
LLM(大規模言語モデル)とは?ChatGPTの心臓部をやさしく解説【2026年版】
ルミィ
AIの歩き方

連載の最終回は、いまの画像生成AIの主役——拡散モデル(Diffusion Model)です。Stable Diffusion、DALL·E、Midjourneyなど、話題の画像生成AIの多くが、この仕組みで動いています。
拡散モデルのアイデアは、ちょっと意外です。「砂嵐のようなノイズから出発して、少しずつノイズを取り除き、絵を浮かび上がらせる」——彫刻家が石を削って像を彫り出すように、AIがノイズを削って画像を作るのです。図でそのプロセスを見ていきましょう。
この連載は、ニューラルネットとは?とディープラーニングの学習で学んだ「基本のしくみ」を土台にしています。まだの方は先に読むと、よりスッと入ってきます。
🧠 連載「ディープラーニングの地図」(全5回)
ニューラルネットの基本を土台に、画像・系列・生成といった“目的ごとの配線(アーキテクチャ)”を順にたどる連載です。

真っ白い砂嵐から、少しずつノイズを払って絵を彫り出す。前回のGANとは、まったく違うアプローチだよ。
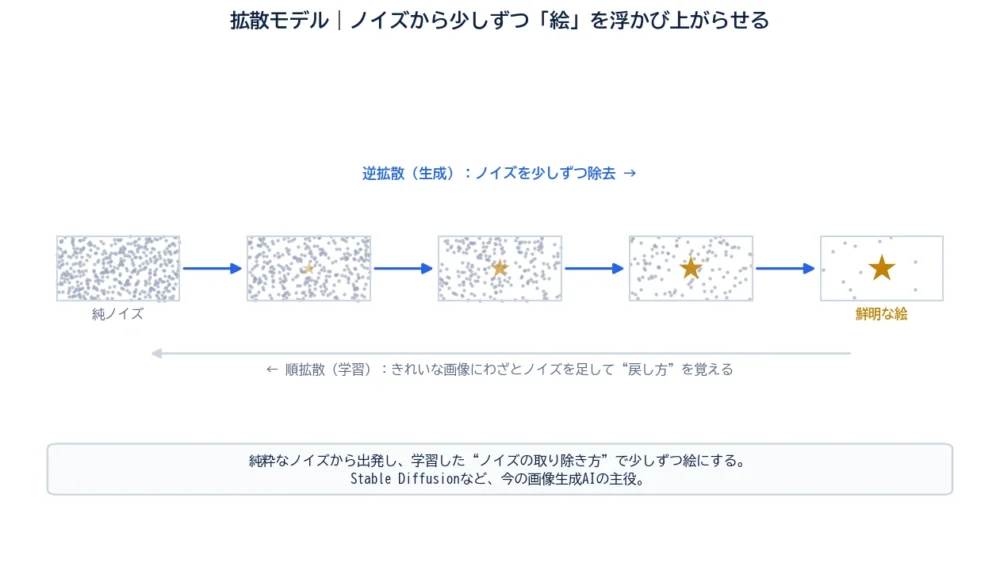
拡散モデルは、ノイズを少しずつ取り除くことで画像を生成するモデルです。前回の<a href=”https://mowfile.com/what-is-gan/”>GAN</a>が「2つを競わせる」発想だったのに対し、拡散モデルは「ノイズの除去」という、まったく違う道すじで生成を実現します。
名前の“拡散(diffusion)”は、もともと物理で「インクが水に広がって混ざっていく」現象を指す言葉です。拡散モデルは、この“混ざっていく過程”を逆再生する——つまり「混ざりきったノイズから、元のきれいな状態へ戻していく」イメージで動きます。
拡散モデルの学習と生成は、2つの方向の過程で説明できます。
ポイントは、「ノイズを足す」のは簡単だが、「ノイズを取り除く」のは難しいということ。だからAIは、たくさんの画像で「ノイズの足され方」を観察し、その逆向き=取り除き方を徹底的に練習します。図の左から右へ、砂嵐が少しずつ絵になっていく過程が、まさにこの逆拡散です。
「ノイズを取り除くだけで、どうして新しい絵が生まれるの?」と不思議に思うかもしれません。カギは、一発で絵にしようとせず、何十回もの小さなステップに分けることにあります。
各ステップでは「いまのノイズ画像から、ほんの少しだけノイズを減らす」という、簡単な仕事だけをします。難しい「ノイズ→絵」を、易しい「少しだけノイズ除去」の積み重ねに分解しているのです。出発点のノイズが毎回違うので、同じ条件でも少しずつ違う絵が生まれる——これが多様な画像を作れる理由です。
「猫の絵を描いて」と文章で頼むと絵が出てくる——あの仕組みは、拡散モデルに「テキストの条件」を組み合わせることで実現しています。
入力した文章(プロンプト)は、いったんTransformer系の仕組みで「意味のベクトル」に変換されます。拡散モデルは、ノイズを取り除く各ステップで「この意味に近づくように」とテキストに誘導されながら除去を進めます。だから「猫」と指定すれば猫に、「水彩画風」と添えればその画風に寄っていくわけです。
実際の画像生成AI(ComfyUIやAdobe Fireflyなどの裏側)では、計算を軽くするため、画像そのものではなく“圧縮した潜在空間”でこの拡散を行う工夫(潜在拡散)も使われています。前回までのオートエンコーダの圧縮の考え方が、ここでも生きています。
拡散モデルが画像生成の主役になったのには、はっきりした理由があります。
| GAN | 拡散モデル | |
|---|---|---|
| 作り方 | 2つを競わせる | ノイズを少しずつ除去 |
| 学習の安定性 | 不安定(崩れやすい) | 安定しやすい |
| 品質・多様性 | 高いが偏りやすい | 高品質で多様 |
| 生成スピード | 速い(一発) | 遅い(多ステップ) |
拡散モデルは生成に時間がかかるのが弱点ですが、学習が安定し、高品質で多様な絵を作りやすい。この長所が、テキストから画像を作る時代の要求にぴったり合ったのです。
拡散モデルは、いまや生成AIの一大ジャンルになっています。
ここまで来ると、生成AIの全体像が見えてきます。言葉を生成するのがLLM(Transformerベース)、画像を生成するのが拡散モデル——この2つが、いまの生成AIブームを支える両輪です。
面白いのは、両者が混ざり合ってきていること。テキスト理解にTransformerを使う拡散モデルや、画像も言葉も一緒に扱うマルチモーダルなモデルが次々と登場しています。アーキテクチャの“いいとこ取り”が、いまのAIの最前線なのです。
逆拡散の1ステップで、AIが実際にやっているのは「いまの画像に“どんなノイズが乗っているか”を予測し、それを少しだけ差し引く」ことです。このノイズ予測には、CNNを発展させたU-Netという形のネットワークがよく使われます。
「ノイズを当てて引く」を何十回もくり返すうちに、砂嵐が少しずつ意味のある絵へと近づいていきます。ステップ数を増やすほど丁寧な絵になりやすい一方、時間もかかる——品質とスピードのトレードオフがここにあります。
拡散モデルを使う画像生成AIに触れると、いくつかの専門用語に出会います。意味が分かると、設定で迷いません。
これらの設定を実際にいじってみたい方は、拡散モデルをノードでつないで操るComfyUIの記事もあわせてどうぞ。仕組みを知っていると、設定の意味がぐっと分かりやすくなります。
拡散モデルの最大の弱点は、生成に時間がかかることです。何十回ものノイズ除去ステップを踏むので、1枚作るのにそれなりの計算が必要になります。
そこで、少ないステップ数でも高品質に仕上げる手法や、ベテランモデルの知恵を受け継いで一気に生成する蒸留といった高速化の研究が活発です。数十ステップが数ステップで済むようになれば、リアルタイムに近い生成も視野に入ります。
「品質は高いが遅い」を「速くても高品質」に近づける——この改良の方向は、LLMを軽くする蒸留・量子化の話ともよく似ています。生成AIは、性能と軽さの両立に向かって進化を続けているのです。
拡散モデルは、完全なノイズから出発し、学習した“ノイズの取り除き方”で少しずつノイズを除去して、画像を生み出すモデルです。難しい生成を「小さなノイズ除去」の積み重ねに分解することで、安定して高品質・多様な絵を作れるようになりました。いまの画像生成AIの主役です。
画像のCNN、系列のRNN、生成のGAN、そしてこの拡散モデル——ディープラーニングは、扱うデータと目的に合わせて“配線”を変えることで、見る・読む・創るという多彩な力を獲得してきました。拡散モデルは、その『創る』の最前線です。仕組みを知っておけば、画像生成AIを使うときも、ニュースで新しいモデルの名前を聞いたときも、『ああ、あの考え方の発展だな』と、自分の地図の上に置けるようになります。それこそが、この連載でいちばん持ち帰ってほしいものです。
これで連載「ディープラーニングの地図」は完結です。画像のCNN、系列のRNN・LSTM、圧縮のオートエンコーダ、生成のGANと拡散モデル——目的ごとに“配線”を変えることで、ディープラーニングは多彩な力を発揮します。この地図を持って、ぜひ次の一歩を踏み出してください。お疲れさまでした。
拡散モデル=ノイズを少しずつ除去して画像を生成する。
難しい生成を、易しい「少しだけノイズ除去」の積み重ねに分解。
学習が安定し高品質・多様。今の画像生成AIの主役で、LLMと並ぶ生成AIの両輪。
A. 完全なノイズから出発し、学習した“ノイズの取り除き方”で少しずつノイズを除去して画像を生成するモデルです。Stable DiffusionやDALL·E、Midjourneyなど、今の画像生成AIの多くがこの仕組みで動いています。
A. 順拡散は学習時に、きれいな画像へわざと少しずつノイズを足して砂嵐にする過程です。逆拡散は生成時に、完全なノイズから学習した取り除き方でノイズを減らし、きれいな画像を作る過程です。
A. 一発で絵にせず、何十回もの小さなノイズ除去ステップに分けるためです。各ステップは簡単で、出発点のノイズが毎回違うので、同じ条件でも少しずつ違う絵が生まれ、多様な画像を作れます。
A. 入力した文章を意味のベクトルに変換し、ノイズを取り除く各ステップでその意味に近づくよう誘導するためです。『猫』と指定すれば猫に、『水彩画風』と添えればその画風に寄っていきます。
A. GANは2つのネットワークを競わせて生成しますが、拡散モデルはノイズを少しずつ除去して生成します。拡散モデルは生成が遅い一方、学習が安定し高品質で多様な画像を作りやすいため、近年の主流になっています。
A. Stable DiffusionやDALL·Eなどの画像生成、一部を描き換える画像編集(インペイント)、動画・3D・音声生成への応用、粗い画像をくっきりさせる超解像や修復などに使われています。
A. 言葉を生成するのがLLM(Transformerベース)、画像を生成するのが拡散モデルで、今の生成AIの両輪です。テキスト理解にTransformerを使う拡散モデルや、画像と言葉を一緒に扱うマルチモーダルモデルなど、両者は混ざり合ってきています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。モデルの詳細や最適な使い方は用途・データによって変わります。





