LLM(大規模言語モデル)とは?ChatGPTの心臓部をやさしく解説【2026年版】
ルミィ
AIの歩き方

ChatGPTに文章を送ると、AIはその文字をそのまま読んでいる——と思いがちですが、実は違います。AIはまず文章をトークンという小さな単位に切り分け、それを数値に置き換えてから処理しています。
この「トークン」は、料金(APIの課金)も、一度に扱える文章の長さ(コンテキストウィンドウ)も、すべてこの単位で数えられる、地味だけどとても大事な概念です。
この記事では、トークンの正体、なぜ文章をわざわざ分けるのか、日本語がちょっと損をしやすい理由、そして「いちごのrは何個?」にAIが間違える理由まで、やさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。この記事は第1回。

AIは文字じゃなくて「トークン」で世界を見てるんだ。ここが分かると、料金もコンテキストも腑に落ちるよ。
トークンとは、AIが文章を処理するときの最小の単位です。ざっくり言うと「単語」に近いのですが、ぴったり単語というわけではありません。
英語の例で見てみましょう。tokenization という単語は、多くのAIで token + ization のように2つ以上のかたまりに分かれます。よく使われる token は1つのトークン、あまり出てこない長い単語は複数のトークンに割れる——こんなふうに、「よく出てくるかたまりは1トークン、珍しいものは細かく分ける」のがいまの主流です。
この「単語より小さいこともある単位」を、専門的にはサブワード(部分語)と呼びます。

日本語は、英語のように単語が空白で区切られていないので、もっと細かく分かれることが多いです。たとえば「私はAIが好き」は、「私/は/AI/が/好き」のように、文字や短いかたまりに切られていきます。
理由はシンプルで、コンピューターは文字そのものを計算できないからです。AIの中身は膨大なかけ算と足し算なので、文章も最終的には数値にしないと処理できません。
そこで、こんな流れになります。
つまりトークン化は、「文章を数値の列に変える、いちばん最初の一歩」。ここを通らないと、AIは文章を1文字も処理できません。
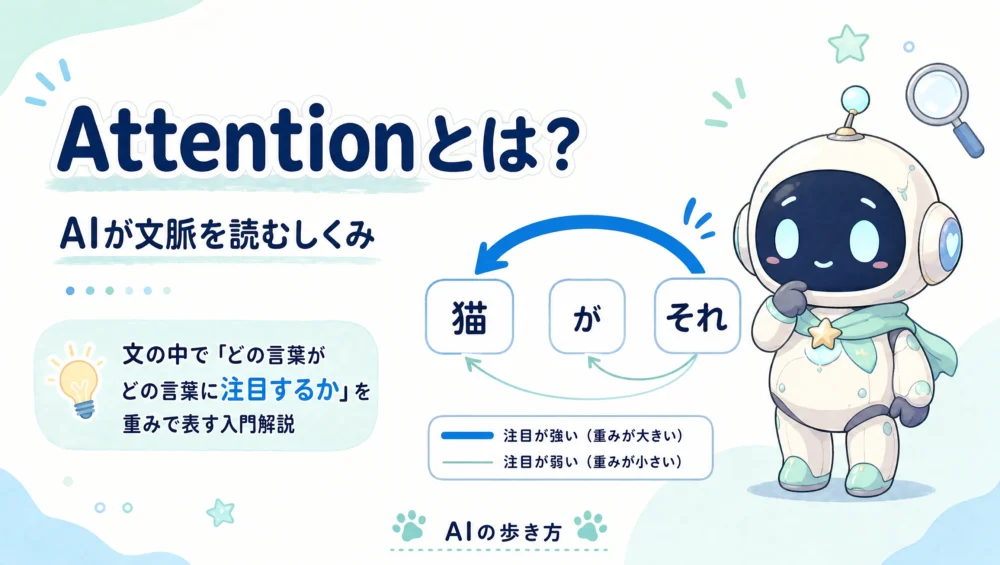
この続き——番号をどう「意味のある数値」にするのか——は、連載第2回の埋め込み(ベクトル化)とはで扱います。
トークンの分け方にはいくつか方式がありますが、いま広く使われているのはBPE(バイト・ペア・エンコーディング)という考え方をベースにしたものです。仕組みは直感的です。
tとh)を見つけて、1つのかたまり th にまとめるthe・ing・tion のような「頻出パーツ」を育てていく結果として、よく使う言葉ほど少ないトークンで表せて、珍しい言葉は細かく分かれる、という効率の良い辞書ができあがります。新語や打ち間違いのような未知の言葉も、細かいパーツの組み合わせで必ず表現できるのが強みです。
ポイントは、トークン化は「賢い分割」ではなく「頻度にもとづく機械的な分割」だということ。意味を理解して切っているわけではありません。
トークンが分かると、AIを使ううえでの2つの実用的な数字が腑に落ちます。
APIの料金は「1文字いくら」でも「1単語いくら」でもなく、トークン数で計算されます。入力したトークン+AIが出力したトークンの合計で課金される、というのが基本の形です。長い文章を貼るほどトークンが増え、その分コストも上がります。
「このAIは128Kトークンまで扱えます」のような表記を見たことがあるはずです。これは一度に読み書きできる長さの上限で、これもトークンで数えます。会話が長くなって上限に近づくと、AIが古い部分を忘れていくのは、このトークンの枠を超えるからです。
目安として、英語ではおおよそ「1トークン=4文字前後/100トークン=75語ほど」とよく言われます。ただし言語や内容で変わるので、あくまで感覚値です。
ここは日本語ユーザーとして知っておくと得な話です。同じ内容でも、日本語は英語よりトークン数が多くなりやすい傾向があります。
理由は、多くのAIのトークン辞書が英語中心に作られていて、日本語は文字単位や短いかたまりに細かく割れやすいから。結果として、同じことを伝えるのに、
とはいえ近年のモデルは日本語の扱いも改善しています。「日本語は構造的にトークンを食いやすい」と頭の片隅に置いておけば、長い資料を貼るときの目安になります。
「strawberry の r は何個?」とAIに聞くと、堂々と間違えることがあります。これは知能が低いからではなく、トークン化の副作用です。
AIは strawberry を1文字ずつの s-t-r-a-w-... として見ているのではなく、straw + berry のようなトークンのかたまりとして見ています。だから「文字を1個ずつ数える」作業が、人間ほど得意ではないのです。
対策はかんたんで、「1文字ずつスペースで区切って」と頼むか、文字数え・しりとり・逆さ読みのような「文字単位の細かい操作」は、AIに丸投げせず確認する。仕組みを知っていれば、得意・不得意の境目が見えてきます。
AIが文字数えを外すの、バカだからじゃなくて「文字じゃなくてトークンで見てるから」なんだよ。
理屈よりも、一度自分の目で見るのが早いです。OpenAIなどが公開しているトークナイザーの可視化ツールに文章を貼ると、どこで区切られて何トークンになるかが色分けで見えます。
一度この「区切られ方」を見ておくと、料金やコンテキストの話がぐっと具体的になります。
トークンの仕組みが分かると、料金とコンテキストを節約する手も見えてきます。長い文章を扱う人ほど効きます。
これらは単に「ケチる」ためではありません。AIに必要な情報だけを渡すと、答えの精度も上がるからです。余計な文脈は料金を増やすだけでなく、AIにとってのノイズにもなります。トークンを意識することは、そのままAIへの伝え方を磨くことでもあります。
トークン化は、AIが文章を処理するための最初のステップ。文章を「トークン」というかたまりに分け、番号(ID)に変えてから、AIはようやく計算を始められます。
トークン=AIが文章を読む最小単位(単語より小さいことも多い)。
料金もコンテキストの長さも、すべてトークンで数える。
日本語はトークンを多めに使いやすい。文字数えが苦手なのもトークンのせい。
次の一歩は、分けたトークンの番号を「意味のある数値」に変える埋め込み(ベクトル化)。AIの全体像から知りたい人はLLM(大規模言語モデル)とはもどうぞ。
A. AIが文章を処理するときの最小単位です。単語に近いですが、よく出るかたまりは1トークン、珍しい言葉は複数のトークンに分かれる「サブワード(部分語)」が主流です。AIは文章をトークンに分け、番号に変えてから処理します。
A. 言語や内容によりますが、英語ではおおよそ1トークン=4文字前後、100トークン=75語ほどが目安とされます。日本語は文字単位に細かく割れやすく、同じ内容でもトークン数が多くなりがちです。
A. 多くのAIのトークン辞書が英語中心に作られているためです。日本語は文字や短いかたまりに細かく分割されやすく、同じ内容でも英語よりトークン数が増え、料金やコンテキスト消費の面で少し不利になりやすいです。
A. コンテキストウィンドウは「一度に扱える長さの上限」で、トークン単位で数えます。会話が長くなって上限に近づくと、古い部分から忘れていくのは、このトークンの枠を超えるためです。
A. AIは単語を1文字ずつではなく、トークンのかたまりとして見ているためです。そのため「文字を1個ずつ数える」作業が苦手で、文字数え・しりとり・逆さ読みなどは間違えやすくなります。1文字ずつ区切って渡すと改善します。
A. トークン化は「文章を単位に分ける」工程全体を指し、BPE(バイト・ペア・エンコーディング)はその代表的な方式の一つです。よく隣り合うペアを順にまとめて頻出パーツを育てる、効率の良い分割方法として広く使われています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。トークン数の目安や各モデルの仕様は変わることがあるため、料金・上限の正確な値は各サービスの公式情報でご確認ください。