ディープラーニングの学習とは?勾配降下と誤差逆伝播をやさしく解説
ルミィ
AIの歩き方

ChatGPT、Claude、Gemini——名前の違うAIたちですが、土台はほぼ同じ仕組みでできています。その共通の心臓部がTransformer(トランスフォーマー)です。2017年の論文「Attention Is All You Need」で登場し、いまの生成AIブームのすべてはここから始まりました。
ちなみにGPTの「T」はTransformerの頭文字。GPT=Generative Pre-trained Transformer です。この記事では、Transformerが何を変えたのかを、前の仕組みと比べながらやさしく整理します。
📘 連載「LLMはどう作られるのか」(全8回)
ChatGPTのようなLLMが、ただの文章からどうやって作られるのか。トークン化から学習のしくみまでを、順番にやさしくたどる連載です。

GPTのTはTransformerのT。いまのAIの“心臓”は、ぜんぶこれなんだよ。
Transformerは、ニューラルネットワークの一種ですが、文章を扱うために特別な工夫をしたものです。最大の特徴は、文の全部の言葉を一度に見て、言葉どうしの関係をまとめて捉えること。
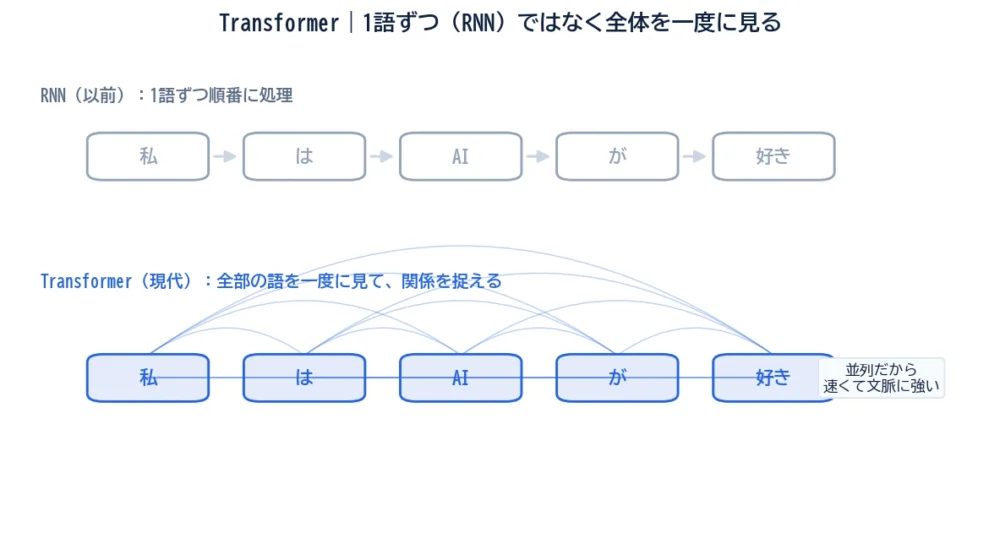
Transformer以前、文章はRNNのような仕組みで、1語ずつ順番に処理されていました。これには2つの弱点がありました。
「長い文章になると、前の方を忘れてしまう」——これが大きな壁でした。
Transformerはこの壁を、自己注意(Attention)という仕組みで突破しました。1語ずつ順番に読むのではなく、全部の語を同時に見渡して、「どの語がどの語と関係が深いか」を直接つかむのです。
この「全体を一度に見る」性質が、大規模化(=より多くのデータと計算で賢くする)を現実的にした。LLMの“L(Large)”は、Transformerだからこそ成り立っています。
RNNは「1語ずつの伝言ゲーム」、Transformerは「全員で同時に会議」。この違いが、長文への強さと学習の速さを生みました。
ただ、全部を一度に見ると、ひとつ困ることがあります。語の順番が分からなくなるのです。「猫が犬を追う」と「犬が猫を追う」は語は同じでも意味は逆。順番は大事です。
そこでTransformerは、各語に「何番目の語か」という位置の情報(位置エンコーディング)を一緒に持たせます。これで、全体を並列に見つつ、順番も失わずに済みます。
細部は複雑ですが、大づかみには次のブロックの積み重ねです。
この中心にある「自己注意」だけを取り出して、次回のAttentionとはで詳しく見ます。
Transformerがもたらした最大の発見の一つが、「モデルを大きくし、データと計算を増やすほど、性能が伸び続ける」という規則性(スケーリング則)です。
以前のAIは、ある程度大きくすると頭打ちになりがちでした。ところがTransformerは、並列で効率よく学習できるため、桁違いの規模まで“素直に賢くなった”のです。GPTが世代を追うごとに賢くなってきたのも、この性質が背景にあります。LLMの「L(Large=大きい)」は、ただ大きいのではなく、大きくする価値があるからこその名前なのです。
ただし、大きくするほどお金も電力もかかります。だからこそ、連載最終回で扱う「軽く・速くする技術」が重要になってきます。
Transformerは言語のために生まれましたが、その「全体の関係を捉える」性質は、ほかのデータでも有効でした。いまでは画像(Vision Transformer)・音声・動画などにも広く応用されています。
画像を小さなタイル(パッチ)に分けて“言葉のように”並べれば、Transformerで扱える——という発想です。文章も画像も音声も、同じ仕組みで扱えるようになったことが、1つのAIが何でもこなすマルチモーダル化を後押ししました。
Transformerをベースにしたモデルにも、使い方で2つの系統があります。やさしく言うと、「続きを書くのが得意」か「全体を読み取るのが得意」かの違いです。
どちらもTransformerの応用です。私たちが「生成AI」として触れているのは主にGPT系ですが、Transformerという土台は共通しています。
Transformerは、AIの歴史で「前」と「後」を分ける発明だと言われます。少し大げさに聞こえますが、理由はシンプルです。
登場以前、AIの言語処理は「そこそこ使える」止まりでした。翻訳はぎこちなく、長い文章はすぐ破綻する。それがTransformer以降、翻訳・要約・対話・文章生成が一気に実用レベルへ跳ね上がりました。ChatGPTの登場で世界が驚いたのも、その土台にこのアーキテクチャがあったからです。
ポイントは、Transformerが「1つの良い仕組みを、大きくするほど賢くできる」という道を開いたこと。研究者が手作業で工夫を足し続けるのではなく、データと計算を注ぎ込めば伸びる——この“スケールする土台”を手にしたことが、いまのAIブームの出発点になりました。
だからこの連載でも、Transformerは折り返し地点。ここまでのトークン化・埋め込み・ニューラルネットは、すべてこの心臓部にたどり着くための準備だった、とも言えます。
ここまで“革命の主役”として紹介してきましたが、Transformerにも弱点はあります。フェアに知っておきましょう。
こうした弱点を補うために、長文を効率よく扱う工夫や、RAGで事実を補う方法、軽量化の技術などが、いまも活発に研究されています。万能ではないからこそ、まわりの技術と組み合わせて使う——そこを押さえると、AIニュースの見え方が立体的になります。
Transformerは、文章の全部の語を一度に見て関係を捉える、現代LLMの心臓部です。1語ずつ処理するRNNと違い、並列で速く、長い文脈にも強い。だからこそ大規模化が可能になり、いまの生成AIを生みました。
ここまでの連載で積み上げてきた、トークン化・埋め込み・ニューラルネットワーク・学習。それらが合流して形になったのが、このTransformerです。ChatGPTもGemini もClaudeも、名前は違えど土台は同じこの仕組み。「GPTのTって何だっけ?」と聞かれたら、もう胸を張って“Transformer”と答えられます。次回は、その心臓部のさらに中心にある自己注意(Attention)を、いよいよ開いていきます。
Transformer=全体を一度に見るネットワーク。
並列で速く、長文に強い。だから「大きく」できた。
GPTのTはTransformer。いまのLLMの共通の土台。
次回は、その心臓部のさらに中心——Attention(自己注意)に進みます。
A. 文章の全部の語を一度に見て、語どうしの関係をまとめて捉えるニューラルネットワークです。2017年の論文「Attention Is All You Need」で登場し、現代のLLM(ChatGPTなど)の共通の土台になっています。
A. 1語ずつ順番に処理する以前の方式(RNN)と違い、全部の語を並列に処理できるため学習が速く、離れた語どうしの関係も捉えやすいことです。この性質が大規模化を可能にし、いまの生成AIを生みました。
A. GPTはGenerative Pre-trained Transformerの略で、Transformerをベースにしたモデルです。ChatGPTもGemini、ClaudeもTransformerを土台にしています。
A. RNNは文章を1語ずつ順番に処理するため遅く、長い文では前の情報が薄れがちでした。Transformerは全部の語を一度に見るため、速くて長文にも強いのが違いです。
A. Transformerは全部の語を一度に見るため、そのままでは語の順番が分かりません。そこで各語に「何番目か」という位置情報を加える仕組みが位置エンコーディングです。
A. 全部の語を並列に処理できるため、大量のデータと計算を効率よく投入できるからです。1語ずつ順番に処理するRNNでは並列化が難しく、これほどの規模まで学習させるのは現実的ではありませんでした。
A. 使えます。画像を小さなタイル(パッチ)に分けて言葉のように並べることで、Transformerで扱えます。これはVision Transformerと呼ばれ、画像認識や画像生成にも応用されています。
A. 用途によっては今も使われますが、文章を扱う主役の座はTransformerに移りました。Transformerは並列処理で速く長文に強いため、大規模な言語モデルではこちらが標準になっています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。各モデルの仕様や数値は変わることがあるため、最新情報は公式情報でご確認ください。