
LLM(大規模言語モデル)とは?ChatGPTの心臓部をやさしく解説【2026年版】
ルミィ
AIの歩き方
ここまでCNN(画像)とRNN(系列)という、“判別する”ためのネットワークを見てきました。今回のオートエンコーダは少し毛色が違い、「入力をいったん圧縮して、また元に戻す」ことで学ぶ、ちょっと不思議なネットワークです。
「入れたものをそのまま出すなんて、何の役に立つの?」と思うかもしれません。ところがこの仕組みは、次元削減・異常検知・ノイズ除去、さらには画像生成の入り口まで、驚くほど幅広く使えます。図でそのカラクリを見ていきましょう。
この連載は、ニューラルネットとは?とディープラーニングの学習で学んだ「基本のしくみ」を土台にしています。まだの方は先に読むと、よりスッと入ってきます。
🧠 連載「ディープラーニングの地図」(全5回)
ニューラルネットの基本を土台に、画像・系列・生成といった“目的ごとの配線(アーキテクチャ)”を順にたどる連載です。

わざと細い通り道を作って“ぎゅっ”と圧縮するのがミソ。うまく元に戻せたら、本質をつかめた証拠だよ。
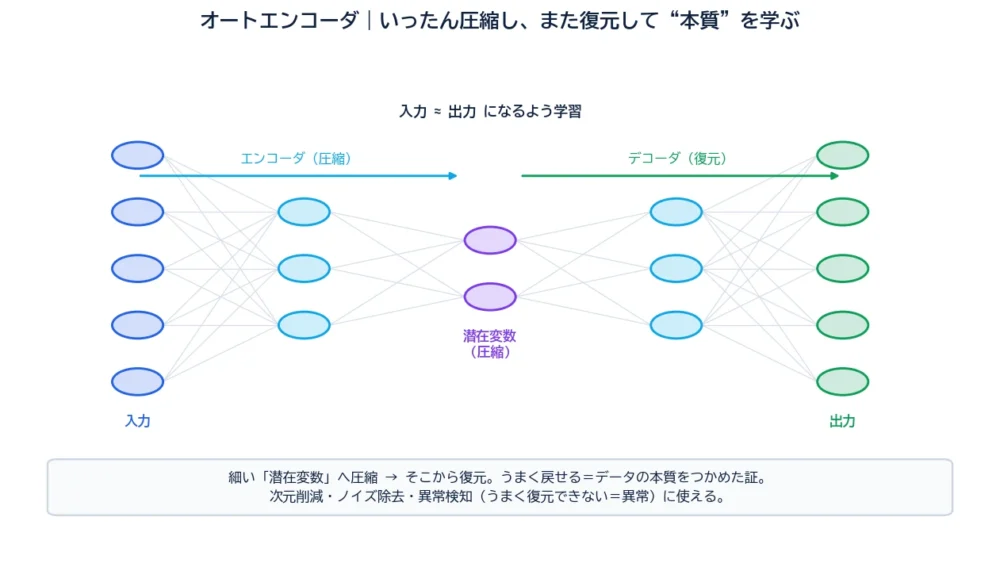
オートエンコーダは、入力とできるだけ同じものを出力するように学習するニューラルネットです。ただし途中に、わざと細いくびれ(ボトルネック)を作っておきます。
情報は、この細い通り道を通らないと出口にたどり着けません。つまりAIは、少ない情報量に“ぎゅっ”と圧縮しても、元に戻せるような“要点”を見つけ出す必要に迫られます。正解ラベルは要らず、入力そのものが手本になる——だから自分で自分を教える「自己教師あり」の一種です。
オートエンコーダは、図のように3つの部分でできています。
学習のゴールは、「入力 ≈ 出力」になること。うまく復元できるようになったとき、中央の潜在変数には、そのデータの“本質”が詰まっている、というわけです。砂時計のように、いったん細く絞ってまた広げる形をイメージすると分かりやすいでしょう。
潜在変数は「少ない数字に圧縮された表現」なので、そのまま**次元削減**に使えます。たくさんの特徴量を、数個の本質的な軸にまとめるわけです。
考え方は主成分分析(PCA)と似ていますが、大きな違いは、オートエンコーダは“曲がった”複雑な関係も圧縮できること。PCAがまっすぐな軸でまとめるのに対し、ニューラルネットの非線形な力で、より柔軟にデータの形を捉えられます。
オートエンコーダの応用で特に人気なのが異常検知です。発想がとても巧妙です。
まず、正常なデータだけでオートエンコーダを学習させます。すると、正常なデータは上手に復元できるようになります。ここに異常なデータ(見たことのないパターン)を入れると——学習していないので、うまく復元できず、入力と出力の差が大きくなる。この「復元の失敗度」を見れば、異常を見つけられるのです。
工場の機械の故障予兆、不正取引の検知、医療データの異常など、「正常はたくさんあるが、異常のサンプルは少ない」場面で重宝します。
デノイジングオートエンコーダという使い方もあります。学習のとき、わざとノイズを乗せた画像を入力し、ノイズのないきれいな画像を出力させるように訓練するのです。
すると、ネットワークは「ノイズを取り除いて本来の姿を復元する力」を身につけます。かすれた写真の修復や、ざらついた画像の補正などに使えます。そして実はこの“ノイズを取り除く”という発想は、連載の最後に登場する拡散モデルの核心にもつながっていきます。
オートエンコーダを“生成”に使えるように発展させたのがVAE(変分オートエンコーダ)です。
ふつうのオートエンコーダの潜在空間は、点がバラバラに散らばっていて、間を狙っても意味のあるものは出てきません。VAEは潜在空間をなめらかに整えるよう工夫することで、「潜在空間から適当な点を選んでデコーダに通すと、新しいデータが生まれる」ようにしました。
こうしてオートエンコーダは、判別だけでなく「データを生み出す」生成モデルへの橋渡しになります。次回のGAN、そして拡散モデルへと、生成の物語が続いていきます。
オートエンコーダが圧縮した先の「潜在空間」は、ただの数字の置き場ではありません。似たデータが近くに、違うデータが遠くに配置された、意味のある地図のような空間です。
うまく学習できると、この空間では面白いことが起きます。たとえば顔画像で学習した場合、「笑顔の点」と「真顔の点」の差を取ると“笑顔らしさ”の方向が分かり、別の顔にその方向を足すと笑顔にできる——そんな「意味の足し算・引き算」ができることもあります。潜在空間は、データの“本質的な特徴”が整理されて並んだ世界なのです。
オートエンコーダには落とし穴があります。ボトルネックが太すぎると、AIは“手抜き”をして、ただ入力を丸写しするだけになってしまうのです。それでは「入力≈出力」は達成できても、本質は何も学べていません。
「どれだけ絞るか」の塩梅が、設計の腕の見せどころ。圧縮しすぎても情報が失われ、緩すぎても何も学ばない——ちょうどよい細さを探すことになります。
オートエンコーダは、正解ラベルを使わない教師なし学習の仲間です。機械学習の3つの学び方でいえば、データそのものから構造を見つけるグループに入ります。
同じ次元削減でもPCAは線形、オートエンコーダは非線形。グループ分けのクラスタリングと組み合わせて「オートエンコーダで圧縮してからクラスタリング」といった合わせ技も使えます。教師なしの道具箱の、強力な一つです。
生成モデルの歴史でみると、オートエンコーダ(特にVAE)は“生成”の先駆けの一つでした。VAEはなめらかな潜在空間から新しいデータを作れますが、生成物がややぼやけやすいという課題もありました。
その課題に別のアプローチで挑んだのが、次回のGAN(競争で鮮明に)と、最終回の拡散モデル(ノイズ除去で高品質に)です。圧縮・復元という素朴な発想が、生成AIの大きな流れの出発点になっている——そう捉えると、オートエンコーダの位置づけがよく見えてきます。
オートエンコーダ(やその発展形)は、意外と身近なところで働いています。
「圧縮した表現(潜在変数)そのものが役に立つ」というのが共通点です。出力をそのまま使うより、“中央でできた要点”を取り出して別の用途に活かす——これがオートエンコーダの実用的な使い方です。出力(復元結果)だけを見て『入力と同じものが出てくるだけ』と侮ってはいけません。本当の価値は、その途中にできる“凝縮された表現”のほうにあるのです。
オートエンコーダは、入力をいったん細いボトルネックに圧縮し、また元に戻すことで、データの“本質”を学ぶネットワークです。正解ラベルが要らない自己教師ありの代表で、次元削減・異常検知・ノイズ除去と、応用範囲はとても広いものでした。
「圧縮してまた戻す」という、一見すると地味で不思議な仕組み。けれどそこには、『うまく戻せる=本質をつかめた』という、機械学習の核心とも言える考え方が詰まっていました。だからこそ、次元削減から異常検知、ノイズ除去、レコメンドや類似検索、そして生成まで、こんなにも幅広く使えるのです。そしてVAEを通じて開いた“生成”の扉の先に、次回からのGANと拡散モデルが待っています。素朴な発想が、現代の画像生成AIへとつながっていく——その出発点が、このオートエンコーダなのです。
「うまく圧縮して戻せる=本質をつかめた」というシンプルな考え方が、これだけ多くの用途を生みます。そしてVAEを通じて、“生成”の世界への入り口にもなりました。次回からは、いよいよ画像を生み出すネットワーク——GANと拡散モデルに進みます。
オートエンコーダ=圧縮して復元し、本質を学ぶ(自己教師あり)。
用途=次元削減・異常検知(復元の失敗で発見)・ノイズ除去。
VAEへ発展し、生成モデルへの橋渡しになる。
A. 入力とできるだけ同じものを出力するよう学習するニューラルネットです。途中にわざと細いボトルネックを設け、少ない情報に圧縮しても復元できる“要点”を学ばせます。正解ラベルが不要な自己教師ありの一種です。
A. 入力を圧縮するエンコーダ、圧縮された要点が収まる潜在変数(ボトルネック)、そこから復元するデコーダの3つでできています。『入力≈出力』になるよう学習し、中央の潜在変数にデータの本質が詰まります。
A. どちらも次元削減に使えますが、PCAがまっすぐな軸でまとめるのに対し、オートエンコーダはニューラルネットの非線形な力で曲がった複雑な関係も圧縮できます。より柔軟にデータの形を捉えられるのが違いです。
A. 正常なデータだけで学習させると、正常はうまく復元できますが、見たことのない異常データは復元に失敗し、入力と出力の差が大きくなります。この『復元の失敗度』を見ることで異常を見つけられます。
A. わざとノイズを乗せた入力から、ノイズのないきれいな出力を復元するよう学習させたものです。ノイズを取り除く力を身につけ、画像の修復などに使えます。この発想は拡散モデルにもつながります。
A. オートエンコーダを生成に使えるよう発展させたものです。潜在空間をなめらかに整えることで、潜在空間から適当な点を選んでデコーダに通すと新しいデータが生まれるようにしました。生成モデルへの入り口になります。
A. 次元削減(データの可視化や前処理)、異常検知(故障予兆や不正検知)、ノイズ除去(画像の修復)などに使われます。VAEを通じて画像生成の基礎にもなっています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。モデルの詳細や最適な使い方は用途・データによって変わります。





