
ハルシネーションとは?AIの「もっともらしい嘘」との付き合い方
ルミィ
AIの歩き方

前回のトークン化で、AIは文章をトークンに分け、それぞれに番号(ID)を振る、というところまで見ました。でも番号はただの背番号で、それ自体に「意味」はありません。そこで登場するのが埋め込み(エンベディング)です。
埋め込みとは、言葉を「意味を表す数値の並び(ベクトル)」に変えること。意味が近い言葉どうしが、数値の世界でも近くに置かれるようにします。この記事では、なぜそんなことをするのか、どう役に立つのかを、図でやさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

番号は「背番号」、埋め込みは「意味の座標」。ここがAIの“言葉の理解”の正体に近いんだ。
埋め込みは、1つの言葉をたくさんの数値の並び(たとえば数百〜数千個の数字)に変換します。この数値の並びをベクトルと呼びます。たとえば「犬」は [0.82, 0.13, -0.47, …] のような数値の列になります。
大事なのは、この数値がでたらめではなく「意味」を表していること。意味が近い言葉ほど、ベクトルも近くなるように作られます。
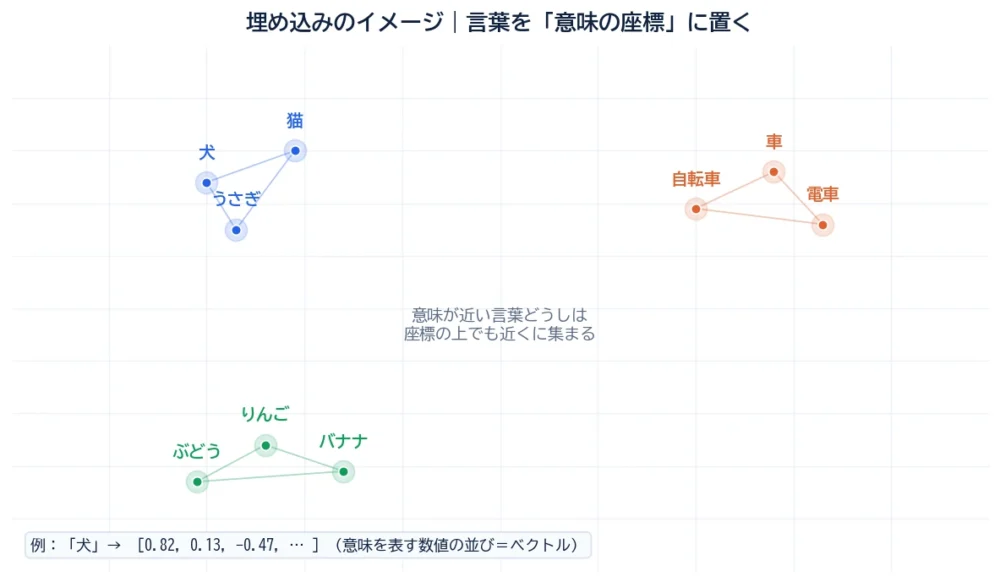
図のように、「犬」「猫」「うさぎ」は意味の地図の上で近くに集まり、「車」「電車」は別の場所に、「りんご」「バナナ」はまた別の場所に集まります。言葉の意味を、座標上の位置に置き換えた——これが埋め込みのイメージです。
コンピューターは意味を直接は分かりませんが、数値どうしの距離なら計算できます。だから言葉を座標に置けば、「この2つの言葉は意味が近い/遠い」を計算で判定できるようになります。
これがすごいのは、言葉が一文字も一致していなくても「意味の近さ」で探せること。「猫の餌やり」と「キャットフードの量」は文字は違いますが、意味の座標では近所にあります。検索が賢くなる秘密はここにあります。
埋め込みの面白さを示す、よく知られた例があります。言葉をベクトルにすると、意味の足し算・引き算のようなことができるのです。
「王様」のベクトル −「男」+「女」≒「女王」のベクトル
「王様から“男らしさ”を引いて“女らしさ”を足すと、女王に近づく」。意味が座標の上の方向として表れている、という驚きの性質です。完全に正確というわけではありませんが、埋め込みが本当に意味をとらえていることを実感できる例として有名です。
埋め込みは、人間が一つ一つ意味を教えるのではなく、大量の文章から自動で学びます。手がかりはシンプルで、「似た文脈に出てくる言葉は、意味も似ている」という考え方です。
「犬を散歩させる」「猫を散歩させる」のように、似た使われ方をする言葉は近いベクトルになっていきます。逆に「車」はまったく違う文脈で出てくるので、遠くに置かれます。言葉は、周りの言葉で意味が決まる——埋め込みはこの考え方を数値で実現したものです。
埋め込みは、いまのAIのあちこちで土台として働いています。
特にRAGの「意味で探す」は、埋め込みがあって初めて成り立ちます。AIに自分の資料を読ませる仕組みの裏側は、ほぼこの技術です。
埋め込みの考え方は言葉に限りません。画像・音声・動画も、同じように「意味のベクトル」に変換できます。だから「文章で画像を検索する」「似た画像を探す」といったことが可能になります。
最近のAIが、文章と画像を一緒に扱える(マルチモーダル)のも、違う種類のデータを同じ意味空間のベクトルに置けるようになったからです。埋め込みは、AIが世界を“意味”でつかむための共通言語のような存在です。
埋め込みのベクトルは、数百〜数千個の数値の並びだと言いました。この数値の個数を「次元」と呼びます。たとえば1,536個の数値なら「1,536次元」です。
次元は、意味を表す“ものさし”の数だと考えると分かりやすいです。1つの数値が「生き物っぽさ」、別の数値が「大きさ」、また別が「動くかどうか」——のように、たくさんのものさしで言葉を測ることで、ニュアンスまで細かく表現できます。次元が多いほど豊かな意味を持てますが、そのぶん計算も重くなるので、用途に合わせて選ばれます。
私たちが3次元の空間しかイメージできないのに対し、AIは数百次元の“意味の空間”を平気で扱います。図解では2次元に押しつぶして描いていますが、本物はもっと多くのものさしで言葉を捉えている、と思っておけば十分です。
埋め込みには、押さえておくと差がつく進化があります。「1単語=1ベクトルで固定」から「文脈で変わる」へ、という変化です。
初期の埋め込み(word2vecなど)は、ある単語にいつも同じベクトルを割り当てていました。でもこれだと困る言葉があります。たとえば「はし」は、橋・箸・端と、文脈で意味がまるで違うのに、同じベクトルになってしまうのです。
いまのLLMが使う埋め込みは、前後の言葉(文脈)を見て、その場でベクトルを決めます。「川にかかったはし」と「ごはんとはし」では、同じ「はし」でも違うベクトルになる。文脈に応じて意味を切り替えられるこの性質が、現代AIの言語理解の精度を大きく押し上げました。
埋め込みは「言葉→固定の意味」から「文脈に応じた意味」へ進化した。これが“同じ単語でも文脈で意味が変わる”をAIが扱える理由です。
便利な埋め込みにも、知っておきたい弱点があります。
とはいえ、これらは「埋め込みを過信しない」という心構えの問題。仕組みとして非常に強力なことは変わりません。
難しそうに見えて、埋め込みは私たちの日常にすっかり溶け込んでいます。「これも埋め込みなんだ」と気づくと、ぐっと身近になります。
どれも共通しているのは、「意味を数値の近さに置き換えて、近いものを探す・まとめる」という埋め込みの発想です。AIが“なんとなく意味を分かっている”ように見える場面の多くは、その裏でこのベクトルの計算が静かに働いています。
そして、この連載でこれから出てくるニューラルネットワークやTransformerも、入口ではまずこの埋め込みを受け取ります。埋め込みは、AIが言葉を“計算できる意味”に変える、すべての出発点なのです。
埋め込みで「意味が近いものを探せる」と分かると、次の疑問は「何万・何百万件もあったら、毎回ぜんぶと比べるの?」です。実際、まじめに全件と距離を計算していたら遅すぎます。
そこで使われるのがベクトルデータベース(ベクトルDB)という専用の保管庫です。あらかじめベクトルを「近いものどうし、だいたいこの辺」と整理しておき、全部を見なくても近いものをすばやく取り出せるようにしてあります。RAGが大量の資料からでも一瞬で関連箇所を見つけられるのは、この裏方のおかげです。
とはいえ、NotebookLMのような既製サービスを使う分には、ベクトルDBの存在を意識する必要はありません。「意味で探す仕組みの裏には、それ専用の倉庫がある」とだけ知っておけば十分です。
ちなみに埋め込みを作るモデル(埋め込みモデル)も日々進化していて、同じ文章でも、新しいモデルほど意味をより正確に座標化できます。自分でRAGを組むなら「どの埋め込みモデルを使うか」が検索精度を左右しますが、まずは既製サービスで“意味で探せる”体験をしてみるのが、いちばんの近道です。
埋め込みは、言葉(やトークン)を「意味を表すベクトル」に変える技術です。意味が近いものは座標でも近くに置かれ、その距離を計算することで、AIは“意味の近さ”を扱えるようになります。文字が一致していなくても意味で物事を結びつけられること——これが、AIが“言葉を分かっているように見える”いちばんの土台であり、検索からマルチモーダルまで、現代AIの広い範囲を静かに支えています。
埋め込み=言葉を「意味の座標」に置く。
意味が近い=ベクトルが近い。だから文字が違っても意味で探せる。
検索・RAG・レコメンド・LLMの入口、すべての土台。
次回は、この埋め込みを受け取って計算する本体——ニューラルネットワークに進みます。
A. 言葉やデータを「意味を表す数値の並び(ベクトル)」に変換する技術です。意味が近いものほどベクトルも近くなるように作られ、AIは数値の距離として「意味の近さ」を計算できるようになります。
A. トークン化は文章をトークンに分けて番号を振る工程、埋め込みはその番号を「意味のある数値ベクトル」に変える工程です。トークン化の次のステップが埋め込み、という関係になります。
A. 大量の文章から「似た文脈に出てくる言葉は意味も似ている」という手がかりで自動的に学習します。人間が一語ずつ意味を教えるのではなく、使われ方からベクトルが決まっていきます。
A. 意味での検索(RAG)、レコメンド、似た文章・画像のグルーピング、LLMへの入力など、幅広く使われます。特にAIに資料を読ませるRAGは、埋め込みがあって初めて成り立ちます。
A. できます。画像・音声・動画も「意味のベクトル」に変換でき、文章と同じ意味空間に置くことで、文章で画像を検索するようなマルチモーダルな扱いが可能になります。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。





