
生成AIと従来AIの違いとは?「作るAI」と「判断するAI」をやさしく解説【2026年版】
ルミィ
AIの歩き方
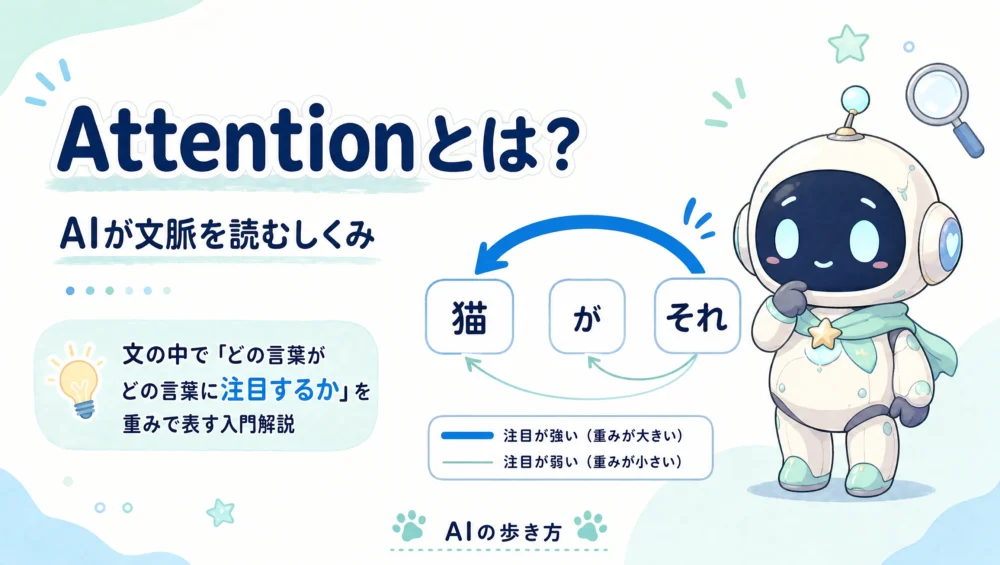
前回のTransformerの心臓部にあるのが、今回のAttention(アテンション/自己注意)です。Transformerの原論文のタイトルが「Attention Is All You Need(必要なのはAttentionだけ)」だったほど、これが現代AIの核心です。
Attentionを一言でいうと、「文の中で、どの言葉がどの言葉に注目すべきかを、重みで決める仕組み」。これがあるおかげで、AIは“文脈を読む”ことができます。図でやさしく見ていきましょう。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

「それ」が何を指すか——人間が無意識にやってる文脈読み。AIはAttentionでこれをやってるんだ。
文章を理解するには、言葉どうしのつながりを捉える必要があります。「猫が寝ている。それはかわいい」という文で、「それ」が指すのは「猫」ですよね。人間は無意識にこの結びつきを読みますが、AIにとっては簡単ではありません。
Attentionは、各言葉が「自分は文中のどの言葉に、どれだけ注目すべきか」を数値(重み)で計算します。
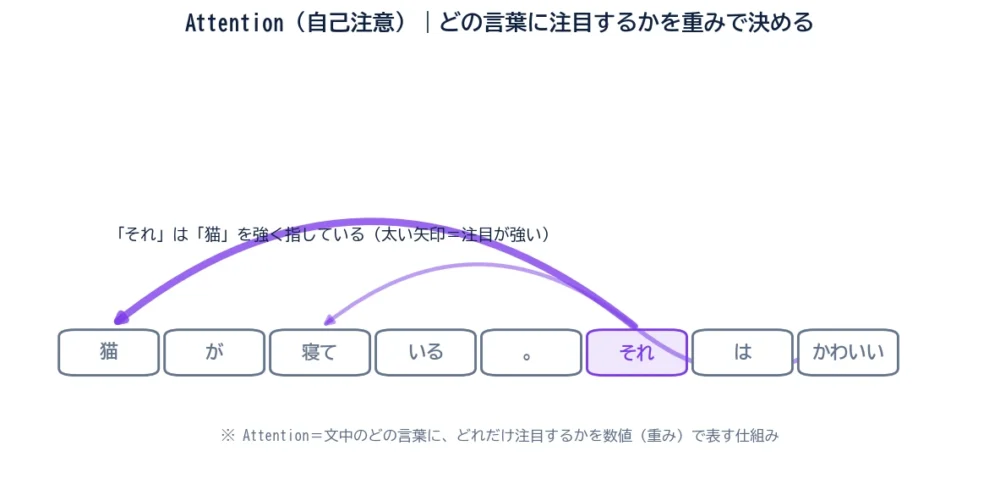
図のように、「それ」は「猫」に強く注目し(太い矢印)、ほかの語には弱く注目します。この強弱の重みづけによって、AIは「それ=猫」という文脈を捉えられるのです。
Transformerで使われるのは自己注意(セルフアテンション)です。「自己」とは、同じ文の中の言葉どうしが、互いに注目し合うという意味。外から別の情報を持ってくるのではなく、文の内部の関係を、文自身の中で解き明かします。
しかもこれを全部の語について同時に計算します。だから「離れた場所にある関係」も一足飛びに捉えられる——これがTransformerが長文に強い理由の中身です。
Attentionは、内部でQuery(クエリ)・Key(キー)・Value(バリュー)という3つの役割を使います。図書館の検索にたとえると分かりやすいです。
流れは、QueryとKeyを照合して「どれが近いか(注目度)」を計算し、その重みに応じてValueを混ぜ合わせる。「それ」のQueryが「猫」のKeyと強く合うので、「猫」のValueを多めに取り込む——という具合です。
Attention=「知りたいこと(Query)」で「見出し(Key)」を探し、合った相手の「中身(Value)」を重みづけで取り込む仕組み。
実際のTransformerは、Attentionを複数同時に走らせます。これをマルチヘッドアテンションと呼びます。
ある“ヘッド”は文法的なつながり(主語と動詞)に、別のヘッドは意味的なつながり(代名詞と指す相手)に注目する、というように、複数の観点を並行して捉える。人が文章を、文法・意味・文脈と多面的に読むのに似ています。
従来の方式が苦手だった「離れた語どうしの関係」を、Attentionは距離に関係なく直接つかめます。文の最初の主語と、最後の動詞の関係も一発。長い文章でも文脈を保てるのは、この性質のおかげです。
「必要なのはAttentionだけ」というタイトルは大げさに聞こえますが、この仕組み一つで、AIの言語理解は劇的に進んだのです。
Attentionには弱点もあります。全部の語が全部の語に注目し合うので、文章が長くなるほど計算量が急に増えるのです。語数が2倍になると、組み合わせは約4倍。長い文書を一度に扱うと、それだけ重く・高くなります。
「コンテキストウィンドウ(一度に扱える長さ)」に上限があり、長文の処理が高くつきがちなのは、この性質が大きな理由です。だから各社は、Attentionを軽くする工夫(必要な範囲だけ見る、近似する、など)をしのぎを削って開発しています。“長い文脈に強い新モデル”というニュースの裏側は、たいていここの改善です。
Attentionの面白いところは、「どの語がどの語に注目したか」の重みを取り出して眺められることです。これをヒートマップにすると、AIが文のどこを手がかりにしたかが、うっすら見えてきます。
たとえば翻訳で、出力した単語が入力のどの単語に強く注目したかを見ると、訳語の対応が浮かび上がります。AIの中身はブラックボックスになりがちですが、Attentionは“中をのぞく数少ない窓”として、研究でもよく使われます。
今回の主役は文が自分自身に注目する「自己注意」でしたが、別の文や別の情報に注目する使い方もあります。これをクロスアテンションと呼びます。
たとえば翻訳では、出力中の日本語が、入力の英語のどの部分に注目するかをクロスアテンションで捉えます。画像の説明文を作るときに、文が画像の特定の場所に注目する、といった使い方も同じ発想です。「どこに注目するか」を重みで決める——この一貫した考え方が、いろいろな場面で効いています。
Query・Key・Valueが少し難しければ、会議室での情報集めにたとえてみましょう。各言葉が、会議室にいる参加者です。
関係が浅い人の話は小さく、深い人の話は大きく聞く。この“聞く配分”が注目の重みです。しかも全員が同時にこれをやって、互いの関係を一気に整理する——それが自己注意です。
人間も、長い文章を読むとき、無意識に「この“彼”はさっきの誰だっけ」と前を振り返りますよね。AIはそれを、すべての語の組み合わせについて、計算で一気にやっている。人間の“文脈を追う”を機械にしたのがAttentionだと思うと、ぐっと腑に落ちます。
Attention以前のAIは、長い文を読むうちに前半を忘れていく“健忘症”のようでした。「最初に出てきた人物が、最後の文でどうなったか」をつなげるのが苦手だったのです。
Attentionは、この壁を取り払いました。文のどこにある語とも、距離に関係なく直接つながれる。おかげでAIは、長い文章でも一貫性を保って読み書きできるようになりました。具体的には、こんなことが一気に上達しています。
私たちがChatGPTと長い相談をしても話がかみ合うのは、その根っこにこのAttentionがあるから。「文脈を読む」というAIらしさの正体が、この仕組みなのです。
Attention(自己注意)は、文の中で「どの言葉がどの言葉に注目すべきか」を重みで決める仕組みです。Query・Key・Valueで関係を計算し、離れた語どうしの結びつきも直接捉えます。これがTransformer、そして現代LLMの核心です。
少し専門的な言葉が並びましたが、本質は「文脈を読むために、関係の深い言葉ほど強く注目する」という、とても人間的な発想です。私たちが文章を読むときに無意識でやっている“前を振り返る・つながりを追う”を、計算で一気にやってのける——それがAttention。AIが文脈を理解しているように見える、その理由の中心が、ここにありました。仕組みのいちばん深いところまで来たので、次回からは、これらを使って実際にLLMを組み上げる話に移ります。
Attention=言葉どうしの「注目の重みづけ」。
Query(知りたい)でKey(見出し)を探し、Value(中身)を取り込む。
離れた語の関係も一発。だからAIは文脈を読める。
仕組みの土台はここまで。次回は、これらを使って実際にLLMを作る手順——事前学習・ファインチューニング・RLHFに進みます。
A. 文の中で、どの言葉がどの言葉に注目すべきかを数値(重み)で決める仕組みです。これにより、AIは「それ」が何を指すかといった文脈上の結びつきを捉えられます。Transformerの中核技術です。
A. 同じ文の中の言葉どうしが互いに注目し合うAttentionのことです。外部から情報を持ってくるのではなく、文の内部の関係を文自身の中で解き明かします。
A. Attentionの内部で使う3つの役割です。Query(知りたいこと)でKey(各語の見出し)を照合し、合った相手のValue(中身)を重みづけで取り込みます。図書館で見出しを探して中身を読むイメージです。
A. Attentionを複数同時に走らせる仕組みです。あるヘッドは文法、別のヘッドは意味、というように複数の観点で並行して関係を捉えるため、より豊かに文脈を読めます。
A. 従来の方式が苦手だった「離れた語どうしの関係」を、距離に関係なく直接捉えられるからです。長い文章でも文脈を保てるようになり、現代のLLMの言語理解を大きく前進させました。
A. QueryとKeyの照合で決まります。いまの語が「知りたいこと(Query)」を出し、ほかの語の「見出し(Key)」と照らし合わせて、合致する度合いが高いほど大きな重み(注目)になります。その重みに応じて各語の中身(Value)を取り込みます。
A. AttentionはTransformerという特別なニューラルネットワークの中核部品です。ニューラルネットワークという大きな枠組みの中で、語どうしの関係を捉える役割を担うのがAttentionです。
A. 複数のAttentionを同時に走らせることで、文法・意味・指示語の対応など、異なる観点の関係を並行して捉えられます。一つの視点だけで読むより、豊かに文脈を読めるのが利点です。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。





