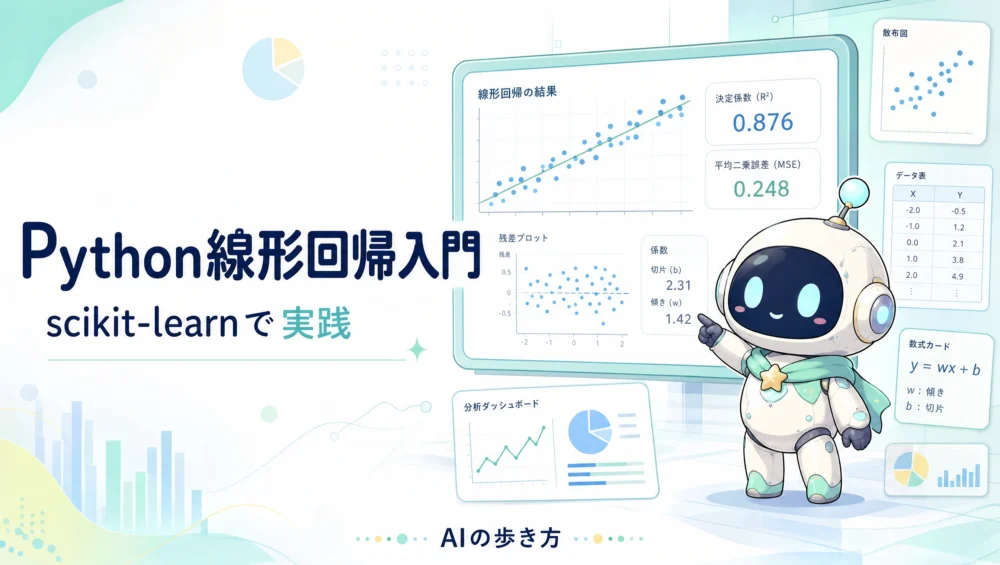
LightGBMとは?XGBoostとの違いと使い分けを初心者向けにやさしく解説
ルミィ
AIの歩き方

当サイトではこれまで、線形回帰や決定木といった機械学習の手法を個別に紹介してきました。でも、機械学習にはほかにも数えきれないほどの手法があります。バラバラに覚えると迷子になりますが、実は大きく3つの「学び方」に分けて見ると、一気に整理がつきます。
その3つが、教師あり学習・教師なし学習・強化学習です。この記事は、それぞれが何で、どう違い、どんな場面で使うのかを示す“機械学習の地図”。これを頭に入れておくと、新しい手法に出会っても「ああ、これは教師なしの仲間か」と置き場所が分かるようになります。
🧭 連載「機械学習の地図」(全5回)
線形回帰や決定木の“その先”——機械学習の全体像と、回帰・木以外の代表的な考え方を、順番にやさしくたどる連載です。

手法を1つずつ覚えるより先に、「3つの学び方」の地図を持っておくと、ぜんぶ整理しやすくなるよ。
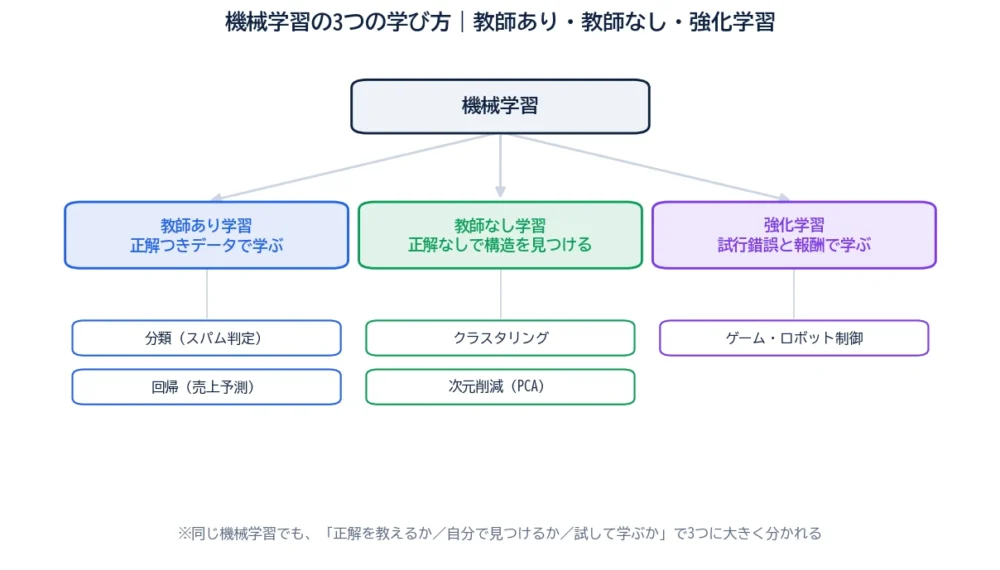
いちばん基本で、いちばん使われているのが教師あり学習です。「問題」と「正解」がセットになったデータを大量に見せて、その対応関係を学ばせます。テスト勉強で、問題集と解答を見比べて覚えるのに似ています。
教師あり学習は、やりたいことでさらに2つに分かれます。
当サイトでこれまで紹介してきた回帰・決定木・ランダムフォレスト・XGBoostは、すべてこの教師あり学習の仲間です。正解データさえ用意できれば強力なので、実務でいちばん登場します。
教師なし学習は、正解(ラベル)を与えません。データだけを渡して、その中に隠れた構造やパターンをAI自身に見つけさせます。「これが正解」と教える人がいないので“教師なし”です。
代表的なのは2つです。
正解を用意しなくていいので、「とりあえずデータを眺めて傾向をつかみたい」「人間が気づかないグループを見つけたい」ときに力を発揮します。
強化学習は、少し毛色が違います。正解を教える代わりに、良い行動には報酬、悪い行動には罰を与えて、「報酬が最大になる行動」を試行錯誤で学ばせます。ゲームで高得点を狙ううちに上手くなる感覚に近いです。
囲碁でプロを破ったAlphaGo、ロボットの歩行制御、ゲームAIなどが代表例です。「何をすれば正解か」を人が示せないけれど、結果の良し悪しは測れる——そんな問題に向いています。
教師あり=正解を見て学ぶ。教師なし=正解なしで構造を見つける。強化学習=試して報酬で学ぶ。この3つが機械学習の大きな地図です。
ここまでをまとめると、3つの違いは次の表のように整理できます。迷ったら、この表に立ち返れば大丈夫です。
| 学び方 | 正解データ | やりたいこと | 代表手法 | 身近なたとえ |
|---|---|---|---|---|
| 教師あり | 使う(問題+答え) | 分類・数値予測 | 線形回帰・決定木・ランダムフォレスト | 問題集と解答で勉強する |
| 教師なし | 使わない | グループ分け・要約 | k-means・PCA | 本棚を見て似た本を自分でまとめる |
| 強化学習 | 使わない(報酬で代替) | 最適な行動を見つける | Q学習・方策勾配法 | ゲームで試行錯誤して上達する |
こうして並べると、「正解データを使うのは教師ありだけ」「教師なしと強化学習は正解なしで、目的が違う」という関係がはっきりします。手法の名前は今は覚えなくて大丈夫。まずは“列の違い”をつかんでおけば十分です。
迷ったら、次の2つを自分に問うだけで、だいたい見分けられます。
実務では、まず教師ありで解けないかを考え、正解データが用意できなければ教師なしで探索する、という順番が一般的です。
最近よく聞くのが自己教師あり学習です。人がラベルを付けるのではなく、データ自身から“正解”を自動で作って学ぶやり方で、教師ありと教師なしの中間のような存在です。
じつは、いまのLLMの事前学習がこれです。「文章の次の単語を当てる」という問題は、文章さえあれば正解(次の単語)が自動で決まるので、人手のラベル付けなしに大量に学習できます。生成AIの急成長を支えた立役者でもあります。
3つの違いは、同じ題材を使うとぐっと腑に落ちます。「メール」を例に、それぞれの学び方が何をするかを見てみましょう。
同じメールというデータでも、「いま手元に何があって、何をしたいか」によって、使う学び方が変わります。これこそ“地図”を持つ意味です。
もう一つ大事なのは、現実のシステムは1つの学び方だけで完結しないことが多い、という点です。代表的なサービスは、いくつもの学び方を重ねて動いています。
だから、「どれか1つを選ぶ」と考えるより、「いま自分は地図上のどこを使っているのか」を意識するほうが、ずっと実践的です。
初心者がまず手をつけるなら、教師あり学習がおすすめです。理由は3つあります。
教師ありに慣れたら、教師なし(クラスタリング・PCA)へ広げ、必要を感じたら強化学習へ——という順番が、無理なく地図を埋めていくコツです。
よくある疑問が「ディープラーニングはどの仲間?」というものです。答えは、ディープラーニングは4つ目の学び方ではなく、3つのどれにも使える“道具(モデルの作り方)”です。
「学び方(教師あり・なし・強化)」が“目的と進め方”の分類なのに対し、ディープラーニングは“脳のしくみを真似た多層のネットワークで学ぶ”という手段の話です。だから、教師あり×ディープラーニング(画像分類)も、強化学習×ディープラーニング(ゲームAI)も成り立ちます。「何を学ぶか(学び方)」と「どんな仕組みで学ぶか(モデル)」は別の軸だと整理しておくと、混乱しません。
この関係をもっと詳しく知りたい方は、機械学習・ディープラーニング・生成AIの違いもあわせてどうぞ。
最後に、初心者がつまずきやすい言葉のペアを整理しておきます。ここを押さえると、どの言葉がどの仲間か、迷いにくくなります。
言葉のペアで覚えると、新しい用語に出会っても「これは分類の話だな」と置き場所が見えてきます。
機械学習は、手法の数こそ多いものの、学び方で見れば「教師あり・教師なし・強化学習」の3つに大きく分かれます。正解データがあるか、何をしたいか——この2つを問えば、どの仲間かはだいたい見分けられます。
そして、ディープラーニングは“4つ目の学び方”ではなく、3つのどれにも使える道具でした。学び方(目的)とモデル(手段)は別の軸——この2軸で捉えると、日々流れてくる新しい技術ニュースを見ても、「これは教師あり×ディープラーニングの話だな」と、自分の地図の上に正しく置けるようになります。手法の名前を一つずつ追いかけるより、まずこの地図を持つこと。それが、機械学習を学び続けるうえでいちばんの近道です。
個別の手法を覚える前に、この地図を持っておくこと。それだけで、機械学習の世界はぐっと見通しがよくなります。次回からは、まだ当サイトで扱っていない教師なし学習——クラスタリングとPCA——を順に見ていきます。
教師あり=正解つきで分類・予測(線形回帰・決定木など)。
教師なし=正解なしでグループ分け・要約(クラスタリング・PCA)。
強化学習=試行錯誤と報酬で最適な動きを学ぶ。
A. 教師あり学習は「問題と正解」がセットのデータで対応関係を学び、分類や予測に使います。教師なし学習は正解(ラベル)を与えず、データの中の構造やパターンをAI自身に見つけさせる方法で、クラスタリングや次元削減が代表です。
A. 良い行動には報酬、悪い行動には罰を与えて、報酬が最大になる行動を試行錯誤で学ばせる方法です。囲碁AIのAlphaGoやロボット制御、ゲームAIが代表例で、「正解は示せないが結果の良し悪しは測れる」問題に向いています。
A. どちらも教師あり学習です。線形回帰は数値を予測する『回帰』、決定木は分類にも回帰にも使えますが、よく『分類』の例で紹介されます。正解データを使って学ぶ点が共通しています。
A. 教師あり学習がおすすめです。正解と比べられて結果が分かりやすく、実務での出番も多いためです。回帰や決定木から始め、慣れたら教師なし(クラスタリング・PCA)へ広げると無理がありません。
A. 人がラベルを付ける代わりに、データ自身から正解を自動で作って学ぶ方法です。たとえば『文章の次の単語を当てる』は文章さえあれば正解が決まるため、人手なしで大量に学習できます。現代のLLMの事前学習がこれにあたります。
A. あります。少量の正解つきデータと、大量の正解なしデータを組み合わせて学ぶ方法です。ラベル付けはコストがかかるため、少しの正解と多くの未ラベルデータを活かす現実的な選択肢として使われます。
A. 優劣ではなく、目的とデータで使い分けます。正解データがあり分類・予測したいなら教師あり、構造を探りたいなら教師なし、最適な動き方を学ばせたいなら強化学習が向きます。問題に合った地図上の場所を選ぶのがコツです。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わるため、実務では各手法の前提条件もご確認ください。