仮説検定・p値とは?偶然か意味のある差かをやさしく図解
ルミィ
AIの歩き方
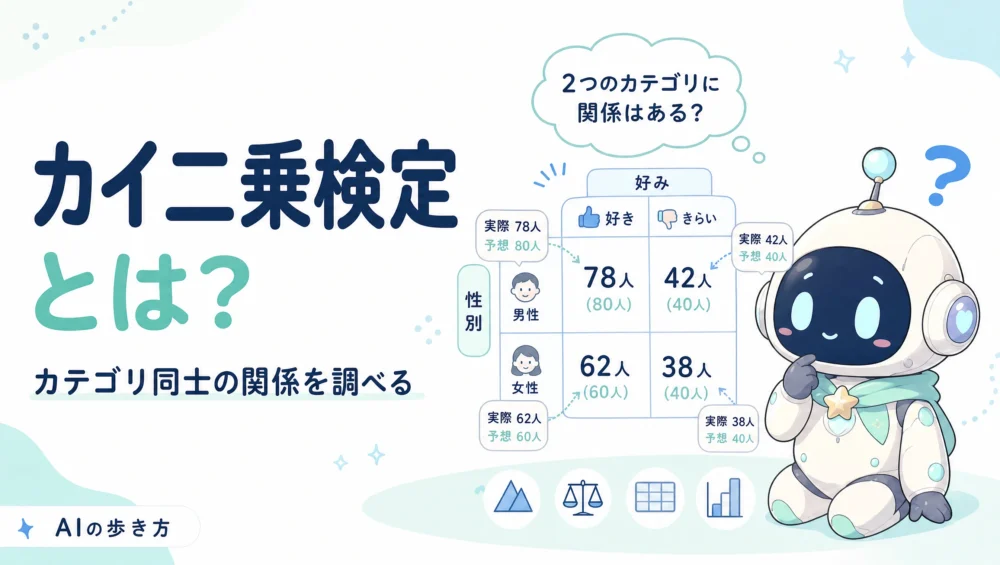
前回のt検定は「数値の平均」を比べる検定でした。今回のカイ二乗検定は、うって変わって「カテゴリ(種類)」同士の関係を調べる検定です。
「性別によって、好きな商品は違う?」「住んでいる地域と、契約プランに関係はある?」——こうした質的データ(カテゴリ)の関連を調べたいときに登場します。クロス集計表を使う、その仕組みを図でやさしく見ていきましょう。
この連載は、仮説検定・p値の“具体的な手法編”です。「帰無仮説・p値・有意水準」の考え方がまだの方は、先にそちらを読むとスッと入ってきます。
🧪 連載「統計的検定・推定の使い分け」(全4回)
「その差は偶然か、意味があるか」——代表的な検定(t検定・カイ二乗・分散分析)と、推定の区間(信頼区間)を、使い分けの視点で整理する連載です。

数値じゃなくて『種類』の関係を調べるのがカイ二乗。『もし関係なければこうなるはず』とのズレを見るんだ。
カイ二乗検定(χ²検定)は、質的データ(カテゴリ)を対象にした検定です。いちばんよく使われるのが独立性の検定——「2つのカテゴリ変数に関係があるか(独立か)」を調べるものです。
たとえば「性別(男・女)」と「好きな商品(A・B)」。この2つに関係があるのか、それとも無関係(独立)なのか。これを、クロス集計表の数字から判断します。
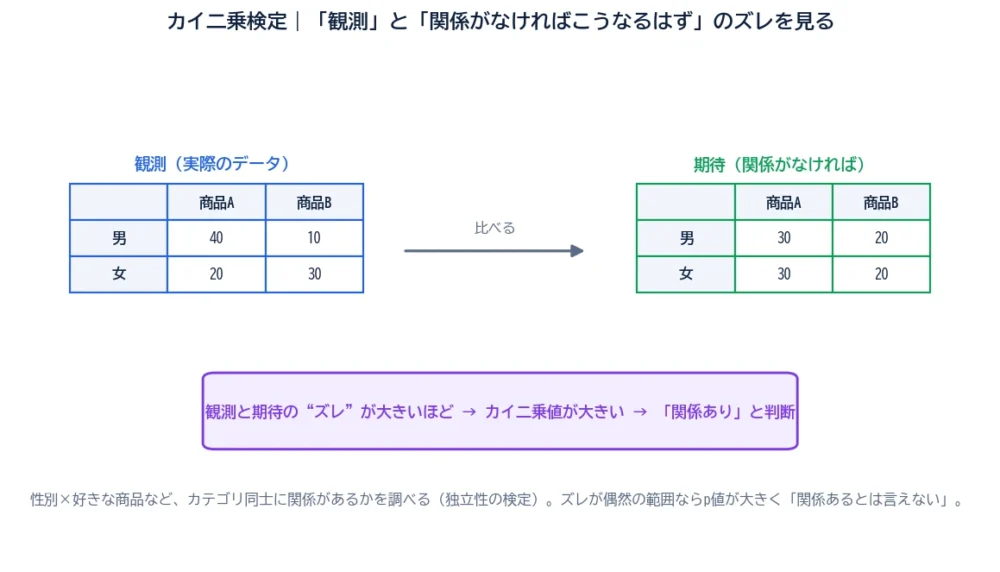
カイ二乗検定の発想は、とてもうまくできています。「もし2つのカテゴリに関係がなかったら、表の数字はこうなるはず」という“期待”を計算し、それと“実際(観測)”のズレを測るのです。
図を見てください。左が実際のデータ(観測度数)、右が「関係がなければこうなるはず」という理論値(期待度数)。この2つのズレが大きいほど、「偶然ではなく、関係がある」と考えます。そのズレの大きさを1つの数字にまとめたのが、カイ二乗値です。
カイ二乗値は、Σ(観測 − 期待)² ÷ 期待で計算されます。ズレ(観測−期待)を二乗して、期待度数で割って合計する——式は少し複雑ですが、やっていることは「観測と期待の食い違いの合計」です。
カイ二乗検定=「関係がなければこうなるはず(期待)」と「実際(観測)」のズレを測る。ズレが大きいほど“関係あり”と判断する。
図の例で読んでみましょう。男性100人・女性50人に、商品AとBどちらが好きかを聞いた、とします。
実際には「男性はA寄り、女性はB寄り」という偏りがあり、期待値とのズレが大きい。だから「性別と好みには関係がありそう」と判断できます。逆に、観測が期待とほとんど同じなら、ズレ(カイ二乗値)は小さく、p値が大きくなって「関係があるとは言えない」となります。
カイ二乗検定には、もう一つの使い方「適合度の検定」もあります。これは、観測されたデータが、ある理論的な割合に合っているかを調べるものです。
たとえば「このサイコロは“イカサマ”ではないか?(各目が1/6ずつ出るはずか)」を確かめる、といった使い方です。仕組みは同じで、「理論どおりなら期待される回数」と「実際に出た回数」のズレを、カイ二乗値で測ります。
便利なカイ二乗検定にも、知っておきたい注意があります。
最後の点は、相関≠因果とまったく同じ注意です。カテゴリでも数値でも、「関係がある」と「原因と結果」は別もの。ここはいつも区別しましょう。
「期待度数って、どうやって出すの?」と思いますよね。考え方はシンプルです。「全体の割合が、各グループにもそのまま当てはまる」と仮定して計算します。
たとえば、全体で商品Aが好きな人が60%なら、「もし性別と無関係なら、男性でも女性でもAが好きな人は60%のはず」。男性100人なら期待は60人、女性50人なら期待は30人…という具合です。この“もし無関係なら”の数字と、実際の数字のズレを見るわけです。実際の計算はExcelやソフトがやってくれますが、「全体の割合を当てはめたのが期待度数」という発想だけ知っておけば十分です。
カイ二乗検定の解説で必ず出てくるのが自由度という言葉です。難しく考えず、「自由に決められるマスの数」とイメージしてください。
クロス集計表では、行と列の合計が決まっていると、いくつかのマスが決まれば残りは自動的に決まります。その“自由に動けるマスの数”が自由度です(2×2の表なら自由度は1)。カイ二乗値が「どれくらい大きければ有意か」の基準は、この自由度によって変わります。自由度は、表の大きさに応じて基準を調整するためのもの、と押さえておけばOKです。
カイ二乗検定が教えてくれるのは、あくまで「関係があるか・ないか」。その関係がどれくらい強いかまでは分かりません。
関係の強さを知りたいときは、クラメールのVという指標を使います。これは0〜1の値で、1に近いほど強い関係を表します。t検定の効果量と同じで、「有意かどうか(検定)」と「どれくらい強い関係か(クラメールのV)」を分けて見るのが、ていねいな分析です。データが大量だと、ごく弱い関係でも有意になりがちなので、この区別が効いてきます。
カイ二乗検定は、アンケートや調査の分析で大活躍します。
クロス集計表で表せる「カテゴリ × カテゴリ」の関係なら、どんな分野でも使えるのがカイ二乗検定の強みです。アンケート結果を“なんとなく”で語らず、根拠をもって「関係がありそう」と言えるようになります。
カイ二乗検定も、ExcelのCHISQ.TEST関数でできます。手順はこうです。
=CHISQ.TEST(観測の範囲, 期待の範囲) でp値が返る返ってきたp値が0.05未満なら、「カテゴリ同士に関係あり」と判断します。期待度数の計算が少し手間ですが、一度作ってしまえば使い回せます。アンケートをとったら、まずピボットでクロス集計し、この関数で関連を確かめる——という流れが定番です。手元にアンケート結果があるなら、ぜひ一度この手順を試してみてください。『なんとなく、男性はこちらが好きそう』という印象が、『統計的に、関係があると言える/言えない』という根拠のある言葉に変わります。それが、データを“語れる”ようになる、ということです。
カイ二乗検定は、カテゴリ(質的データ)同士の関係を調べる検定です。「もし関係がなければこうなるはず」という期待度数と、実際の観測度数のズレ(カイ二乗値)を測り、ズレが大きいほど「関係あり」と判断します。
性別と好み、地域とプランなど、クロス集計表で表せる関係の検証が得意。期待度数が小さいときの注意や、「関係≠因果」という点を押さえておけば、心強い道具になります。数値の平均はt検定、カテゴリの関係はカイ二乗、と覚えておきましょう。次回は、3つ以上のグループをまとめて比べる分散分析に進みます。
アンケートやクロス集計の結果を前に、「この偏りは、意味があるのか・たまたまなのか」と迷った経験はないでしょうか。カイ二乗検定は、まさにその迷いに答えをくれる道具です。数値の平均はt検定、カテゴリの関係はカイ二乗——この“データの種類による使い分け”を押さえておけば、手元のデータに合った検定を、自分で選べるようになります。
そして、ここでも忘れたくないのが「関係がある」と「原因と結果」は別、という視点です。カイ二乗検定が教えてくれるのは“関連の有無”まで。その先の「なぜ関連するのか」は、データの背景を考え、追加の調査で確かめていく——検定はゴールではなく、良い問いを立てるための出発点なのです。関係が見つかったら、そこから『なぜだろう?』を掘り下げていく。カイ二乗検定は、その探究の旅の最初の一歩を、しっかり踏み出させてくれる道具です。
カイ二乗検定=カテゴリ同士の関係(独立性)を調べる検定。
「関係がなければこうなるはず(期待)」と「実際(観測)」のズレを測る。
期待度数5未満は要注意。関係があっても因果とは限らない。
A. カテゴリ(質的データ)同士に関係があるかを調べる統計的検定です。よく使われる独立性の検定では、性別と好きな商品のように2つのカテゴリ変数が関係あるか(独立か)を、クロス集計表の数字から判断します。
A. 「もし2つのカテゴリに関係がなければ、表の数字はこうなるはず」という期待度数を計算し、実際の観測度数とのズレを測ります。ズレが大きいほどカイ二乗値が大きくなり、偶然ではなく関係があると判断します。
A. t検定は身長や点数などの数値(量的データ)の平均を比べるときに使います。カイ二乗検定は性別や好みなどのカテゴリ(質的データ)の関係を調べるときに使います。扱うデータの種類で選びます。
A. 独立性の検定は、2つのカテゴリ変数に関係があるかを調べます。適合度の検定は、観測データがある理論的な割合(サイコロの各目が1/6ずつなど)に合っているかを調べます。どちらも観測と期待のズレを測る点は同じです。
A. どこかのマスの期待度数が5未満だと結果が不正確になることがあり、その場合はフィッシャーの正確確率検定を使います。また、関係があるかは分かっても関係の強さや因果関係までは分からない点にも注意が必要です。
A. 言えません。相関と同じで、関係(関連)があっても、どちらが原因でどちらが結果かまでは分かりません。第3の要因が両方に影響している可能性もあるため、関係と因果は区別して考えます。
A. 観測されたデータが「関係がなければこうなるはず」という期待から大きくズレている、ということです。ズレが大きいほどp値は小さくなり、カテゴリ同士に関係があると判断しやすくなります。
※本記事は2026年6月時点の一般的な統計の考え方を初心者向けに整理したものです。検定の前提条件や厳密な手順は専門書もご確認ください。