標準偏差とは?分散との違いとデータのばらつきをやさしく図解
ルミィ
AIの歩き方

連載の最終回は、「作ったAIが本当に使えるのか」を測る話です。前回の過学習で「本番で通用するかが大事」と分かりましたが、その“通用するか”を、どんなものさし(評価指標)で測ればいいのでしょうか。
「正解率が90%!」と聞くと優秀そうですが、実はそれだけでは判断できないことがあります。この記事では、AIの成績を正しく読むための基本——混同行列・適合率・再現率・F値・AUC——を、図でやさしく整理します。
🧭 連載「機械学習の地図」(全5回)
線形回帰や決定木の“その先”——機械学習の全体像と、回帰・木以外の代表的な考え方を、順番にやさしくたどる連載です。

「正解率90%」が実はダメダメ、ということもある。評価指標を知らないと、AIの実力を見誤るよ。
分類AIの成績は、混同行列という4マスの表で整理すると、すっきり見えます。「予測」と「実際」の組み合わせで、結果は4種類に分かれます。
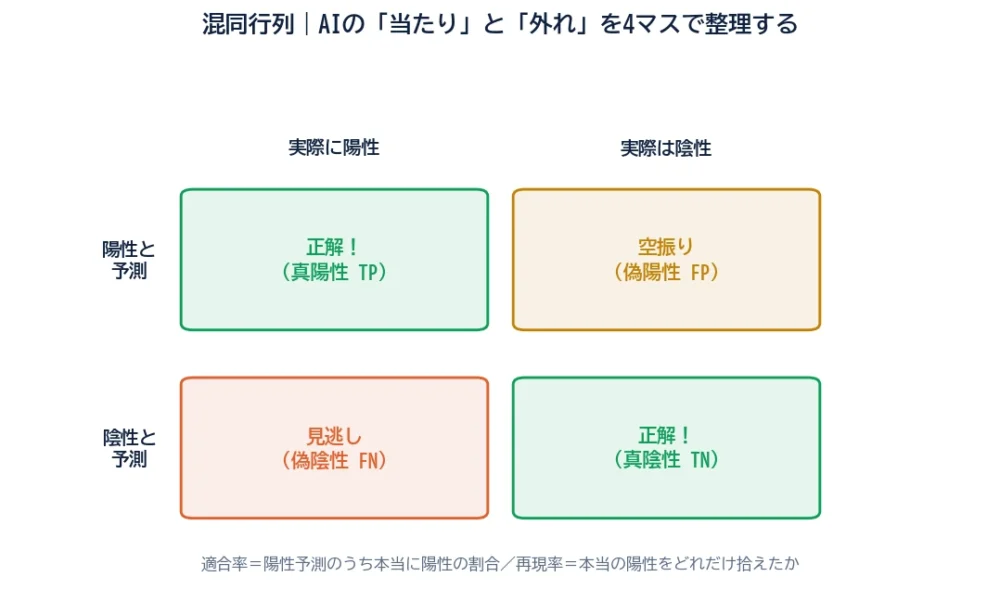
病気の検査AIを例に、4マスを読んでみましょう。
ポイントは、同じ「外れ」でも、空振り(FP)と見逃し(FN)では深刻さが違うこと。病気の見逃しは命に関わりますが、空振りは再検査で済みます。だから「全部の正解率」だけでは、本当に大事な誤りが見えないのです。
いちばん分かりやすい指標が正解率——全体のうち、何件当たったかの割合です。ただ、これには有名な落とし穴があります。データがかたよっているときです。
たとえば「1000人に1人だけがかかる病気」を判定するAIが、全員に「陰性」と答えるだけでも、正解率は99.9%になります。一見すごい数字ですが、肝心の病気の人を1人も見つけられない、まったく役立たないAIです。正解率だけを見ると、こういう“ずるい正解”にだまされます。
正解率は分かりやすいが、データがかたよると当てにならない。「全部ハズレ側に答えるだけ」で高得点が出てしまうことがある。
そこで登場するのが、適合率(precision)と再現率(recall)です。この2つは、混同行列の見る向きが違います。
大事なのは、この2つはトレードオフになりやすいこと。「少しでも怪しければ陽性」と判定を甘くすれば、見逃しは減りますが(再現率↑)、空振りが増えます(適合率↓)。逆も同じです。だから目的しだいでどちらを重視するかが変わります。
がん検診のように見逃しが命取りなら再現率を重視し、迷惑メール判定のように大事なメールを誤って弾きたくないなら適合率を重視する——というふうに、使い分けます。
適合率と再現率のどちらも大事なときに使うのがF値(F1スコア)です。2つのバランスを1つの数字にまとめたもので、「両方をそこそこ高く保てているか」を表します。
もう一つよく聞くのがROC曲線とAUCです。分類AIは「どれくらい怪しければ陽性とするか」というしきい値を持っていて、これを動かすと適合率・再現率が変わります。しきい値を端から端まで動かしたときの性能を1本の曲線(ROC)にし、その下の面積を数字にしたのがAUC。0.5が当てずっぽう、1.0が完璧で、AIの“地力”を測る指標としてよく使われます。
言葉だけだと分かりにくいので、実際に数えてみましょう。ある病気の検査AIを100人に使い、結果が次のようになったとします。
この数字から、各指標を計算してみます。
同じAIなのに、正解率93%・適合率62%・再現率80%と、見る指標で印象がまるで違います。「正解率93%」だけ聞いて優秀と思い込むと、2割の見逃しを見落とす——これが、複数の指標を合わせて見るべき理由です。病気の検査なら、まず再現率(見逃しの少なさ)に目を向けるべきだと分かります。
ここまでは「陽性か陰性か」の2択でしたが、「犬・猫・鳥」のように3つ以上に分類することもあります。その場合も考え方は同じで、混同行列が大きく(3×3など)なるだけです。
適合率や再現率は、クラスごとに計算してから平均します。全クラスを単純平均するマクロ平均(少数派のクラスも平等に見たいとき)と、件数で重みづけする方法を、目的に応じて選びます。「どのクラスが苦手か」をクラスごとに見られるのが、混同行列の強みです。
ここまでは分類(カテゴリ当て)の話でした。回帰(数値予測)の場合は、また別のものさしを使います。
「分類なら混同行列まわり、回帰ならRMSEやR²」と、やりたいことに合った指標を選ぶことが、評価の第一歩です。
最後に、指標を使ううえでの心がまえを3つ。
評価指標は、AIの通信簿。読み方を知っていれば、「すごそうな数字」にだまされず、本当に使えるAIかどうかを自分で見極められます。
さきほどの100人の例で、「どれくらい怪しければ陽性とするか」の基準(しきい値)を動かすと、適合率と再現率がどう変わるか見てみましょう。
ここで大事なのは、AIの“地力”は変えずに、しきい値という1本のつまみで、適合率と再現率のバランスだけを動かせるということ。だから「再現率を上げたい」と思ったら、モデルを作り直す前に、まずしきい値の調整で対応できないかを考えます。前に触れたAUCは、このつまみを端から端まで動かしたときの総合力を測った数字、というわけです。
「正解率が動かせないなら指標は固定」と思いがちですが、実際は目的に合わせて“どこで線を引くか”を選べます。評価指標を知ることは、この線引きを自分の手でコントロールできるようになることでもあります。
AIの評価は、正解率だけでは不十分です。混同行列で当たり外れを4マスに整理し、適合率(空振りの少なさ)と再現率(見逃しの少なさ)を、目的に応じて使い分ける。F値でバランスを、AUCで地力を測る。回帰ならRMSEやR²を使う——やりたいことに合ったものさしを選ぶことが肝心です。
そして、しきい値というつまみを動かせば、同じAIでも“見逃し重視”にも“空振り重視”にも調整できました。評価指標を読めるということは、AIの成績表を正しく解釈できるだけでなく、目的に合わせて性能のバランスを自分で選べるということでもあります。「正解率が高い=良いAI」という思い込みから一歩進んで、“どんな間違いなら許せて、どんな間違いは許せないのか”を考える。その視点を持てたなら、この連載の目的は果たせたと言えます。
これで連載「機械学習の地図」は完結です。3つの学び方から始まり、クラスタリング・PCAという教師なしの世界、そして過学習と評価という“うまく使う”ための考え方まで。線形回帰や決定木の“その先”が、ひとつながりの地図として見えてきたはずです。お疲れさまでした。
正解率だけでは不十分(かたよったデータに弱い)。
適合率=空振りの少なさ、再現率=見逃しの少なさ。目的で使い分ける。
F値でバランス、AUCで地力。回帰はRMSE・R²。
A. 分類AIの結果を「予測」と「実際」の組み合わせで4マスに整理した表です。真陽性(TP)・真陰性(TN)・偽陽性(FP・空振り)・偽陰性(FN・見逃し)に分かれ、どんな誤りをしているかが一目で分かります。
A. データがかたよっていると当てになりません。たとえば1000人に1人の病気を全員『陰性』と答えるだけで正解率99.9%になりますが、病気の人を1人も見つけられません。複数の指標を合わせて見る必要があります。
A. 適合率は『陽性と予測したうち本当に陽性だった割合』で、空振りの少なさを表します。再現率は『本当の陽性をどれだけ拾えたか』で、見逃しの少なさを表します。この2つはトレードオフになりやすく、目的に応じて重視する側を選びます。
A. 適合率と再現率のバランスを1つの数字にまとめた指標です。どちらか一方だけでなく両方をそこそこ高く保てているかを見たいときに使います。
A. 分類のしきい値を動かしたときの性能を1本の曲線にしたのがROC曲線、その下の面積を数字にしたのがAUCです。0.5が当てずっぽう、1.0が完璧で、AIの地力を測る指標としてよく使われます。
A. 数値予測の回帰では、予測と実際のズレを表すRMSEやMAE、モデルの説明力を表す決定係数R²などを使います。1に近いほど良いR²がよく使われます。
A. 目的によります。がん検診のように見逃しが命に関わる場合は再現率(見逃しの少なさ)を、迷惑メール判定のように大事なメールを誤って弾きたくない場合は適合率(空振りの少なさ)を重視します。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わるため、実務では各手法の前提条件もご確認ください。