
RNN・LSTMとは?系列データを“覚える”仕組みをやさしく図解
ルミィ
AIの歩き方

ここまでで、文章はトークンに分けられ、意味を表すベクトル(埋め込み)になりました。では、その数値を受け取って実際に「考える」のは何でしょうか。それがニューラルネットワークです。いまのAI——画像認識も、音声も、ChatGPTのような言語AIも——すべてこの仕組みの上で動いています。
名前は難しそうですが、中身は「丸(ニューロン)と線(つながり)でできた網」。この記事では、その丸と線が何をしているのかを、図でやさしくほどいていきます。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

ニューラルネット=丸と線の網。脳のニューロンをうんとシンプルにまねたものなんだよ。
ニューラルネットワークは、ニューロンと呼ばれる小さな計算の単位(図の丸)を、たくさんつないだものです。人間の脳の神経細胞(ニューロン)が信号をやり取りする様子に、ざっくり着想を得ています。
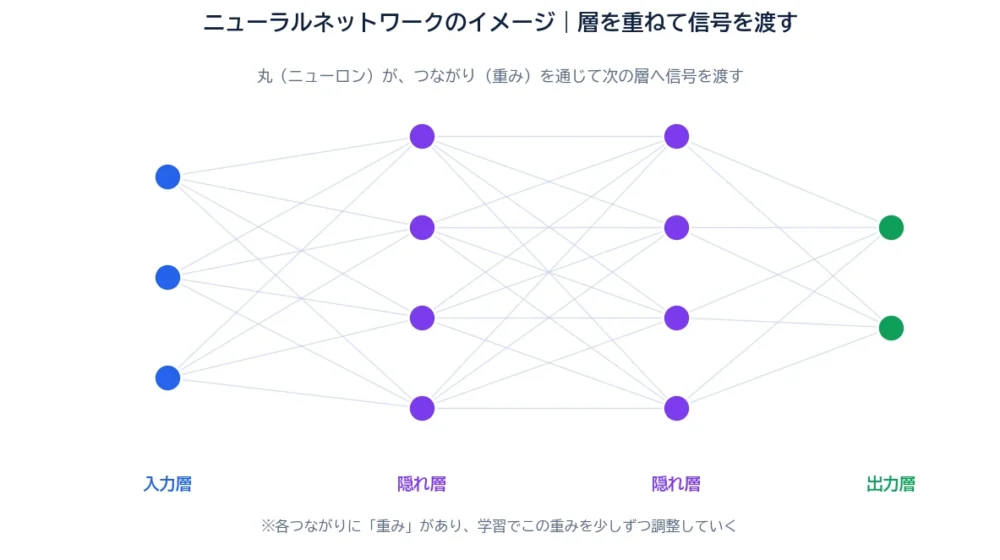
図のように、丸は層(レイヤー)になって並びます。左から、データを受け取る入力層、間で計算する隠れ層、答えを出す出力層。情報は左から右へ、丸から丸へと流れていきます。
1個の丸(ニューロン)の仕事は、意外とシンプルです。
この「重み」こそが、AIが学習で身につける“知識”の正体です。何百万・何億という重みの値の組み合わせで、AIは複雑な判断を表現しています。
②までだと、ただの重み付きの足し算(一次関数)です。それだけを何層重ねても、結局は単純な直線的な判断しかできません。そこで効くのが③の活性化関数です。
活性化関数は、「合計がある値を超えたら強く反応し、低ければ反応しない」のようなひとくせ(非線形性)を加えます。これがあるおかげで、層を重ねるほど曲がりくねった複雑なパターンを表現できるようになります。よく使われるReLU(レルー)は、「マイナスは0、プラスはそのまま」というシンプルな関数です。
活性化関数がないニューラルネットは、何層あっても“ただの直線”。非線形のひとくせが、複雑さを生む源です。
層が浅いネットワークは、単純な判定しかできません。でも層を深く重ねると、前の層が見つけた特徴を、次の層がさらに組み合わせることができます。
画像認識を例にすると、最初の層は「線・点」、次の層は「目・鼻のパーツ」、その次は「顔」——と、だんだん高度な特徴を組み立てていきます。この「層が深い」ニューラルネットを使う学習を、ディープラーニング(深層学習)と呼びます。
では、その大量の「重み」は誰が決めるのでしょう。最初はランダムな値から始まり、たくさんの例を見せて、答えに近づくように少しずつ調整していきます。これが「学習」です。
「予測する → 答えと比べて誤差を見る → 重みを少し直す」をひたすら繰り返す——その具体的な仕組みは、次回のディープラーニングの学習で詳しく見ます。
ニューラルネットワークは、いまのAIのほぼ全部の土台です。
つまり、この「丸と線の網」を深く大きくし、言語向けに工夫を加えたものが、現代のLLMです。
ニューラルネットワークは、扱うデータに合わせて“形”が工夫されています。代表的な3つを知っておくと、AIの記事がぐっと読みやすくなります。
| 種類 | 得意 | ざっくりイメージ |
|---|---|---|
| CNN(畳み込み) | 画像 | 小さな窓をずらしながら、線や形の特徴を拾う |
| RNN / LSTM | 音声・時系列 | 順番に読んで、前の情報を覚えながら進む |
| Transformer | 言語(LLM) | 全体を一度に見て、語どうしの関係を捉える |
どれも「丸と線の網」という土台は同じで、データに合わせて配線を変えているだけ。この連載の主役Transformerも、ニューラルネットワークの一種だと分かれば、全体像がつながります。
ニューラルネットワークには、初心者がつまずきやすい誤解がいくつかあります。先に解いておきましょう。
「賢く見えるけれど、中身は数式の積み重ね」。この距離感を持っておくと、AIと上手に付き合えます。
「重みをかけて足して、活性化関数を通す」を、もう少し身近にしてみましょう。たとえば、「今日は出かけるか?」を決めるニューロンを考えます。
入力は「天気の良さ」「予定の有無」「気分」の3つ。あなたは天気をいちばん重視するなら、天気の入力に大きな重み、気分には小さな重みをかけます。それらを合計して、「ある基準(しきい値)を超えたら出かける、超えなければやめる」——この“超えたらON”の判断が、活性化関数の役割です。
1個のニューロンは、これくらい単純です。すごいのは、この単純な判断を何百万個も重ねると、画像認識や文章生成のような複雑なことができてしまうこと。小さな判断の積み重ねが、全体として高度な知能のように振る舞う——ここがニューラルネットワークの面白さであり、不思議さです。
そして、その“重視の度合い(重み)”や“基準(しきい値)”を、人間が手で決めるのではなく、データから自動で見つけるのが学習です。あなたが経験から「やっぱり天気が大事だな」と学んでいくのに、少し似ています。
ニューラルネットワークの基本アイデア自体は、実はかなり古くからあります(数十年前から研究されていました)。では、なぜここ数年で一気に花開いたのか。理由は、3つの条件が同時にそろったからです。
「アイデアは昔からあったのに、燃料(データ)と火力(計算)と設計図(工夫)が、ようやく出そろった」。いまのAIブームは、突然ひらめいた魔法ではなく、この3つが重なった結果なのです。だから、これらが伸び続けるかぎり、AIもまだ伸びる余地がある——と見られています。
AIのニュースで「700億パラメータのモデル」のような表現をよく見ます。このパラメータとは、まさにこの記事で説明してきた“重み”の数のことです。つながりの数が多いほど、表現できるパターンも増えます。
ざっくり言えば、パラメータ数はモデルの“脳の大きさ”の目安。数億のものから、数千億・数兆におよぶものまであります。一般に、大きいほど賢くなりやすい一方で、
だからこそ、大きなモデルを「軽く・速くする」工夫——蒸留や量子化——が重要になります(連載第8回で扱います)。「パラメータ数=重みの数=脳の大きさの目安」と分かると、モデル比較のニュースがぐっと読みやすくなります。
ニューラルネットワークは、ニューロン(丸)を層状につないだ計算の網です。各ニューロンは「重みをかけて足し、活性化関数を通す」だけ。その重みを学習で調整することで、複雑なパターンを表現します。1個ずつの判断はとても単純なのに、それを層として深く・広く重ねると、画像認識から文章生成まで高度なことができてしまう——この“単純の積み重ねが知能のように振る舞う”ところが、ニューラルネットワークの面白さです。そして、この網を言語向けに磨き上げたものが、次回以降の主役になります。
丸(ニューロン)が、重み付きのつながりで信号を渡す。
活性化関数の非線形性が、複雑さを生む。
層を深く重ねたものがディープラーニング=いまのAIの土台。
次回は、その重みを「どう調整して賢くするか」——ディープラーニングの学習(勾配降下と誤差逆伝播)に進みます。
A. ニューロン(小さな計算単位)を層状にたくさんつないだ仕組みです。各ニューロンは入力に重みをかけて足し、活性化関数を通して次へ渡します。重みを学習で調整することで、画像・音声・言語など複雑なパターンを扱えます。
A. ディープラーニングは、層を深く重ねたニューラルネットワークを使う学習のことです。ニューラルネットワークという仕組みのうち、特に層が深いものを使うのがディープラーニングだと考えるとよいです。
A. ニューロンどうしのつながりの強さを表す数値です。重要な入力ほど大きな重みがかかります。AIが学習で身につける“知識”の正体がこの重みで、何百万〜何億という値の組み合わせで判断を表現します。
A. 活性化関数がないと、何層重ねても直線的な判断しかできません。非線形のひとくせを加えることで、層を重ねるほど複雑なパターンを表現できるようになります。ReLUなどが代表的です。
A. 着想は脳のニューロンですが、実際の脳とは別物です。脳の仕組みをうんと単純化して数式にしたもので、本物の神経細胞のように働くわけではありません。あくまで「ヒントを得た計算モデル」です。
A. データを受け取るのが入力層、間で計算して特徴を組み立てるのが隠れ層、最終的な答えを出すのが出力層です。隠れ層を深く重ねるほど複雑なパターンを表現でき、これを深層学習(ディープラーニング)と呼びます。
A. 代表的な活性化関数の一つで、「入力がマイナスなら0、プラスならそのまま通す」という単純な関数です。計算が軽く学習も安定しやすいため、多くのニューラルネットワークで使われています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。
🧠 もっと具体的に知る:ニューラルネットは、目的に応じて“配線”を変えることで力を発揮します。画像のCNN、系列のRNN・LSTM、生成のGAN・拡散モデルといった代表的なアーキテクチャは、連載「ディープラーニングの地図」(アーキ編・全5回)で図解しています。





