ヒストグラムとは?作り方と見方・棒グラフとの違いをやさしく図解
ルミィ
AIの歩き方

前回のクラスタリングに続いて、もう一つの教師なし学習を扱います。主成分分析(PCA)——たくさんの情報を、大事な少数の軸にぎゅっとまとめる「次元削減」の代表です。
「特徴量が多すぎて扱いに困る」「データを2次元のグラフで眺めたい」——そんなときに活躍します。名前は難しそうですが、考え方はシンプル。情報がいちばん大きく広がっている向きを見つけて、そこにデータを集約するだけです。図でやさしく見ていきましょう。
🧭 連載「機械学習の地図」(全5回)
線形回帰や決定木の“その先”——機械学習の全体像と、回帰・木以外の代表的な考え方を、順番にやさしくたどる連載です。

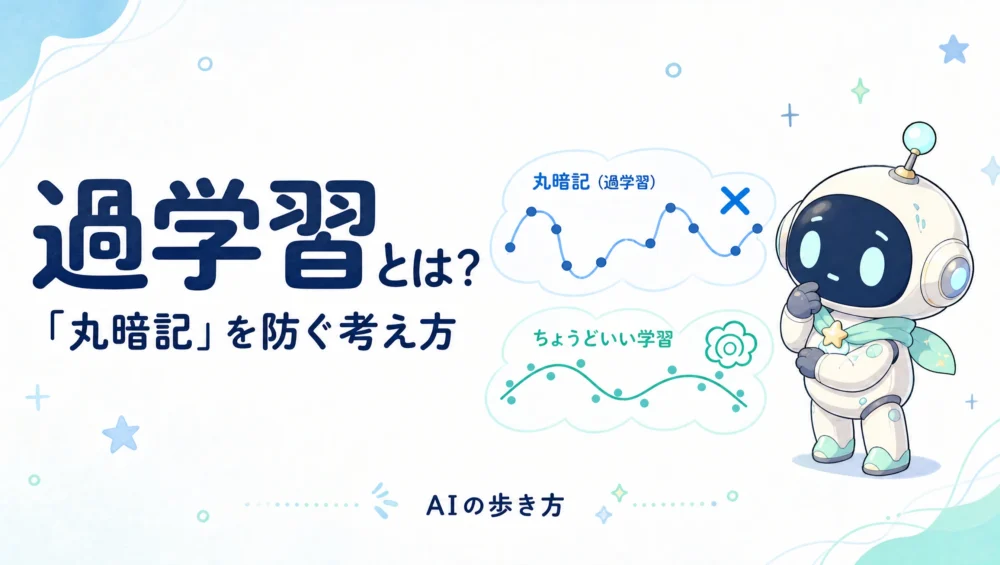
情報が多すぎると、かえって見えなくなる。大事な軸だけ残すのが次元削減。その王道がPCAだよ。
データには、たくさんの特徴量(列)が含まれます。たとえば顧客データなら、年齢・年収・購入回数・滞在時間…と、何十・何百もの項目があります。この項目の数を次元と呼びます。
ところが、次元が多すぎると逆に困ります。グラフに描けない(人間は3次元までしか見えない)、計算が重くなる、似た項目が混ざって扱いにくい——こうした問題は「次元の呪い」とも呼ばれます。
そこで、大事な情報をできるだけ保ったまま、項目の数を減らすのが次元削減です。100項目を2〜3項目に圧縮できれば、グラフに描けて、計算も軽くなります。
PCA(主成分分析)は、次元削減の王道です。やっていることは、「データがいちばん大きく広がっている向き」を見つけることです。
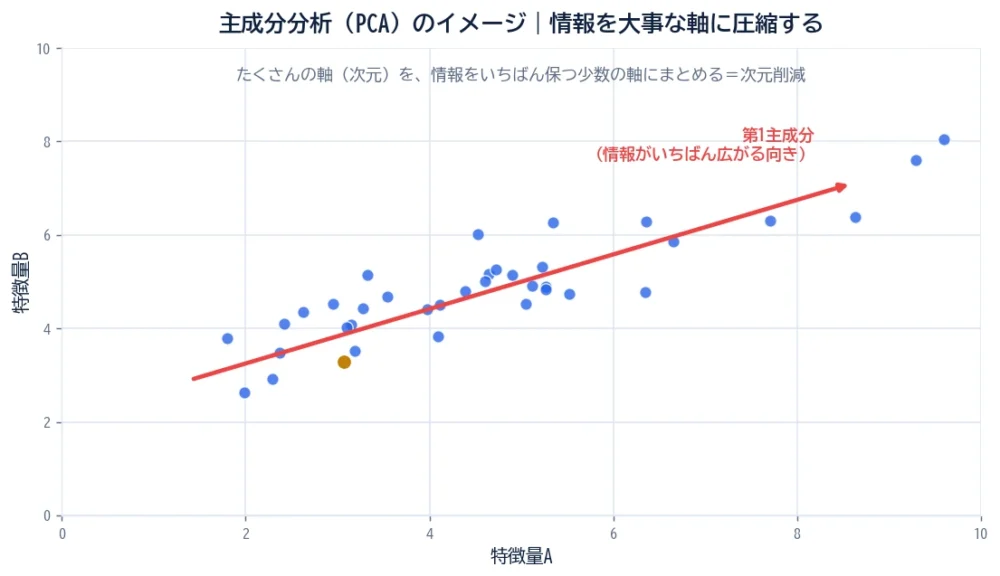
図を見てください。データは右上がりに広がっています。このいちばん広がっている向き(赤い矢印)が「第1主成分」です。データの“個性”がいちばんよく表れる方向なので、この軸に沿ってデータを並べ直せば、1本の軸だけでも多くの情報を保てます。
次に広がっている向き(第1主成分と直角の方向)が第2主成分…と続きます。広がりの大きい主成分だけを残し、小さいものを捨てることで、情報をあまり失わずに次元を減らせる、というのがPCAの肝です。
PCA=「情報がいちばん広がる向き(主成分)」を見つけて、そこにデータを集約する。広がりの小さい向きを捨てれば、情報を保ったまま次元を減らせる。
PCAは、データ分析の“前さばき”として幅広く使われます。
「いきなりモデルに突っ込む前に、データを整理して見通しをよくする」——そんな縁の下の力持ちとして働きます。
PCAのありがたみは、具体例で見るとはっきりします。生徒たちの「国語・社会・英語・数学・理科」5教科の点数データがあるとしましょう。5次元なのでグラフには描けません。
ここにPCAをかけると、多くの場合こんな2つの軸が浮かび上がります。
5つの点数を、「総合学力」と「文理の傾き」という2軸に圧縮できました。これなら散布図に描けて、生徒の分布がひと目で分かります。元の5項目を混ぜ合わせて、意味のある少数の軸を作り直す——これがPCAのやっていることの正体です。
中身の数式は使いませんが、流れだけ知っておくと安心です。PCAは、ざっくり次の順で進みます。
「①そろえて、②広がりを見て、③順に取り出し、④上位だけ残す」。この4ステップだけ押さえておけば、ツール(ExcelやPython)が中身を計算してくれます。
「次元を減らすと情報が減るのでは?」という心配はもっともです。これを測るのが寄与率(説明できる情報の割合)です。
たとえば「第1主成分+第2主成分で、元の情報の85%を説明できる」なら、2次元に減らしても情報の大半は残っている、と判断できます。何次元まで残すかは、この寄与率を見て決めるのが定番。「8割〜9割の情報を保てるところまで減らす」といった使い方をします。
PCAにも、知っておきたい限界があります。
「解釈のしやすさ」と引き換えに「扱いやすさ」を得るのがPCA。目的が“予測の高速化や可視化”なら強力ですが、“なぜそうなるかの説明”が主目的なら、元の項目を残したほうがよい場面もあります。
次元削減や“まとめる”系の手法は、PCA以外にもあります。混同しやすいので、代表2つとの違いを押さえておきましょう。
ざっくり、「前処理や高速化が目的ならPCA」「とにかく綺麗に可視化したいならt-SNE/UMAP」「裏の原因を知りたいなら因子分析」と覚えておけば、選び方に迷いません。
PCAは単独で使うより、機械学習の“前処理”として組み込むことが多い手法です。よくある流れはこうです。
こうすると、計算が速くなるだけでなく、似た項目が混ざって起きる不安定さ(多重共線性)もやわらぎます。「いきなり全項目を突っ込まず、PCAで整えてから渡す」——これが、PCAの最も実践的な使い方です。
一点だけ注意。PCAは訓練データで決めた“圧縮ルール”を、テストデータにも同じように適用するのが鉄則です。テストデータまで含めて主成分を計算すると、本番の情報がこっそり学習に混じる「情報の漏れ」が起き、評価が甘くなります。次回の過学習とも通じる、地味だけれど大事な作法です。
主成分分析(PCA)は、たくさんの情報を、大事な少数の軸にまとめる次元削減の代表です。データがいちばん広がる向き(主成分)を見つけ、広がりの小さい向きを捨てることで、情報をできるだけ保ったまま項目を減らします。
名前の物々しさに比べて、やっていることは「情報がいちばん広がる向きを探して、そこにまとめる」というシンプルなもの。5教科を“総合学力”と“文理の傾き”にまとめた例のように、たくさんの数字の裏にある“意味のある軸”を見つけ出してくれます。可視化の前さばき、機械学習の高速化、ノイズ除去——使いどころは幅広く、データ分析の基礎体力として一度つかんでおく価値のある手法です。
実務では「標準化→PCA→本命のモデル」という前処理パイプラインの一部として登場することが多いので、単体の魔法というより“縁の下の整え役”としてイメージしておくとよいでしょう。寄与率で「どれだけ情報を残せるか」を確かめながら、まずは手元の多項目データを2次元に落として眺めてみるのがおすすめです。
可視化・高速化・ノイズ除去と、データ分析の前さばきで広く活躍します。寄与率で「どれだけ情報を保てるか」を確かめながら使うのがコツです。
次元削減=情報を保ったまま項目(次元)を減らす。
PCA=情報がいちばん広がる向き(主成分)に集約する。
寄与率で「何%の情報を残せるか」を確認して使う。
次回からは、機械学習を“うまく使う”ための話に移ります。まずは多くの人がつまずく過学習から。
A. たくさんの特徴量(次元)を、情報をできるだけ保ったまま少数の軸に圧縮する次元削減の手法です。データがいちばん大きく広がる向き(主成分)を見つけ、そこにデータを集約します。教師なし学習の一つです。
A. 特徴量が多すぎると、グラフに描けない・計算が重い・似た項目が混ざる、といった問題(次元の呪い)が起きます。大事な情報を保ったまま項目を減らすことで、可視化や計算の高速化ができます。
A. データがいちばん大きく広がっている向きが第1主成分、それと直角で次に広がる向きが第2主成分…と続きます。広がりの大きい主成分ほど、データの個性をよく表しています。
A. 選んだ主成分で、元の情報の何割を説明できるかを表す割合です。たとえば第1・第2主成分で85%なら、2次元に減らしても情報の大半が残っていると判断できます。何次元まで残すかの目安になります。
A. 高次元データを2次元に落として可視化する、機械学習の計算を軽くする前処理、ノイズ除去、似た項目の整理などに使われます。クラスタリングの前処理としてもよく使われます。
A. 主成分は元の項目を混ぜたものなので軸の意味が分かりにくいこと、直線的な広がりを前提とするため複雑な構造は苦手なこと、特徴量のスケールに影響されることです。事前の標準化が基本です。
A. どちらも教師なし学習ですが、目的が違います。クラスタリングは似たデータをグループに分ける手法、PCAは特徴量(次元)を減らして情報を圧縮する手法です。PCAでデータを整理してからクラスタリングする、といった併用もよくあります。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わるため、実務では各手法の前提条件もご確認ください。