合い方の基本です。
ルミィ:「Kaggleで強いと聞いて怖かったけど、ランダムフォレストの『次のステップ』として捉えればちゃんと理解できそう!」
📚 機械学習入門シリーズ(全6回)
🧭 もっと広い地図で眺める:この手法は機械学習という大きな地図の一部です。教師あり・教師なし・強化学習という全体像や、クラスタリング・PCA・過学習・評価指標といった“使いこなし”は、連載「機械学習の地図」(概念編・全5回)で図解しています。
🧩 仕組みの根っこを知る:XGBoost(勾配ブースティング)は「アンサンブル学習」の代表例です。なぜ弱い学習器をたくさん束ねると強くなるのか——その背骨の考え方(バギングとブースティングの違い)は、アンサンブル学習とは?で図解しています。