平均・中央値・最頻値とは?違いと使い分けをやさしく図解
ルミィ
AIの歩き方
「練習問題は全部解けたのに、本番のテストはボロボロ」——勉強でよくある失敗ですが、AIもまったく同じ落とし穴にはまります。それが過学習(オーバーフィッティング)です。
機械学習でいちばん大事といっても過言ではないのが、この過学習との付き合い方です。決定木の剪定も、ディープラーニングの学習の工夫も、突き詰めればこの過学習を防ぐためにあります。この記事では、過学習とは何か、なぜ起きるか、どう防ぐかを図でやさしく整理します。
🧭 連載「機械学習の地図」(全5回)
線形回帰や決定木の“その先”——機械学習の全体像と、回帰・木以外の代表的な考え方を、順番にやさしくたどる連載です。

AIの賢さは「覚えた量」じゃなくて「初めて見る問題に通用するか」で測るんだ。ここが過学習のキモだよ。
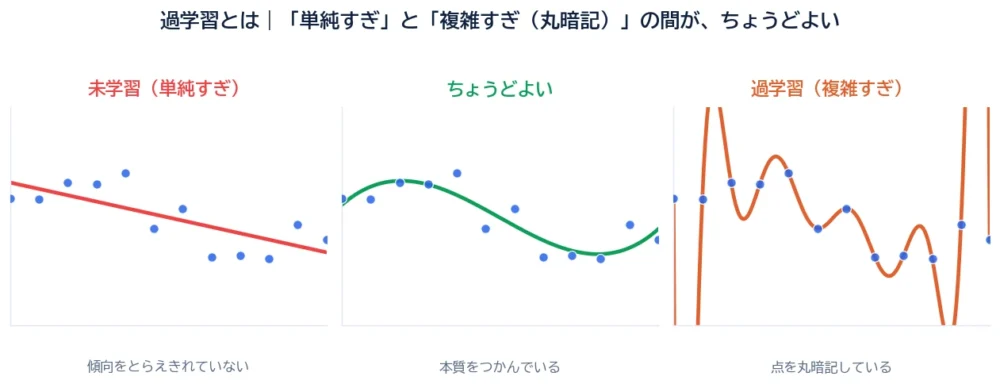
過学習とは、学習に使ったデータに合わせすぎて、見たことのない新しいデータでうまく予測できなくなる状態です。図の右端のように、すべての点を無理やり通ろうとして、線がぐにゃぐにゃに暴れているのが過学習のイメージです。
一方、図の左端は逆の失敗で、未学習(学習不足)。線が単純すぎて、データの傾向すらとらえられていません。そして真ん中が、ちょうどよい状態。細かい点には完璧に合わせていませんが、データの“本質”をなめらかにつかんでいます。
AIに求めたいのは、この真ん中です。練習問題(学習データ)の丸暗記ではなく、初めて見る問題(新しいデータ)に通用する力——これを汎化(はんか)能力と呼びます。
過学習が起きる原因は、主に2つです。
「賢いモデルを使えば使うほど良い」とは限らないのが、機械学習の面白くも難しいところ。問題の難しさに対して、ちょうどよい複雑さを選ぶことが大切です。
過学習に気づくには、学習に使うデータと、評価に使うデータを分けるのが鉄則です。
もし「訓練では高得点なのに、テストでは低得点」なら、それは過学習のサインです。練習問題は丸暗記できているのに、初見の問題に弱い、という状態だからです。この差を見張ることが、過学習対策の出発点になります。
過学習を防ぐ工夫は、効く順に覚えておくと役立ちます。
ディープラーニングでよく聞くドロップアウト(学習中にわざと一部のニューロンを休ませる)も、③の正則化の仲間です。どれも「真面目に覚えすぎない」ためのブレーキ、と捉えると分かりやすいです。
①の「データを増やす」は理想ですが、現実には集めるのが大変です。そこで画像なら、写真を少し回転・反転させたり明るさを変えたりして“水増し”するデータ拡張(データオーグメンテーション)がよく使われます。同じ猫の写真でも向きや明るさが変われば、AIには別の例に見える——こうして手持ちのデータから学びを引き出すのも、過学習対策の実用的な一手です。
訓練とテストを1回分けるだけだと、「たまたまその分け方だと成績が良かった(悪かった)」という運の影響を受けます。これをならすのが交差検証(クロスバリデーション)です。
いちばん使われるk分割交差検証は、こんな段取りです。
こうすると、すべてのデータが1度はテスト役を務めるので、1回きりの分け方より公平に実力を測れます。「この前は良かったのに今回はダメ」というブレに振り回されなくなるのが利点です。
過学習や未学習は、学習曲線というグラフで見抜けます。データ量や学習回数を横軸に、訓練とテストの成績を縦軸にとって眺めるのです。
「成績が悪い」と一括りにせず、訓練とテストの“差”を見て原因を切り分ける。これができると、次に打つ手(データを増やすのか、モデルをいじるのか)が決まります。
過学習・未学習は、バイアスとバリアンスという言葉でも語られます。少し専門的ですが、知っておくと見通しがよくなります。
この2つはシーソーの関係で、片方を下げるともう片方が上がりがち。両方をいい塩梅にする“ちょうどよさ”を探すのが、機械学習のチューニングの本質です。図の真ん中を狙う作業、と言い換えてもいいでしょう。
過学習対策の定番「正則化」には、よく使う2種類があります。名前だけでも知っておくと、解説記事がぐっと読みやすくなります。
「とりあえず効かせたいならL2、項目を絞り込みたいならL1」が大まかな目安。どちらも“モデルが複雑になりすぎるのにブレーキをかける”点は共通しています。
過学習の感覚は、想像実験で一番つかめます。20個の点(うっすら右上がりだが、ノイズでガタガタ)を、3つのモデルで学ばせてみましょう。
面白いのは、訓練データだけ見ると「全点を通る線」が一番優秀に見えること。誤差ゼロですから。でも本当に賢いのは真ん中です。「訓練での満点」に飛びつくと過学習にだまされる——この直感を持っておくと、現場で役立ちます。
ちなみに、ランダムフォレストのように「たくさんのモデルの多数決をとる」アンサンブルも、1本ごとの過学習を打ち消し合って結果を安定させる工夫の一つです。過学習対策は、設定(正則化)だけでなく、モデルの組み方そのものにも組み込まれています。
過学習は、学習データに合わせすぎて、新しいデータで通用しなくなる状態です。AIの賢さは「覚えた量」ではなく「初めて見る問題に通用するか(汎化能力)」で測ります。
防ぎ方は一つではありません。データを増やす、モデルを単純にする、L1・L2正則化でブレーキをかける、早期終了する、交差検証で公平に測る、アンサンブルで打ち消し合う——どれも「真面目に覚えすぎない」ための工夫です。そして何より、訓練とテストを分け、その“差”を学習曲線で見張ること。これが過学習と付き合う第一歩になります。
過学習を意識できるようになると、機械学習の見方がひとつ深まります。「訓練データで満点」を素直に喜ばず、「本番(初見のデータ)でも通用するか」をいつも問う——この一歩引いた視点こそ、個々の手法の名前以上に、長く役立つ財産になります。
訓練とテストを分けて差を見張り、データを増やす・モデルを単純にする・正則化する、といった工夫で“ちょうどよさ”を探す。これは決定木からディープラーニングまで、あらゆる機械学習に共通する、いちばん大切な考え方です。
過学習=練習を丸暗記して本番で外す。未学習=単純すぎて的外れ。
狙うのは真ん中(汎化能力)。
訓練とテストを分けて見張り、データ増・単純化・正則化で防ぐ。
最終回は、その「本番で通用するか」をどう数字で測るか——モデルの評価指標に進みます。
A. 学習に使ったデータに合わせすぎて、見たことのない新しいデータでうまく予測できなくなる状態です。練習問題を丸暗記して本番のテストで失敗するのに似ています。AIの賢さは初めて見る問題への対応力(汎化能力)で測ります。
A. 主に、モデルが複雑すぎてデータのノイズまで覚えてしまう場合と、データが少なすぎて限られたパターンを丸暗記してしまう場合です。問題の難しさに対してちょうどよい複雑さを選ぶことが大切です。
A. 学習に使う訓練データと、評価用のテストデータを分けるのが基本です。訓練では高得点なのにテストでは低得点なら、過学習のサインです。この差を見張ることが対策の出発点になります。
A. データを増やす、モデルを単純にする(決定木の剪定など)、正則化(L1・L2)、早期終了、交差検証などです。ディープラーニングのドロップアウトも正則化の仲間で、どれも『真面目に覚えすぎない』ためのブレーキです。
A. 過学習の逆で、モデルが単純すぎてデータの傾向すらとらえられていない状態です。練習問題でも本番でも成績が低くなります。モデルを少し複雑にする、特徴量を増やすなどで改善します。
A. 重みが極端に大きくなるのを抑えて、モデルが複雑になりすぎないようにする工夫です。L1正則化やL2正則化が代表で、過学習を防ぐブレーキとして広く使われます。
A. バイアスが高いと単純すぎて的を外す(未学習)、バリアンスが高いと複雑すぎてデータごとにブレる(過学習)状態です。この2つはシーソーの関係で、両方をちょうどよくする点を探すのが機械学習のチューニングの本質です。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わるため、実務では各手法の前提条件もご確認ください。