ローカルAIとクラウドAIの違い|ChatGPT・Gemini・Gemmaはどう使い分ける?
ルミィ
AIの歩き方

AIが写真を見て「これは猫」「これは信号機」と当てる——いまでは当たり前になったこの画像認識を支えてきたのが、CNN(畳み込みニューラルネットワーク)です。ディープラーニングが一気に注目されたのも、2012年にCNNが画像認識コンテストで圧勝したのがきっかけでした。
CNNは、ひとことで言うと「画像を見るために特化した配線」のニューラルネットです。この記事では、その中心にある「畳み込み」と「プーリング」という2つの仕掛けを、図でやさしく解きほぐします。
この連載は、ニューラルネットとは?とディープラーニングの学習で学んだ「基本のしくみ」を土台にしています。まだの方は先に読むと、よりスッと入ってきます。
🧠 連載「ディープラーニングの地図」(全5回)
ニューラルネットの基本を土台に、画像・系列・生成といった“目的ごとの配線(アーキテクチャ)”を順にたどる連載です。

ふつうのニューラルネットを“画像用に組み替えた”のがCNN。カギは『小さなフィルタで画像をなぞる』ことだよ。
ふつうのニューラルネットは、入力のすべてを次の層につなぐ「全結合」が基本です。ところが画像は情報量が多く(たとえば小さな写真でも数十万の画素)、全部をつなぐと配線が爆発的に増えて学習できません。
そこでCNNは、「画像の近くにある画素どうしが関係している」「同じ模様は画像のどこに現れても同じ模様」という、画像ならではの性質を利用します。画像全体を一度に見るのではなく、小さな窓で少しずつ見ていく——この発想が、CNNを画像に強くしています。
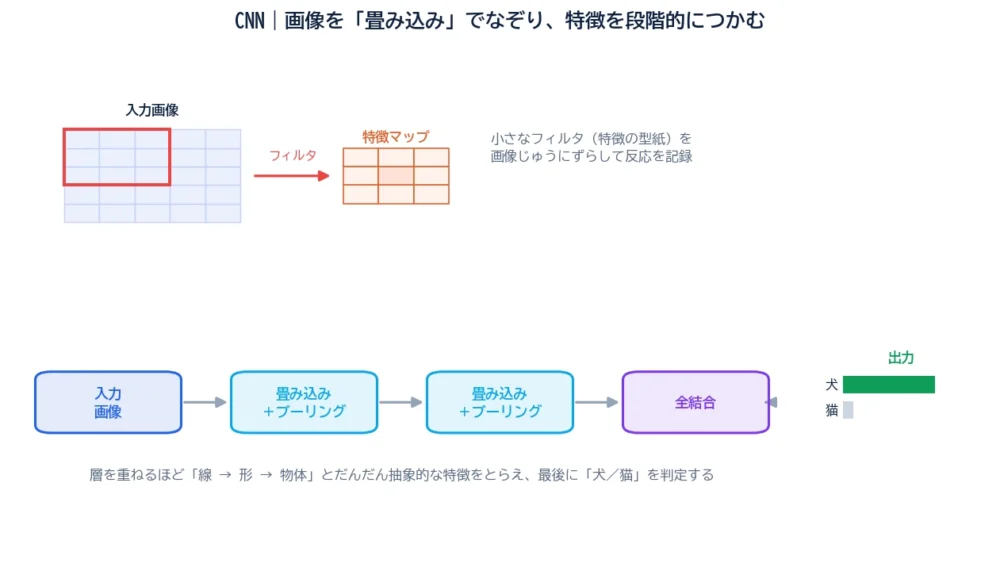
CNNの心臓部が畳み込み(convolution)です。図のように、小さなフィルタ(特徴の“型紙”)を画像の上で少しずつずらしながら当てて、反応の強さを記録していきます。
たとえば「縦の線に反応するフィルタ」を画像じゅうに滑らせれば、縦線がある場所だけ強く反応します。こうしてできた“反応の地図”が特徴マップです。フィルタを何種類も用意すれば、「縦線」「横線」「カーブ」「特定の色」など、いろいろな特徴を同時に拾えます。
ポイントは、同じフィルタを画像全体で使い回すこと。これを「重みの共有」と呼びます。おかげで覚えるべき数(パラメータ)がぐっと減り、しかも「猫の耳が左にあっても右にあっても同じ耳として見つけられる」という強さが生まれます。
畳み込みのあとによく置かれるのがプーリング(pooling)です。これは、特徴マップを少し荒くまとめて小さくする操作。たとえば「2×2の範囲でいちばん強い反応だけ残す」といったふうに、情報を間引きます。
「畳み込みで特徴を見つけ、プーリングで圧縮する」——この2つをセットで何度もくり返すのが、CNNの基本リズムです。
CNNの面白さは、層を重ねるほど“見るもの”が抽象的になっていくことです。
だれかが「ここは線」「ここは耳」と教えたわけではありません。大量の画像と正解ラベルから、AISが自分でこの階層的な見方を獲得していくのがディープラーニングのすごさです。最後は特徴マップを平らにならし、全結合層で「犬:90%/猫:10%」のように分類します。
「全部つなぐ全結合ではダメなの?」という疑問はもっともです。表で違いを整理しましょう。
| 全結合(ふつうのNN) | CNN(畳み込み) | |
|---|---|---|
| つなぎ方 | すべての画素を次の層へ | 小さなフィルタで局所だけ |
| パラメータ数 | 膨大(画像だと爆発) | フィルタを使い回して少ない |
| 位置のズレ | 弱い(場所が変わると別物) | 強い(どこにあっても同じ特徴) |
| 得意 | 表形式の数値データ | 画像・音声など格子状データ |
画像のように「近所に意味があり、同じ模様が場所を問わず現れる」データでは、CNNの作りが圧倒的に有利。これがCNNが画像認識の定番になった理由です。
CNNは、いまも画像まわりの土台技術として広く使われています。
近年は言語で活躍するTransformerを画像に応用する流れ(Vision Transformer)も出ていますが、CNNの「局所を見て、重ねて抽象化する」考え方は、いまも画像AIの基礎として生き続けています。
畳み込みのフィルタは、よく「特徴の型紙」にたとえられます。たとえば「左が暗くて右が明るい」という型紙を画像に重ねると、ちょうどそういう“縦の境目(エッジ)”がある場所でピタッと合って、強く反応します。
大事なのは、この型紙を人間が手で設計するのではなく、学習を通じてAIが「役に立つ型紙」を自分で見つけること。最初はでたらめな型紙が、大量の画像で訓練するうちに、エッジや色、模様をうまく拾う型紙へと育っていきます。何十・何百という型紙が、画像のいろいろな側面を同時に見張っているイメージです。
CNNを一から学習させるには、大量の画像と時間が必要です。そこで実務で大活躍するのが転移学習です。
これは、すでに大量の画像で訓練済みのCNN(ImageNetという巨大データで学んだものが有名)を土台にして、自分の目的に合わせて“仕上げ”だけをやり直す方法です。浅い層が学んだ「エッジや模様を見る力」は、どんな画像でも共通して役立つので、そのまま借りられます。おかげで、手元のデータが少なくても、高い精度のモデルを短時間で作れるのです。
「学習済みの力を借りて、必要なところだけ学び直す」——この考え方は、LLMのファインチューニングとも通じる、ディープラーニング全体に共通する実用テクニックです。
CNNのアイデア自体は1990年代からありました(手書き数字を読むLeNetが有名です)。流れが一変したのが2012年。AlexNetというCNNが画像認識コンテストで圧倒的な成績を出し、ディープラーニング時代の幕を開けました。
その後も、層をさらに深く積めるよう工夫したモデル(ResNetなど)が登場し、人間に迫る・超える精度が報告されていきました。CNNの進化の歴史は、そのままディープラーニング・ブームの歴史そのものでもあったのです。
万能に見えるCNNにも、苦手はあります。畳み込みは“近所”を見るのが得意な反面、画像全体にまたがる遠く離れた関係——たとえば「左上の物と右下の物の関係」——をとらえるのは、あまり得意ではありません。窓を少しずつずらして見ていく以上、遠い場所どうしを直接結びつけにくいのです。
この“遠くを一気に見比べる”のが得意なのが、言語で活躍するAttentionの発想でした。近年は画像にもこれを応用したVision Transformerが伸びていますが、計算が軽く、少ないデータでも学びやすいCNNは、いまも多くの現場で第一候補です。**データ量や目的に応じて、CNNとTransformerを使い分ける**のが実情です。
とはいえ、画像を学ぶ最初の一歩としてCNNは最適です。畳み込みとプーリングという直感的な仕組みは、ディープラーニング全体の“ものの見方”を理解する土台にもなります。ここをつかんでおけば、より新しい画像モデルの解説も読み解きやすくなるはずです。
CNN(畳み込みニューラルネットワーク)は、画像を見るために特化したディープラーニングの配線です。小さなフィルタで画像をなぞる「畳み込み」で特徴を見つけ、「プーリング」で圧縮する。これをくり返すことで、線→形→物体と、だんだん抽象的な特徴をとらえていきます。
「重みの共有」と「位置のズレへの強さ」という2つの工夫が、画像という難しいデータをAIに扱えるものへと変えました。次回は、画像ではなく“順番のあるデータ”を扱うRNN・LSTMに進みます。
CNN=画像のための配線。
畳み込み=小さなフィルタで局所をなぞって特徴を発見/プーリング=間引いて圧縮。
層を重ねて「線→形→物体」と抽象化し、最後に分類する。
A. 画像を扱うために特化したディープラーニングのモデルです。小さなフィルタを画像上でずらしながら特徴を見つける『畳み込み』と、情報を間引く『プーリング』を繰り返し、画像分類や物体検出などに使われます。
A. 小さなフィルタ(特徴の型紙)を画像の上で少しずつずらしながら当て、反応の強さを記録する操作です。たとえば縦線に反応するフィルタを使えば、縦線のある場所だけが強く反応し、その『反応の地図』が特徴マップになります。
A. 特徴マップを少し荒くまとめて小さくする操作です。計算を軽くし、特徴の位置が多少ずれても拾えるようにし、細かすぎる情報を捨てて本質を残す効果があります。畳み込みとセットで繰り返されます。
A. 同じフィルタを画像全体で使い回す『重みの共有』により、覚えるパラメータが少なく済み、さらに『特徴が画像のどこにあっても同じものとして見つけられる』ためです。近所の画素に意味がある画像データの性質をうまく利用しています。
A. ふつうの全結合ネットは全画素を次の層につなぐためパラメータが爆発しますが、CNNは小さなフィルタで局所だけを見るのでパラメータが少なく、位置のズレにも強いです。表形式の数値は全結合、画像はCNNが向きます。
A. 画像分類・物体検出、医療画像からの病変検出、自動運転の歩行者や標識の認識、顔認証や手書き文字認識などに使われています。画像まわりの土台技術として広く活用されています。
A. 言語で主流のTransformerを画像に応用するVision Transformerも登場していますが、CNNの『局所を見て重ねて抽象化する』考え方は今も画像AIの基礎として広く使われています。用途によって使い分けられています。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。モデルの詳細や最適な使い方は用途・データによって変わります。