CNNとは?畳み込みニューラルネットワークの仕組みをやさしく図解
ルミィ
AIの歩き方

前回のCNNは画像のための配線でした。今回は、文章・音声・株価のように「順番に意味があるデータ(系列データ)」のための配線——RNN(再帰型ニューラルネットワーク)とその改良版LSTMを扱います。
「私は猫が好き」という文の意味は、単語の“並び順”で決まります。前の言葉を覚えていないと、次の言葉は理解できません。この「前を覚えながら順に処理する」ためにRNNは生まれました。図でやさしく見ていきましょう。
この連載は、ニューラルネットとは?とディープラーニングの学習で学んだ「基本のしくみ」を土台にしています。まだの方は先に読むと、よりスッと入ってきます。
🧠 連載「ディープラーニングの地図」(全5回)
ニューラルネットの基本を土台に、画像・系列・生成といった“目的ごとの配線(アーキテクチャ)”を順にたどる連載です。

CNNが『画像の配線』なら、RNNは『順番のあるデータの配線』。カギは“前の記憶を次へ渡す”ループだよ。
ふつうのニューラルネットは、入力を受け取って出力するだけで、過去のことは覚えていません。これでは「順番」が大事なデータを扱えません。
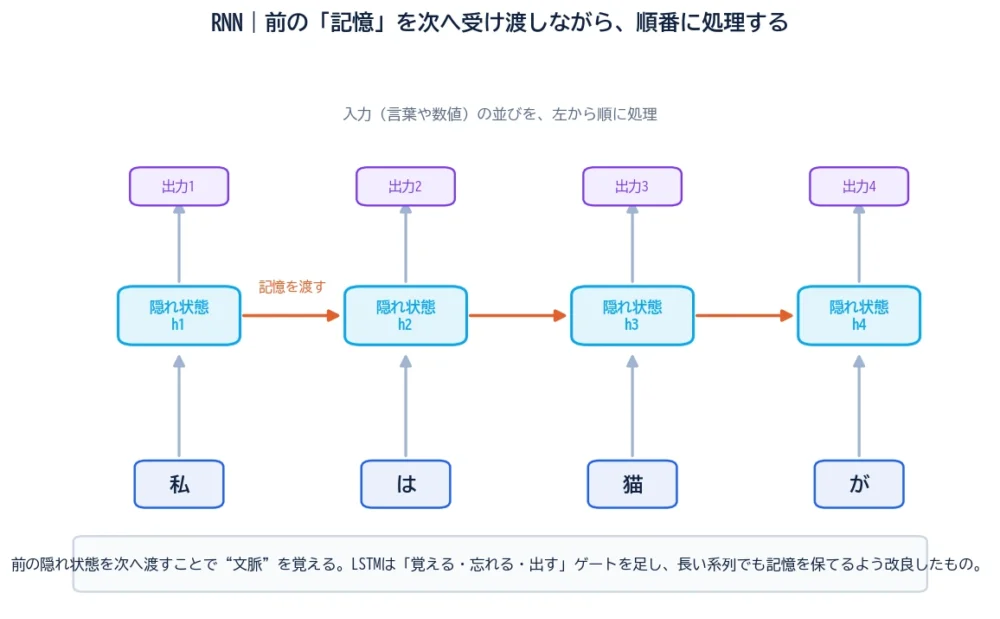
RNNは、ここにループを加えました。図のように、各ステップで「いまの入力」と「前のステップの記憶(隠れ状態)」の両方を受け取り、新しい記憶を作って次へ渡します。文章なら単語を1つずつ、株価なら1日ずつ、前の情報を引き継ぎながら処理していくわけです。
この“記憶を渡すバケツリレー”のおかげで、RNNは「文脈」を扱えます。たとえば「それ」が何を指すかは前の文を覚えていないと分かりませんが、RNNは前の隠れ状態にその手がかりを残せるのです。
系列データ(順番に意味があるデータ)は、身の回りにあふれています。
これらに共通するのは、「いまの値」だけでなく「これまでの流れ」が大事だということ。CNNが“空間(近所)”の関係を捉えるのに対し、RNNは“時間(順番)”の関係を捉えるのが得意、と整理できます。
便利なRNNですが、大きな弱点がありました。系列が長くなると、昔の情報が薄れて消えてしまうのです。
原因は、学習のときに過去へさかのぼって誤差を伝える過程で、勾配(修正の手がかり)がどんどん小さくなってしまう「**勾配消失**」という現象です。
たとえば長い文章で「最初に出てきた主語」を、文の終わりまで覚えていられない。そんな“もの忘れ”が起きてしまいます。この弱点を解決するために生まれたのが、次のLSTMです。
LSTM(Long Short-Term Memory)は、RNNにゲートという仕掛けを足した改良版です。ゲートとは、情報の流れを調整する“蛇口”のようなもの。LSTMは大きく3つのゲートを持ちます。
この仕組みで、LSTMは「大事なことは長く覚え、いらないことは忘れる」を自分で学べます。おかげで長い系列でも記憶を保ちやすくなり、機械翻訳や音声認識の精度が大きく伸びました。LSTMを少し簡単にしたGRUという親戚もよく使われます。
RNN・LSTMは、2010年代の系列データ処理を支えました。
RNN・LSTMには、もう一つ弱点がありました。前から順に処理するので、計算を並列にしにくく、とても長い文脈も苦手だったのです。
この壁を破ったのが、Attention(注意機構)と、それを全面採用したTransformerでした。「順番に渡す」のではなく「離れた単語どうしを一気に見比べる」発想で、並列処理と長文脈を可能にし、いまの大規模言語モデル(LLM)の土台になりました。
とはいえ、「前の情報を記憶として引き継ぐ」というRNNの基本思想は、系列を理解するうえでの出発点。ここを押さえておくと、TransformerやLLMの“ありがたみ”がいっそうよく分かります。
RNNが文を読む様子を、1単語ずつ追ってみましょう。
ポイントは、各ステップの隠れ状態が“それまで読んだ全部”を要約した記憶になっていること。だからRNNは、単語をバラバラにではなく、つながりとして理解できるのです。
RNNには、用途に応じた発展形があります。代表的な2つを紹介します。
このseq2seqの「エンコーダ・デコーダ」という発想や、そこに加えられたAttentionが、のちのTransformerへと発展していきました。RNNは、いまのAIへの大事な踏み石だったのです。
ここまでで、ディープラーニングの2大基本アーキテクチャが出そろいました。前回のCNNとあわせて整理しておきましょう。
| CNN | RNN・LSTM | |
|---|---|---|
| 得意なデータ | 画像(空間・近所の関係) | 文章・時系列(順番の関係) |
| カギの仕掛け | 畳み込み(フィルタ) | ループ(記憶の受け渡し) |
| 代表用途 | 画像分類・物体検出 | 翻訳・音声認識・予測 |
「画像ならCNN、順番のあるデータならRNN」が基本の住み分けでした。どちらも“ふつうのニューラルネットを、データの性質に合わせて組み替えたもの”という点は共通しています。
言語処理の主役はTransformerに移りましたが、RNN・LSTMが消えたわけではありません。Transformerは強力な反面、計算が重く、長い系列ほどメモリを多く使います。
そのため、スマホや組み込み機器のような“非力な環境”でのリアルタイム処理や、比較的短い時系列の予測では、軽量なRNN・LSTMがいまも現役で使われています。「いつでもTransformerが正解」ではなく、使える計算資源と扱うデータの長さに応じて選ぶ、というわけです。
そして何より、「前の情報を記憶として引き継ぐ」というRNNの考え方を知っておくことは、TransformerやLLMがなぜ生まれたのかを理解する近道になります。土台を押さえてこそ、最新技術のありがたみが分かるのです。
RNN(再帰型ニューラルネットワーク)は、ループで“記憶”を持ち、前の情報を次へ渡しながら、順番のあるデータを処理する配線です。長い系列で記憶が薄れる弱点(勾配消失)を、「覚える・忘れる・出す」ゲートで解決したのがLSTMでした。
文章・音声・株価・センサーログと、世の中は“順番のあるデータ”であふれています。その「順番」を扱う発想の原点がRNNであり、その記憶力を鍛えたのがLSTM・GRUでした。いまでこそTransformerが主役ですが、RNNが切り開いた『過去を覚えて、次に活かす』という考え方は、AIが時間や文脈を理解するための、いちばん大事な第一歩。ここを押さえておけば、続くTransformerやLLMの解説も、きっとすんなり読めるはずです。次回からは、判別ではなく“生成”——データそのものを生み出すネットワークへと話が移っていきます。
文章・音声・時系列など、世の中の多くのデータは“順番”を持っています。その扱い方の出発点がRNN・LSTM。そして、その限界を超えるために生まれたのがTransformerであり、LLMへとつながっていきます。次回は、生成の入り口となる「オートエンコーダ」に進みます。
RNN=ループで記憶を持ち、系列を順番に処理する配線。
弱点(長い記憶が薄れる=勾配消失)をゲートで解決したのがLSTM。
その先の並列処理・長文脈はTransformer/LLMへ。
A. 文章や時系列のように『順番に意味があるデータ』を扱うためのニューラルネットです。各ステップで今の入力と前の記憶(隠れ状態)の両方を受け取り、記憶を次へ渡しながら順番に処理することで、文脈を扱えます。
A. CNNは画像のように『空間(近所)』の関係を捉えるのが得意で、RNNは文章や時系列のように『時間(順番)』の関係を捉えるのが得意です。扱うデータの性質が違います。
A. LSTMはRNNの改良版で、『忘却ゲート・入力ゲート・出力ゲート』という仕掛けを足したものです。これにより『大事なことは長く覚え、いらないことは忘れる』を学べ、長い系列でも記憶を保ちやすくなります。
A. 学習時に過去へさかのぼって誤差を伝える際、修正の手がかり(勾配)がどんどん小さくなって消えてしまう現象です。これにより、ふつうのRNNは長い系列の昔の情報を覚えていられなくなります。LSTMはこれを緩和します。
A. 機械翻訳、音声認識、文章生成や予測変換、株価や需要などの時系列予測に使われてきました。2010年代の系列データ処理を支えた中心的な技術です。
A. 並列処理や長文脈に強いTransformerが主流になり、言語処理ではRNNの出番は減りました。ただし軽量な時系列処理など今も使われる場面はあり、『記憶を引き継ぐ』という基本思想はTransformerやLLMを理解する出発点になります。
A. GRU(ゲート付き回帰ユニット)は、LSTMをやや簡単にした親戚のような仕組みです。ゲートの数が少なく計算が軽い一方、多くの場面でLSTMに近い性能を出せるため、よく使われます。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。モデルの詳細や最適な使い方は用途・データによって変わります。