
t検定とは?2グループの平均の差の調べ方をやさしく図解
ルミィ
AIの歩き方

「新しい広告にしたら、クリック率が少し上がった」——でも、それは本当に広告の効果でしょうか。それとも、たまたま(偶然)でしょうか。この「偶然か、意味のある差か」を見極めるのが、連載最終回の仮説検定です。
仮説検定と、その中心にあるp値は、統計の山場であり、いちばん誤解されやすいところでもあります。数式は使わず、考え方の“筋道”を図でていねいに追っていきましょう。
統計のきほんは、回帰分析やデータ分析を正しく使うための土台です。この連載を押さえておくと、回帰の結果も“なんとなく”ではなく“意味が分かって”読めるようになります。
📊 連載「統計のきほん」(全4回)
回帰分析やデータ分析の“土台”になる統計の基礎を、数式をできるだけ使わずに、図でやさしく整理する連載です。

『偶然でもこれくらいの差は出る?』を確率で考えるのが検定。p値は“偶然っぽさ”のものさしだよ。
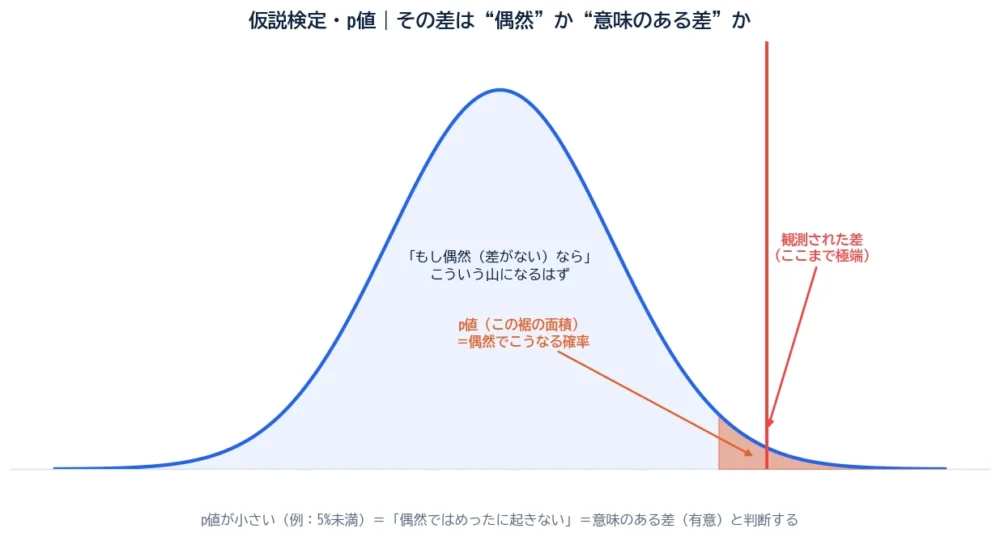
仮説検定は、観測されたデータの差(や効果)が、偶然では説明しにくいほど大きいかどうかを、確率で判断する方法です。
たとえば「Aパターンよりも、Bパターンのほうがクリック率が高かった」。この差が、偶然のブレの範囲なのか、それとも本物の差なのか——感覚ではなく、確率にもとづいて線引きする。それが仮説検定の役割です。ABテストや新薬の効果検証など、「効果があったと言ってよいか」を判断する場面で必ず登場します。
仮説検定は、少し回りくどい“背理法”のような筋道で進みます。まず、2つの仮説を立てます。
そして、いったん「差はない(帰無仮説)」と仮定します。そのうえで「もし本当に差がないなら、観測されたこの差は、どれくらい起こりにくいことなのか?」を計算するのです。「差がないと仮定したら、こんな極端な結果はめったに起きない」と分かれば、最初の仮定(差はない)のほうが間違っていた、と考える——これが検定の筋道です。
その「めったに起きない度」を表すのが、p値です。図を見てください。山は「もし偶然(差がない)なら、結果はこのあたりに散らばるはず」という分布。観測された差が、その山の端っこ(裾)にあるほど、「偶然では起きにくい」ことになります。
p値とは、「もし差がない(帰無仮説が正しい)と仮定したとき、観測された差と同じか、それ以上に極端な結果が出る確率」です。図のオレンジの裾の面積が、それにあたります。p値が小さいほど、「偶然でこうなったとは考えにくい」=差は本物っぽい、と判断します。
p値=「もし差がないと仮定したとき、観測された差以上に極端な結果が出る確率」。小さいほど“偶然では説明しにくい”。
では、p値がいくつなら「偶然じゃない」と判断していいのでしょう。その線引きの基準が、有意水準です。慣習的に5%(0.05)がよく使われます。
p値 < 5% なら「統計的に有意(意味のある差)」と判断し、「差がない」という帰無仮説を捨てます。「偶然なら20回に1回も起きないことが起きた。なら偶然じゃないだろう」という考え方です。より厳しく1%を使うこともあります。ただし5%という数字に絶対的な根拠はなく、あくまで“約束ごと”である点は覚えておきましょう。
検定にはいろいろな種類がありますが、いちばんよく出会うのがt検定です。
どれを使うかはデータの種類で変わりますが、「帰無仮説を立て、p値を計算し、有意水準と比べる」という筋道はすべて共通です。Excelやアプリがやってくれるのはp値の計算まで。その意味を読み解くのは、私たちの仕事です。
p値は、とても誤解されやすい指標です。代表的な勘違いを正しておきましょう。
最近は、p値だけに頼る危うさ(都合のいい結果が出るまで試す“p-hacking”など)も指摘されています。p値は便利な“ものさし”ですが、万能の判定機ではない——この距離感が大切です。
いちばん身近な仮説検定が、WebのABテストです。例で考えてみましょう。
Bのほうが3ポイント高い。でも、これは「Bが本当に優れている」のか、「たまたまBの回がよかった」だけなのか。ここで検定の出番です。「AとBに差はない」と仮定したら、これくらいの差(以上)が偶然で出る確率(p値)はどれくらい?を計算し、5%を切れば「Bは有意に良い」と判断します。感覚の「なんとなくBが良さそう」を、確率の裏づけに変えてくれるわけです。
検定は確率で判断するので、間違うこともあります。間違いには2種類あり、知っておくと判断を誤りません。
有意水準5%とは、「第一種の誤りを5%まで許す」という意味でもあります。この2つの誤りの関係は、AIの評価指標で出てきた「空振り(偽陽性)と見逃し(偽陰性)」とそっくり。どちらの間違いをより避けたいかで、基準の置き方が変わります。
検定の結果は、データの数(サンプルサイズ)に大きく左右されます。これも落とし穴です。
だから、検定の前に「どれくらいの差を、どれくらいの確実さで見つけたいか」を考えて、必要なデータ数を見積もるのが本来の作法です。「とりあえずデータが集まったから検定」ではなく、設計の段階から数を意識する——ここまで来れば、もう立派なデータ分析の使い手です。
仮説検定は、ともすると「p値が5%を切ったか/切らないか」の“合否判定”のように扱われがちです。でも、それだけでは少しもったいない使い方です。
p値は、「この差は偶然かもしれない」という疑いに、ひとつの答えを与えてくれる便利な道具です。でも、それは判断材料の“ひとつ”にすぎません。p値・効果の大きさ・背景の意味を合わせて、総合的に判断する——そこまでできて、はじめて検定を“使いこなしている”と言えます。
仮説検定は、観測された差が「偶然か、意味のある差か」を確率で見極める方法です。まず「差はない」と仮定し、その仮定のもとで観測された差が出る確率(p値)を計算。p値が有意水準(よく5%)より小さければ、「偶然では説明しにくい=意味のある差」と判断します。
これで連載「統計のきほん」は完結です。標準偏差(ばらつき)、正規分布(釣り鐘型)、相関(関係と因果)、そして仮説検定(偶然か否か)。この4つは、回帰分析やデータ分析を“意味が分かって”使うための、しっかりした土台になります。お疲れさまでした。
統計は、難しい数式の暗記ではありません。その芯にあるのは、『データのばらつきを測り、形をつかみ、関係を疑い、偶然と本物を見分ける』という、とても人間的な“考える作法”です。この連載で身につけた4つの視点は、AIやデータがあふれるこれからの時代に、情報を鵜呑みにせず自分の頭で判断するための、心強い武器になります。数字に強くなることは、だまされにくくなること。ぜひ、手元のデータで一つずつ試してみてください。
仮説検定=差が「偶然か意味あるか」を確率で判断。
p値=差がないと仮定したとき、その差以上に極端な結果が出る確率。小さいほど有意。
有意水準5%が目安。ただし「有意≠重要」「p値は差がない確率ではない」に注意。
A. 観測されたデータの差や効果が、偶然では説明しにくいほど大きいかどうかを、確率で判断する方法です。ABテストや新薬の効果検証など、「効果があったと言ってよいか」を感覚でなく確率で線引きするときに使います。
A. 「差はない(偶然だ)」という、つまらないほうの仮説です。仮説検定では、いったんこの帰無仮説が正しいと仮定し、そのもとで観測された差がどれくらい起こりにくいかを調べます。起こりにくければ、この仮定を捨てます。
A. 「もし差がない(帰無仮説が正しい)と仮定したとき、観測された差と同じか、それ以上に極端な結果が出る確率」です。p値が小さいほど、偶然でこうなったとは考えにくく、差が本物らしいと判断します。
A. p値がこれより小さければ「統計的に有意(意味のある差)」と判断する、という線引きの基準です。慣習的に5%(0.05)がよく使われ、「偶然なら20回に1回も起きないことが起きたなら、偶然ではないだろう」と考えます。
A. いいえ、それは誤解です。p値は「差がないと仮定したときに、この結果が出る確率」であって、「差がない確率」そのものではありません。主語が違う点が、p値のいちばん誤解されやすいところです。
A. 必ずしもそうではありません。データが大量にあると、実用上は無視できるほど小さな差でもp値は小さく(有意に)なります。有意かどうかと、差が実際に重要な大きさかどうかは、別々に考える必要があります。
A. 2つのグループの平均の差が、意味のある差かどうかを調べる代表的な検定です。たとえばAパターンとBパターンの平均クリック率の差などを調べます。帰無仮説を立て、p値を計算し、有意水準と比べる筋道は他の検定と共通です。
※本記事は2026年6月時点の一般的な統計の考え方を初心者向けに整理したものです。厳密な定義や検定の前提条件は専門書もご確認ください。
🧪 代表的な検定を、もっと詳しく:t検定・カイ二乗検定・分散分析・信頼区間の、それぞれの使い方と使い分けは、連載「統計的検定・推定の使い分け」(全4回)で図解しています。





