RNN・LSTMとは?系列データを“覚える”仕組みをやさしく図解
ルミィ
AIの歩き方
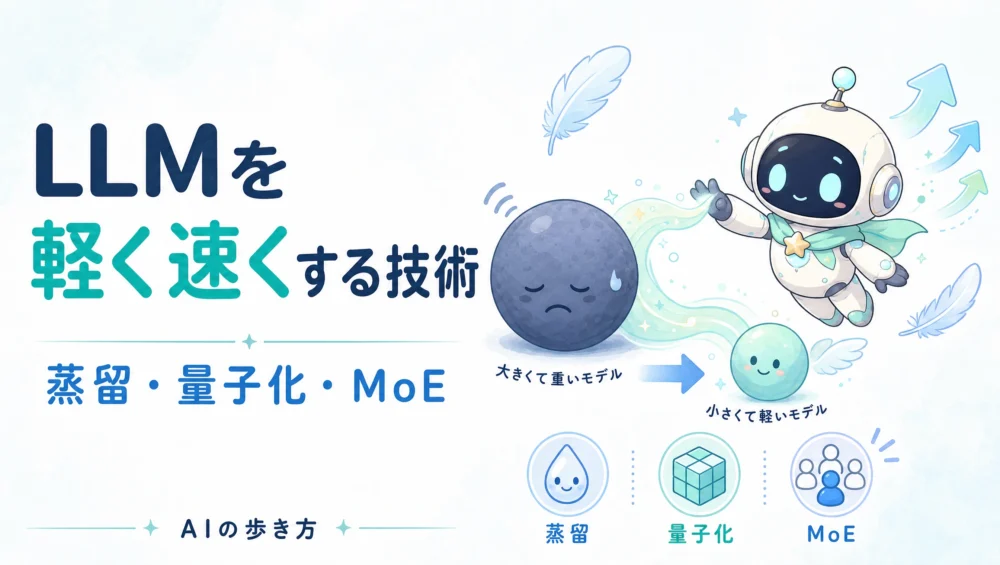
ここまでで、LLMがどう作られるかをたどってきました。最後に残る現実的な問題が、「できあがったLLMは、とても大きくて重い」こと。そのままではスマホや手元のPCで動かすのは大変で、動かすにも電気代がかかります。
そこで活躍するのが、モデルを軽く・速くする3つの技術——蒸留・量子化・MoEです。最近「スマホでも動くAI」「無料で使える賢いAI」が増えてきたのは、この3つのおかげ。連載の締めくくりとして、図でやさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

大きいAIをそのまま使うんじゃなく、賢く軽くする。これがローカルAIや格安AIを支えてるんだ。

蒸留(ディスティレーション)は、大きくて賢いモデル(先生)の答え方を、小さなモデル(生徒)に教え込む技術です。
ただ正解だけを教えるのではなく、先生モデルの「こう考えてこう答える」という出力の癖まで真似させることで、生徒モデルはサイズのわりに賢くなります。「軽いのに、けっこう賢い」モデルの多くは、この蒸留で作られています。
量子化は、モデルの中身である大量の重みの数値を、ざっくりした精度に置き換えて軽くする技術です。たとえば 0.8174… のような細かい数値を 0.8 のように粗くするイメージ。
数字1つあたりの情報量が減るので、メモリが小さくなり、計算も速くなります。多少ざっくりになっても答えの質はそれほど落ちないことが多く、手元のPCでLLMを動かす(ローカルAI)の定番テクニックです。
量子化の「Q4・Q5・Q8」といった具体的な話は、量子化モデルとは?で詳しく解説しています。
MoE(Mixture of Experts/専門家の混合)は、少し発想が違います。モデルの中にたくさんの“専門家”を用意しておき、質問ごとに必要な一部の専門家だけを動かす仕組みです。
全員を毎回働かせると重いですが、質問に関係する専門家だけ呼び出せば、大きなモデルなのに計算は軽くできます。「巨大なのに速い」最近のモデルには、このMoEを採用したものが増えています。
蒸留=小さく作り直す。量子化=数値を粗くして軽く。MoE=必要な部分だけ動かす。狙いはどれも「賢さを保って軽く・速く」。
軽量化は、ただの節約ではありません。AIを“みんなのもの”にするための鍵です。
これらは組み合わせて使われます。たとえば「蒸留で小さくしたモデルを、さらに量子化して手元で動かす」といった具合です。
3つに加えて、知っておくと役立つのがプルーニング(枝刈り)です。これは、ニューラルネットワークの中であまり働いていないつながり(重み)を思い切って取り除く技術です。
木の枝を剪定するように、結果にほとんど影響しない部分を削れば、モデルは軽くなります。ニューラルネットワークの大量の重みのうち、実は使われていないものが少なくない——だから削っても性能をあまり落とさずに済む、という発想です。蒸留・量子化と組み合わせて使われることもあります。
作る側の技術ですが、使う私たちにも関係します。手元でAIを動かしたい人が、まず意識するとよいのは次の順番です。
量子化版の選び方(Q4・Q5・Q8の違い)は量子化モデルとは?に、手元で動かす具体的な手順は関連記事側にまとまっています。
「軽くしたら頭が悪くなるのでは?」という不安は当然です。正直に言うと、やりすぎれば品質は落ちます。極端な量子化や乱暴な枝刈りは、答えの精度や安定性を下げることがあります。
ただ実際には、多くの用途で“ちょうどいい軽さ”が見つかるようになってきました。日常の要約・下書き・相談くらいなら、軽量モデルでも十分なことが多い。「最高性能を少し諦める代わりに、手元で・安く・速く使える」——このトレードオフをどう取るかが、AIを賢く使うコツになっています。
この3つ(+枝刈り)の技術は、AIの使われ方そのものを変えました。少し前まで、賢いAIは「巨大なサーバーの中にだけいる、遠い存在」でした。それがいま、こう変わりつつあります。
巨大化(スケール)でAIは賢くなり、軽量化でAIは身近になった。この“大きくする力”と“小さくする力”の両輪が、いまのAIの進化を動かしています。賢く大きいモデルを各社が競って作り、それを蒸留・量子化・MoEでみんなの手元に届ける——この流れを知っていると、新しいモデルのニュースの読み方も変わるはずです。
最終回なので、ここまでの全8回を一本の線でつないでおきます。バラバラだった用語が、ひとつの物語になっているはずです。
文章という“ただの文字列”が、トークンになり、意味の数値になり、巨大な網で計算され、学習で賢くなり、軽量化されて手元に届く——これがLLM(大規模言語モデル)の一生です。次にAIを触るとき、その裏側でこの流れが動いていると思うと、少しだけ景色が違って見えるかもしれません。
蒸留・量子化・MoEは、大きく重いLLMを「賢さを保ったまま軽く・速くする」ための技術です。最近のローカルAIや格安・高速なAIは、この工夫の上に成り立っています。
そしてこれで、連載「LLMはどう作られるのか」は完結です。文章をトークンに分け、意味のベクトルにして、ニューラルネットワークで計算し、学習で賢くし、Transformerとattentionで文脈を読み、3段階で“使えるAI”に育て、最後に軽量化してみんなの手元へ届ける——ChatGPTの一言の裏側には、これだけの仕組みが折り重なっています。
全部を覚える必要はありません。ただ「AIは魔法ではなく、こういう積み重ねでできている」と知っているだけで、ニュースの読み方も、AIとの付き合い方も、少し変わるはずです。新しいモデルの発表を見たとき、その裏でこの流れが動いていると想像できたなら、この連載の役目は果たせたことになります。お疲れさまでした。
蒸留=大きな先生から小さな生徒へ。
量子化=数値を粗くして軽量化。
MoE=必要な専門家だけ動かす。
これで連載「LLMはどう作られるのか」は完結です。トークン化から始まり、埋め込み・ニューラルネット・学習・Transformer・Attention・3段階の学習、そして軽量化まで——LLMとは何かを、いちばん深いところから見渡せたはずです。お疲れさまでした!
A. 代表的なのが蒸留・量子化・MoEの3つです。蒸留は大きなモデルの答え方を小さなモデルに教える、量子化は数値を粗くして軽くする、MoEは必要な専門家だけ動かす技術で、どれも賢さを保ったまま軽く・速くするのが狙いです。
A. 大きくて賢い「先生モデル」の出力の仕方を、小さな「生徒モデル」に教え込む技術です。正解だけでなく考え方の癖まで真似させることで、生徒はサイズのわりに賢くなります。
A. モデルの重みの数値を、より粗い精度に置き換えて軽くする技術です。メモリが小さくなり計算も速くなるため、手元のPCでLLMを動かすローカルAIの定番テクニックです。
A. モデル内に多数の「専門家」を用意し、質問ごとに必要な一部だけを動かす仕組みです。全員を動かさずに済むため、巨大なモデルでも計算を軽くでき、「大きいのに速い」を実現します。
A. 多少の品質低下はあり得ますが、賢さを保つよう工夫されています。蒸留やうまく設定した量子化では、サイズのわりに高い性能を保てることが多く、手元で動かせる利点の方が大きい場面が多いです。
A. できます。たとえば蒸留で小さくしたモデルをさらに量子化して手元で動かす、といった組み合わせが一般的です。目的はどれも「賢さを保って軽く・速く」なので、相性よく重ねて使われます。
A. 手元のPCやスマホでAIを動かすローカルAIは、これらの軽量化技術があって初めて現実的になります。特に量子化版のモデルは普通のPCでも動かしやすく、ローカルAIの定番です。
A. MoEは多数の専門家を持つため全体のパラメータは巨大ですが、1回の処理では質問に必要な一部の専門家だけを動かすためです。全員を毎回動かさないので、大きいのに計算は軽く・速くできます。
A. ニューラルネットワークの中で、ほとんど働いていないつながり(重み)を取り除いて軽くする技術です。木の枝を剪定するように、結果に影響しない部分を削ることで、性能をあまり落とさずモデルを小さくできます。
A. 用途しだいです。日常の要約・下書き・相談なら軽量モデルでも十分なことが多く、速くて安く、手元でも動きます。高い正確さや難しい推論が必要な場面では、大きいモデルが有利です。目的に合わせて使い分けるのがおすすめです。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。