
Ideogramの使い方|文字入り画像が綺麗に作れる画像生成AI【2026年版】
ルミィ
AIの歩き方

画像生成AIまわりで「ComfyUI(コンフィUI)」という名前をよく見かけるようになりました。ただ、「ComfyUIって、どの画像を作るAIなの?」と思っている人も多いはずです。
結論から言うと、ComfyUIは画像生成AIや動画生成AIを動かすためのノード式の制作環境です。ここで大事なのは、ComfyUI自体は、Image2(GPT Image 2)やSeedance 2.0のような「生成モデル」ではないということです。
ComfyUIは、モデルそのものではなく、生成AIをどう動かすかを設計する操作盤・制作ラインです。公式でも、複数のAIモデルや処理をノードで組み合わせられる、ノードベースの生成AIインターフェースとして説明されています。

ComfyUIは「絵を描くAI」そのものじゃなくて、「AIに絵を描かせる工程を組み立てる場所」なんだね。
ChatGPTやImage2が「AIに頼んで作ってもらう道具」だとすれば、ComfyUIはAI画像生成の工程を自分で組み立てる工房です。
たとえば、普通の画像生成は「プロンプトを書く」→「画像が出る」というシンプルな流れです。一方ComfyUIでは、次のような工程を、箱(ノード)と線でつないで作ります。
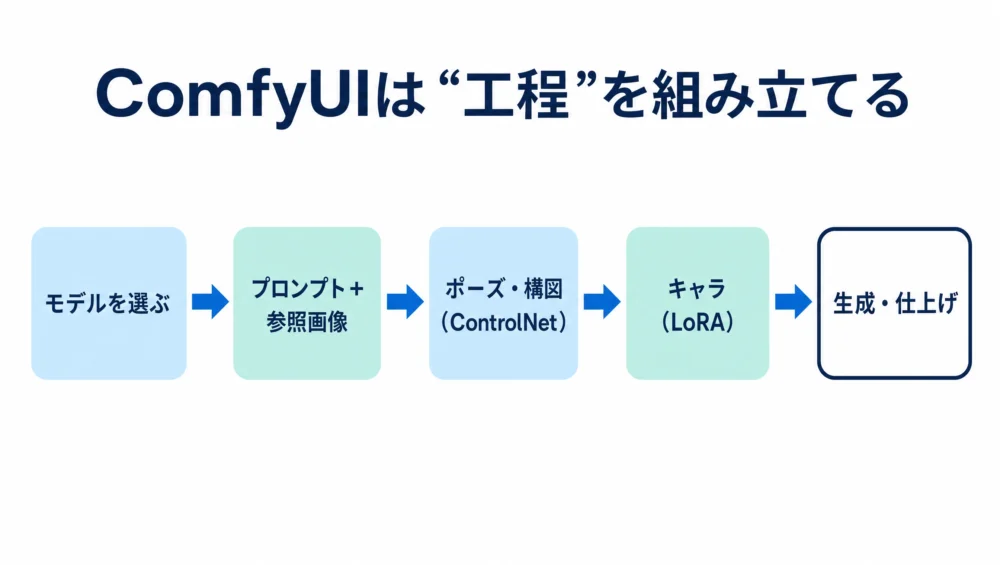
一つひとつの処理が「箱」になっていて、それを線でつないで自分だけの制作ラインを作る。これがComfyUIの基本的な考え方です。
ComfyUIでできることは、単なる画像生成だけではありません。
公式の開発者向けの説明でも、ComfyUIはローカル実行・ワークフロー作成・カスタムノード・APIサーバー化ができる生成AIエンジンとして位置づけられています。
基本形は、ローカルPCで動かして、自分のGPUを使う方式です。特にNVIDIA GPUとVRAM(ビデオメモリ)が重要になります。ただし、今は大きく3つの使い方があります。
| 使い方 | 概要 |
|---|---|
| 自分のPCで動かす | 自分のNVIDIA GPU・VRAMを使う基本形。素材を手元で扱える |
| クラウドGPUで動かす | Comfy CloudなどでクラウドGPU上のComfyUIを使う。自前GPUがなくても動かせる |
| 外部AIサービスを呼ぶ | Partner Nodesで、外部の最新モデルをAPI経由で呼び出す |
公式のComfy Cloudは、ローカル環境や自前GPUなしでクラウドGPU上のComfyUIを使う方向のサービスです。またComfyUIには、外部AIサービスを呼ぶPartner Nodesの仕組みもあります。
つまり、「ComfyUI=必ずローカルPCだけで完結」ではありません。ただし、昔からの中心は「自分のPCでStable Diffusion系モデルを細かく動かす環境」です。GPUやVRAMの目安は、ローカルAIの必要スペックまとめもあわせてどうぞ。
ここは、いちばん誤解しやすいところです。Image2、つまりGPT Image 2は「画像生成モデル」そのものです。OpenAIの最新の画像生成モデルで、高品質な生成・編集に加え、日本語を含む文字入り画像の精度の高さが特徴です。画像生成のリーダーボードでも高く評価されています。
なので、単純な画質・指示理解・日本語文字入り画像・自然な構図では、Image2の方が強い場面が多いです。くわしくは ChatGPTの最新機能まとめ|Images 2.0・Apps・Codexの使いどころ も参考になります。
では、ComfyUIはどこで勝つのか。画質そのものというより、工程の制御です。次のような用途で活きます。
「1枚の完成度」ではなく「同じ工程を何度も正確に回すこと」。ここがComfyUIの主戦場です。
動画生成については、Seedance 2.0やVeo、Runway、Klingのようなクラウド動画AIがかなり強いです。Seedance 2.0は、ネイティブ音声つきで動画を作れるモデルとして注目されています。
ComfyUIでも動画生成ワークフローは組めますが、ローカルでの動画生成は重く、VRAMも必要です。長尺・音声付き・安定した動きでは、クラウド動画AIの方が現実的なことが多いです。
そのため、現実的には次のような住み分けになります。
| 用途 | 向いているもの |
|---|---|
| 画像の高品質生成 | Image2(GPT Image 2) |
| 動画の高品質生成 | Seedance 2.0 など |
| 細かい制御・ローカル生成・ワークフロー化 | ComfyUI |
ComfyUIの強さを理解するには、この3つが重要です。
LoRAは、特定のキャラ・画風・服装・商品などをモデルに追加で覚えさせる軽量な仕組みです。大きなモデル全体を再学習せず、少ない追加パラメータで適応させる手法として提案されました。
DreamBoothは、数枚の画像から特定の被写体を学習し、別の場面でもその被写体を出せるようにする技術です。
ControlNetは、ポーズ・輪郭・深度・線画などを条件として、画像生成の構図を制御する技術です。
簡単に言うと、次のような役割分担です。
| 要素 | 役割(ざっくり) |
|---|---|
| LoRA / DreamBooth | 誰を描くか(キャラ・画風) |
| ControlNet | どういう構図・ポーズで描くか |
| ComfyUI | それらをつないで「制作ライン」にする場所 |
ComfyUIを初めて開くと表示される標準のワークフロー(テキストから画像を作る最小構成)は、だいたい次の5つの箱でできています。この5つの役割さえ分かれば、画面はもう怖くありません。
| 箱(ノード) | 役割(ざっくり) |
|---|---|
| Load Checkpoint | 使うモデル(絵の腕前のもと)を読み込む |
| CLIP Text Encode ×2 | プロンプトをAIの言葉に翻訳する。「描いてほしいもの」用と「避けたいもの」用の2つ |
| KSampler | 実際に絵を生成するエンジン。ノイズから絵を仕上げていく |
| VAE Decode | AI内部のデータを、人間が見られる画像に変換する |
| Save Image | 完成した画像を保存する |
流れは「モデルを読み込む→指示を翻訳する→生成する→画像化する→保存する」。この一直線が全ワークフローの背骨で、LoRAやControlNetは、この線の途中に箱を足しているだけです。
ComfyUIが向いているのは、AI画像を一回きりの遊びではなく、継続的な制作に使う人です。たとえば、次のような人です。
逆に、月に数枚だけ高品質な画像が欲しい人、ブログのアイキャッチをすぐ作りたい人、日本語文字入り画像をきれいに作りたい人は、Image2の方が楽です。アイキャッチをサッと作りたいだけなら ChatGPTでアイキャッチ画像を作る方法 で十分なこともあります。
ComfyUIは、初心者に最初から勧めるツールではありません。まずImage2やChatGPTの画像生成で「AI画像生成で何ができるか」を体験したあとに、次の段階として触るのが自然です。
流れとしては、こう考えると分かりやすいです。
いきなりComfyUIに挑戦しなくて大丈夫。「同じキャラを何度も使いたい」と思ったときが、はじめどきだよ。
ComfyUIは、カスタムノードを追加して機能を拡張できます。ただしこれは、外部の人が作ったコードを自分の環境に入れる、ということでもあります。便利な反面、最低限の注意は必要です。
「便利だから全部入れる」ではなく、「必要なものを、出どころを確かめて入れる」。これだけで、トラブルのリスクはかなり下げられます。
ComfyUIは、最初に触るべき画像生成AIではありません。ただし、同じキャラを何度も使いたい、構図を固定したい、生成工程を自動化したい人にとっては、非常に強力な制作環境です。

1枚の完成度ならImage2。
動画の迫力ならSeedance 2.0。
でも、同じキャラ・同じ構図・同じ工程を何度も使うならComfyUI。
言いかえると、Image2が「高品質な1枚を作るAI」だとすれば、ComfyUIは「画像生成の制作ラインを組む道具」です。この住み分けで考えると、ComfyUIをかなり誤解なく捉えられます。
A. いいえ。ComfyUI自体は生成モデルではなく、画像生成AIや動画生成AIをノードで組み合わせて動かす制作環境(インターフェース)です。実際に絵を描くのは、ComfyUIに読み込ませるモデルの方です。
A. 基本はローカルPCのNVIDIA GPU・VRAMを使います。ただしComfy CloudのようなクラウドGPUや、Partner Nodesで外部サービスを呼ぶ使い方もあり、必ずしも自前GPUだけで完結するわけではありません。
A. 単純な画質や日本語の文字入り画像は、Image2(GPT Image 2)の方が強いことが多いです。ComfyUIの強みは画質そのものより、同じキャラ・同じ構図の量産やバッチ処理など「工程の制御」にあります。
A. 使えますが、最初の一歩には向きません。まずImage2やChatGPTの画像生成で慣れ、「同じキャラを繰り返し使いたい」と感じてから触るのがおすすめです。
※本記事は2026年6月時点の公開情報をもとに、ComfyUIの位置づけを初心者向けに整理したものです。ComfyUIや各AIモデルは更新が早いため、最新の機能・料金・対応状況は各公式サイトでご確認ください。
🎨 仕組みを知りたい方へ:これらの画像生成AIの多くが内部で動かしているのが「拡散モデル」です。ノイズから少しずつ絵を作るその仕組みは、拡散モデルとは?でやさしく図解しています。

