Attention(自己注意)とは?AIが文脈を読む仕組みをやさしく解説
ルミィ
AIの歩き方

前回のニューラルネットワークで、AIの中身は「大量の重み」だと分かりました。でも最初、その重みはランダムなでたらめ。そこから賢くしていく作業が学習(トレーニング)です。
学習の正体は、「予測してみる → 答えと比べて間違いを測る → 重みを少し直す」をひたすら繰り返すこと。この記事では、その繰り返しを支える2つの主役、勾配降下法と誤差逆伝播を、図でやさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

AIの学習って、実は「間違えて、ちょっと直す」を何百万回もやってるだけなんだ。
AIの学習は、人が問題集を解いて答え合わせをするのに似ています。
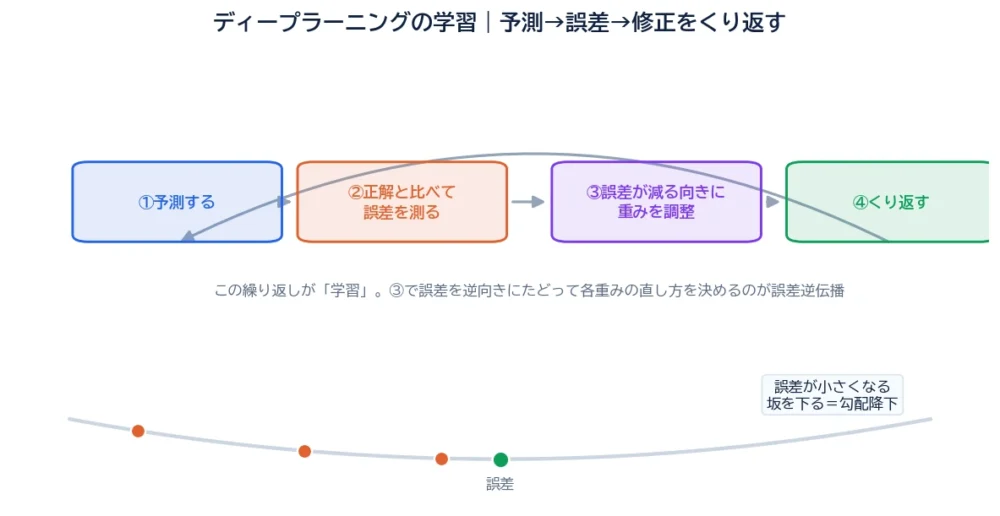
この地道なループだけで、AIはだんだん正解に近づいていきます。
②の「どれだけ間違えたか」を数値にするのが損失関数です。予測と正解のズレが大きいほど損失は大きく、ぴったり当たれば損失は小さくなります。
学習のゴールは、ひとことで言えば「この損失をできるだけ小さくする重みを見つけること」。あとは、どうやって小さくするか、です。
損失を小さくする方法が勾配降下法です。イメージは、霧の中で山を下りること。いまいる場所で「どっちが下り坂か」だけを調べ、その向きへ一歩進む。これを繰り返せば、いつか谷底(損失が小さい場所)にたどり着きます。
「下り坂の向き」にあたるのが勾配で、各重みを「どっちにどれだけ動かせば誤差が減るか」を表します。一歩の大きさは学習率と呼ばれ、大きすぎると行き過ぎ、小さすぎると進みが遅い、というちょうど良さが大事です。
勾配降下法=「いまの場所で一番の下り坂へ、少しずつ進む」。これを何度も繰り返して、誤差の谷底を目指す。
ニューラルネットには重みが大量にあります。その一つひとつについて「動かすと誤差がどう変わるか」を、どうやって求めるのでしょう。それが誤差逆伝播(バックプロパゲーション)です。
名前のとおり、出力で出た誤差を、出口から入口へ“逆向き”にたどっていく仕組みです。最後の層の誤差から、その手前の層、さらに手前——と責任を割り振るように計算することで、すべての重みの「直す向きと量」を効率よく求められます。
勾配降下が「下る」、誤差逆伝播が「どっちが下りかを全部の重みについて計算する」。この2つがセットで、ディープラーニングの学習は回っています。
| 言葉 | 意味 |
|---|---|
| エポック | 用意した学習データを一通り全部使い切る回数。何周も回す |
| バッチ | 一度にまとめて処理するデータのかたまり。少しずつ重みを更新する |
| 学習率 | 重みを動かす一歩の大きさ。大きすぎても小さすぎてもうまくいかない |
| 損失 | 予測と正解のズレ。これを小さくするのが目的 |
学習を進めすぎると、AIが練習問題の答えを丸暗記してしまうことがあります。これを過学習(オーバーフィッティング)と呼びます。練習では満点なのに、本番(見たことのないデータ)でズタボロ、という状態です。
対策は、学習に使わないデータで時々テストして「本番でも通用するか」を確かめること。AIの賢さは、覚えた量ではなく「初めて見る問題に通用するか」で測ります。
丸暗記を防ぐ工夫もあります。学習中にわざと一部のニューロンを休ませるドロップアウトや、重みが極端に大きくならないよう抑える正則化など。どれも「真面目に覚えすぎない」ためのブレーキだと考えると分かりやすいです。
ここを混同しがちなので整理します。AIには学習(トレーニング)と推論(インファレンス)の2つの時間があります。
つまり、私たちが日々使っているAIは、もう学習が終わって重みが固定された状態です。だから、その場の会話でモデル自体が賢くなるわけではありません(覚えてほしいことは、毎回プロンプトやRAGで渡す必要があります)。
学習は、いつもきれいに進むわけではありません。代表的なつまずきを知っておくと、ニュースの理解も深まります。
「データと計算をたくさん使えば賢くなる」と言われますが、その裏では、こうした地味なつまずきを一つずつ乗り越える工夫が積み重なっています。
学習の1回転を、ダーツの練習にたとえてみます。中心(正解)を狙って投げる人が、AIです。
ここで大事なのが直し方の“さじ加減”(学習率)。一投ごとにフォームをガラッと変えたら、毎回あらぬ方向へ暴れて上達しません。逆に、ほんの少しずつしか直さなければ、上達はするけれど時間がかかる。少しずつ、でも着実に——これが勾配降下の心です。
そして「練習場(学習データ)では百発百中なのに、本番の大会(初めてのデータ)ではボロボロ」が過学習。練習の点数ではなく、本番で通用するかを見て調整する——AIの学習も、上達の考え方は人間とよく似ています。
「少しずつ直す」と聞くと地道ですが、その回数とデータ量が桁違いです。大きなLLMの事前学習では、何兆もの単語を読み込み、何週間〜何か月もかけて、膨大な数の重みを調整し続けます。電気代だけで数億円規模、という話も珍しくありません。
だからこそ、巨大なモデルをゼロから学習できるのは、潤沢な計算資源を持つ一部の企業に限られます。私たち個人がやるのは、もっぱら次の2つです。
「学習はとてつもなく重い、でも“使う”のは軽い」。この非対称さが、AIが一部の企業で作られ、世界中の人に使われる、という今の構図を生んでいます。
個人や中小の現場でも、AIを“自分用”に賢くする道はあります。それがファインチューニング(追加学習)です。ゼロから巨大モデルを作るのではなく、すでに学習を終えた優秀なモデルを土台に、自分のデータで少しだけ学習し直す——いわば「できあがった人材に、自社の仕事を覚えてもらう」やり方です。
土台がすでに賢いので、少ないデータと計算で、特定の用途(自社の文体、専門分野の言い回しなど)に寄せられます。とはいえ、これにもコツと注意があります。
この「学習させる」と「その場で渡す」の使い分けは、RAGとは?でも詳しく整理しています。学習の仕組みを知っておくと、どちらを選ぶべきかの判断もぶれません。
ディープラーニングの学習は、「予測→誤差→修正」の地道な繰り返しです。損失関数で間違いを測り、勾配降下法で誤差が減る向きへ重みを少しずつ動かし、誤差逆伝播でその向きを全重みについて効率よく計算します。派手な魔法ではなく、間違えては少し直す、を気が遠くなるほど繰り返すだけ。その地道さの積み重ねが、AIの“賢さ”の正体です。仕組みを知ると、AIが万能でも魔法でもなく、データと計算の上に立つ技術だと腑に落ちます。
学習=損失(誤差)を小さくする重みを探す作業。
勾配降下で「下り坂」を下り、誤差逆伝播で「どっちが下りか」を逆算する。
やりすぎる丸暗記(過学習)には注意。
土台はここまで。次回からは、この仕組みを言語向けに進化させた本命——Transformerに入ります。
A. ニューラルネットワークの大量の重みを、正解に近づくように少しずつ調整していく作業です。「予測する→誤差を測る→重みを直す」を膨大な例で繰り返し、だんだん賢くしていきます。
A. 誤差が小さくなる方向(下り坂)へ、重みを少しずつ動かしていく方法です。霧の中で山を下るように、その場で一番の下り坂を調べて一歩進む、を繰り返して誤差の谷底を目指します。
A. 出力で出た誤差を、出口から入口へ逆向きにたどって、各重みを「どっちにどれだけ動かせば誤差が減るか」を効率よく求める仕組みです。勾配降下とセットで学習を支えます。
A. 重みを一度にどれだけ動かすか、という一歩の大きさです。大きすぎると行き過ぎてうまく収束せず、小さすぎると学習が遅くなります。ちょうど良い値の調整が重要です。
A. 学習データを丸暗記してしまい、見たことのないデータでうまく予測できなくなる状態です。学習に使わないデータでの検証や、正則化などの工夫で防ぎます。
A. 規模によります。小さなモデルなら数分〜数時間ですが、大きなLLMの事前学習は何兆もの単語を読み込み、何週間〜何か月もかかることがあります。一方、学習済みモデルを使う「推論」は一瞬で、私たちが普段使うのはこちらです。
A. 用意した学習データを一通り全部使い切る回数のことです。1エポックでデータを1周し、これを何周も繰り返して少しずつ重みを調整します。多すぎると過学習、少なすぎると学習不足になりやすいです。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。
🧠 もっと具体的に知る:ニューラルネットは、目的に応じて“配線”を変えることで力を発揮します。画像のCNN、系列のRNN・LSTM、生成のGAN・拡散モデルといった代表的なアーキテクチャは、連載「ディープラーニングの地図」(アーキ編・全5回)で図解しています。