機械学習・ディープラーニング・生成AIの違いを図解で理解【2026年版】
ルミィ
AIの歩き方

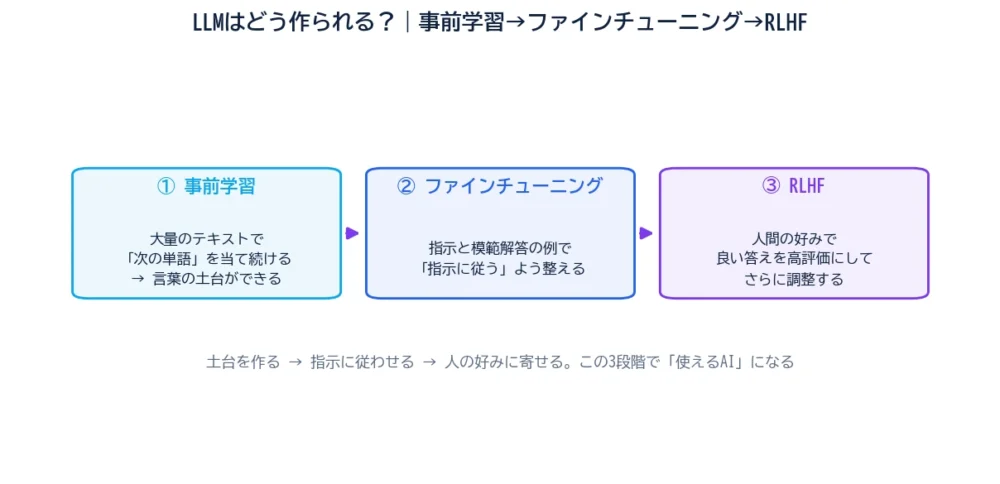
ここまでで、LLMの“部品”(トークン化・埋め込み・ニューラルネット・Transformer・Attention)が出そろいました。では、それを組み上げてChatGPTのような「指示に従う、ちょうどいいAI」にするには、どんな手順を踏むのでしょう。答えは、大きく3つの段階です。
①事前学習 → ②ファインチューニング → ③RLHF。この記事では、それぞれが何をしていて、なぜ3段階も必要なのかを、図でやさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

AIは「物知りにする → 指示に従わせる → 人の好みに寄せる」の3段階で“使えるAI”になるんだ。
最初の段階が事前学習(プレトレーニング)です。インターネット規模の膨大な文章を読み込ませ、ひたすら「次に来る単語を当てる」練習をさせます。
「むかしむかし、あるところに」の次は「おじいさん」が来やすい——こうした予測を、何兆もの単語で繰り返すうちに、AIは文法・知識・言い回しといった言葉の土台を身につけます。ここでできるのがベースモデルで、物知りではありますが、まだ「指示に素直に従う」性格ではありません。
この段階がいちばんお金と計算がかかるところで、巨大なモデルを作れるのは大手に限られます。
ベースモデルは物知りでも、「質問に答える」より「文章の続きを書く」性格です。そこでファインチューニング(追加学習)で、「指示」と「模範解答」のペアをたくさん見せて、指示に従って答えるスタイルを覚えさせます。
「〜を要約して」「〜を教えて」に対して、人が用意した良い答え方を学ぶことで、ベースモデルがチャットモデル(アシスタント)へと近づきます。量は事前学習よりずっと少なく、質の高い例が効きます。
最後がRLHF(人間のフィードバックによる強化学習)です。指示には従えるようになっても、「どの答え方が好まれるか」までは分かりません。そこで、同じ質問への複数の答えを人間が見比べて「こっちが良い」と評価します。
その評価から「人の好みを点数にするモデル(報酬モデル)」を作り、AIがより好まれる答えを出すよう調整します。丁寧さ・安全さ・分かりやすさといった、ルールにしにくい“さじ加減”は、この段階で身につきます。
①物知りにする(事前学習)→ ②指示に従わせる(ファインチューニング)→ ③人の好みに寄せる(RLHF)。この3段で「使えるAI」になる。
一気に作れない理由は、それぞれが別の課題だからです。
| 段階 | 身につくもの | データ |
|---|---|---|
| ①事前学習 | 知識・文法・言葉の土台 | 超大量・雑多なテキスト |
| ②ファインチューニング | 指示に従う行動 | 少量・高品質な指示と模範解答 |
| ③RLHF | 人の好み・さじ加減 | 人による良し悪しの比較 |
土台がないと賢くならず、指示調整がないと従わず、好み調整がないと使いにくい。だから順番に積み上げます。
細かい手法は進化しています。たとえばRLHFをより簡単にしたDPOのような方法や、人の代わりにAIが評価を助ける工夫、合成データの活用などです。ただし「土台→指示→好み」という大きな3段の流れ自体は共通で、ここを押さえておけば全体像はぶれません。
よくある誤解を解いておきます。普段ChatGPTに出す指示(プロンプト)は、学習ではありません。学習は、ここまで見た3段階で、公開前に終わっています。私たちが使うのは、その学習を終えた“固まった”モデルです。
だから、会話で「これを覚えて」と頼んでも、モデル本体の知識が書き換わるわけではありません。覚えておいてほしいことは、毎回プロンプトで渡すか、RAGで資料として参照させる必要があります。学習=作るときの話、プロンプト=使うときの話、と切り分けると混乱しません。
これだけ手をかけても、AIは平気で間違えます。理由は作り方そのものにあります。
事前学習の本質は「次の単語をそれっぽく予測する」こと。つまりLLMは、根っこのところで「事実を調べる装置」ではなく「もっともらしい続きを作る装置」です。だから、知らないことも自信たっぷりに“それっぽく”作ってしまう。これがハルシネーションの正体で、RLHFで減らせてもゼロにはできません。
「賢いのに、なぜ嘘をつくの?」の答えは、ここにあります。作り方を知ると、AIの得意(文章を作る)と不得意(事実の保証)の境目が、はっきり見えてきます。
作られたモデルは、公開のされ方も2通りあります。
どちらも作り方の3段階は同じ。違いは“できあがったモデルを誰がどう使えるか”です。
3つの段階は、ひとりの人が一人前になるまでに、ちょっと似ています。
物知りなだけでは接客はできず、型を覚えただけでは気が利かない。フィードバックを受けて初めて“感じのいい応対”ができる——AIも同じ順番をたどります。
LLMの作られ方を知ると、日々の使い方のコツも腑に落ちます。
「中の作り」を知っている人ほど、AIの得意を伸ばし、不得意を補う使い方ができます。この連載がめざしてきたのは、まさにそこです。
①の事前学習で読み込ませる「大量のテキスト」とは、具体的には何でしょう。主に、インターネット上の公開ページ、電子書籍、百科事典、プログラムのコードなど、膨大で多様な文章です。多くの言語・分野をまたいで読むからこそ、AIは幅広い知識と言い回しを身につけます。
ただ、ここには難しい論点もあります。
だから最近は、質の高いデータを選ぶ工夫や、AIが作った文章を使う合成データ、人による点検などが重視されています。「何を読ませたか」が、そのままAIの性格と限界を決める——この視点を持つと、モデルごとの個性やニュースの背景も読み解きやすくなります。
LLMは、①事前学習で言葉の土台を作り、②ファインチューニングで指示に従わせ、③RLHFで人間の好みに寄せる、という3段階で作られます。物知りなだけのベースモデルが、使いやすいアシスタントになるまでの道のりです。
この作り方を知っていると、AIの“クセ”の理由が見えてきます。物知りなのに最新情報に弱いのは学習が区切られているから。指示に素直なのに時々ズレるのは、好みの調整が完璧ではないから。そして自信たっぷりに間違えるのは、根が「もっともらしい続きを作る装置」だから。仕組みを知ることは、AIの得意と不得意を見極め、賢く付き合う力になります。
事前学習=物知りにする(超大量データ)。
ファインチューニング=指示に従わせる(少量・高品質)。
RLHF=人の好みに寄せる(人の評価)。
最終回は、こうして作った大きなモデルを「軽く・速く」する技術——蒸留・量子化・MoEに進みます。
A. 大きく3段階です。①事前学習で大量の文章から言葉の土台を作り、②ファインチューニングで指示に従うよう整え、③RLHFで人間の好みに寄せます。これで物知りなだけのモデルが使いやすいアシスタントになります。
A. 事前学習は超大量の雑多なテキストで「次の単語予測」を繰り返し、知識や文法の土台を作る段階。ファインチューニングは少量で高品質な「指示と模範解答」で、指示に従う行動を覚えさせる段階です。
A. 人間のフィードバックによる強化学習の略です。同じ質問への複数の答えを人間が見比べて評価し、その好みを学んでAIをより好まれる答え方に調整します。丁寧さや安全さなど、ルール化しにくいさじ加減を身につけます。
A. ベースモデルは事前学習だけの、文章の続きを書くのが得意なモデル。チャットモデルは、ファインチューニングやRLHFを経て、指示に従い対話できるよう調整されたモデルです。
A. 各段階で身につくものが違うからです。事前学習で知識、ファインチューニングで指示への従順さ、RLHFで人の好みを得ます。どれが欠けても使いやすいAIにはならないため、順番に積み上げます。
A. ファインチューニングは「指示と模範解答」の例から指示に従う行動を覚える段階、RLHFは人間が複数の答えを見比べた評価から好みのさじ加減を学ぶ段階です。前者で答え方の型を、後者で感じの良さを身につけます。
A. RLHFをより簡単にした学習方法の一つです。報酬モデルを別に作らず、人間が選んだ「良い答え・悪い答え」のペアから直接学びます。仕組みは違っても「人の好みに寄せる」という目的はRLHFと同じです。
A. 学習はモデルを作るとき(公開前)に重みを調整する作業、プロンプトは完成したモデルを使うときの指示です。会話で「覚えて」と頼んでもモデル本体は変わらないため、必要な情報は毎回プロンプトやRAGで渡します。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。