
SVM(サポートベクターマシン)とは?仕組みをやさしく図解
ルミィ
AIの歩き方

「新しいデザインAと旧デザインB、平均クリック率が少し違った。これは本物の差? それとも偶然?」——こうした2つのグループの“平均の差”を調べる、もっとも基本的な検定がt検定です。
ABテスト、薬の効果、施策の前後比較…2グループの平均を比べたい場面は山ほどあります。連載第1回として、このt検定の仕組みと使い方を、図でやさしく見ていきましょう。
この連載は、仮説検定・p値の“具体的な手法編”です。「帰無仮説・p値・有意水準」の考え方がまだの方は、先にそちらを読むとスッと入ってきます。
🧪 連載「統計的検定・推定の使い分け」(全4回)
「その差は偶然か、意味があるか」——代表的な検定(t検定・カイ二乗・分散分析)と、推定の区間(信頼区間)を、使い分けの視点で整理する連載です。

『差が大きいか』だけじゃダメ。『ばらつきに対して差が大きいか』を見るのがt検定。ここがキモだよ。
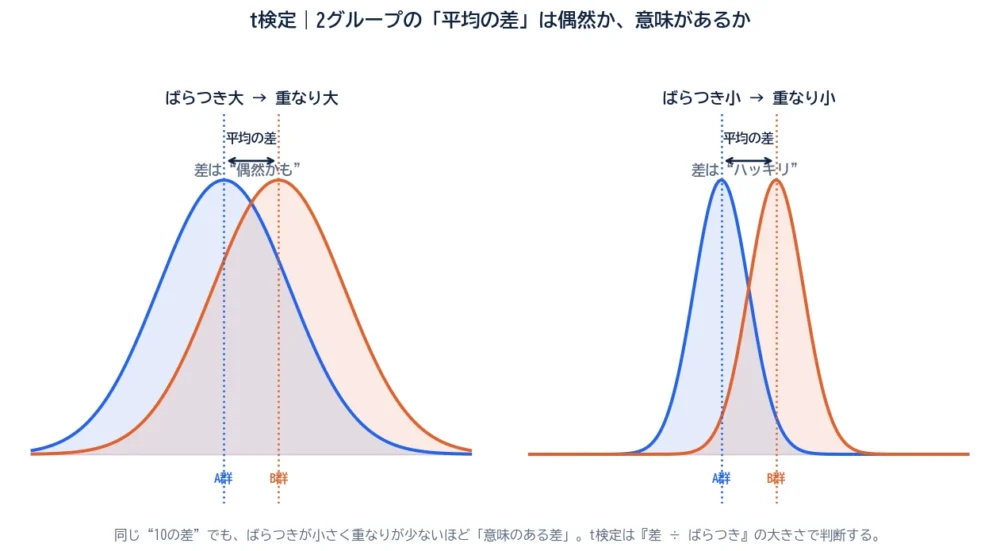
t検定は、2つのグループの「平均の差」が、偶然では説明しにくいほど大きいかどうかを調べる統計的検定です。
考え方の土台は仮説検定と同じ。まず「2グループに差はない(偶然だ)」という帰無仮説を立て、もしそうだとしたら、観測された差がどれくらい起こりにくいか(p値)を計算します。p値が小さければ「差は偶然ではない=有意」と判断します。
t検定のいちばん大事なポイントは、「平均の差の大きさ」だけでは判断しないことです。図を見てください。左右どちらも「平均の差」は同じ10ですが、印象がまるで違います。
つまり、同じ差でも、データのばらつきが小さいほど「意味のある差」だと言えます。t検定はこれを、「平均の差 ÷ ばらつき(標準誤差)」=t値という1つの数字で測ります。t値が大きいほど、ばらつきに対して差がはっきりしている、ということです。
t検定=2グループの平均の差を「差 ÷ ばらつき(t値)」で測る。同じ差でも、ばらつきが小さいほど“意味のある差”。
t検定には、データの取り方によって2種類があります。使い分けが大切です。
「別々の集団どうし」なら対応なし、「同じ人・同じ対象の前後(ペア)」なら対応あり。同じ平均の比較でも、データの構造が違うので、使う検定も変わります。
t検定の流れは、仮説検定の王道どおりです。
実際の計算は、Excel(T.TEST関数や分析ツール)や統計ソフトがやってくれます。私たちの仕事は、正しい種類を選び、出てきたp値の意味を読み解くことです。
t検定を使うには、いくつか前提があります。厳密には次のようなものです。
等分散が怪しいときは、それを仮定しないウェルチのt検定を使うのが安全で、最近はこちらを既定にすることも増えています。データが極端に歪んでいたり外れ値が多いときは、平均の比較自体が向かないこともあるので、前回までの“データの形を見る”作業が、ここでも効いてきます。
いちばん身近な例で考えてみましょう。Webサイトで広告AとBを出し分けた結果がこうだったとします。
Bのほうが3秒長い。でも、これは「Bが本当に優れている」のか、「たまたまBの回の人がよく見ただけ」なのか。t検定は、この3秒の差を、各グループの“滞在時間のばらつき”と人数を踏まえて評価します。ばらつきが小さく人数が多ければ、3秒でも「有意な差」と出ますし、ばらつきが大きければ「偶然の範囲」となります。感覚の「Bが良さそう」を、確率の裏づけに変えてくれるわけです。
ここで、t検定を使ううえでの大事な注意です。「有意」が出ても、それは「差がゼロではない」というだけで、差が“どれくらい大きいか”は別の話です。
特に、データの数がとても多いと、実用上はどうでもいいような小さな差でも「有意」になってしまいます。「統計的に有意」と「実際に意味のある大きさ」は別もの。そこで、差の大きさそのものを表す効果量(コーエンのdなど)もあわせて見るのが、かしこい使い方です。「有意か?(p値)」と「どれだけ大きい差か?(効果量)」——この2つをセットで見ましょう。
t検定は「データが正規分布に近い」ことを前提にしています。でも、データが極端に歪んでいたり、満足度の5段階のような順序データだったりすると、平均の比較自体が向きません。
そんなときは、値そのものではなく順位を使うノンパラメトリック検定(マン・ホイットニーのU検定など)を使います。分布を仮定しないので、外れ値や歪みに強いのが利点。データの種類と形を見て、t検定でいいのか、別の検定が要るのかを判断する——前回までの記述統計が、ここで効いてきます。
プロのデータ分析では、t検定の結果を「有意でした/有意ではありませんでした」だけで済ませません。次の3つをセットで報告するのが、ていねいな作法です。
p値だけだと「有意だが、ごくわずかな差」を見抜けません。効果量と信頼区間を添えることで、「意味があって、しかも実用的に十分な大きさの差なのか」まで伝わります。検定は“合否判定”ではなく、“差の姿をていねいに描く”もの——そう捉えると、ぐっと使いこなせるようになります。
t検定は、ExcelのT.TEST関数で手軽にできます。2つのグループのデータを2列に用意して、次のように書くだけです。
=T.TEST(配列1, 配列2, 尾部, 検定の種類)。引数の意味はこうです。
返ってくる値がp値です。これが0.05未満なら「有意な差あり」と判断します。より詳しく見たいときは、「データ」タブの「データ分析」アドインにある「t検定」を使うと、t値や各グループの平均・分散まで表で出してくれます。まずは2列のデータで、p値を出すところから試してみましょう。関数で一発、というのがExcelの強み。複雑な計算を電卓でする必要はありません。大事なのは、出てきたp値の意味を正しく読むこと——『偶然なら、この差はめったに出ない。だから意味がありそうだ』という、あの考え方を思い出してください。
t検定は、2つのグループの平均の差が偶然か意味のある差かを調べる、もっとも基本的な検定です。カギは「差の大きさ」だけでなく「ばらつきに対する差の大きさ(t値=差÷ばらつき)」を見ること。同じ差でも、ばらつきが小さいほど有意になりやすいのでした。
別々の集団なら対応なし、同じ対象の前後なら対応あり、と使い分けます。ABテストや効果検証の定番ツール。次回は、数値ではなく“カテゴリ”の関係を調べるカイ二乗検定に進みます。
そして、結果は「有意かどうか」だけで終わらせず、効果量や信頼区間もあわせて見る。『有意だが、ごくわずかな差』と『有意で、しかも大きな差』はまったく意味が違うからです。この“一歩深い読み方”ができると、検定は単なる合否判定ではなく、差の姿をていねいに描く道具になります。
t検定は、統計的検定の“入り口”です。ここで身につく『差の大きさだけでなく、ばらつきに対する差を見る』という発想は、このあとのカイ二乗検定も分散分析も、すべてに共通しています。手元に2グループのデータがあれば、ぜひExcelのT.TEST関数で一度試してみてください。『なんとなくAのほうが良さそう』を、『統計的に有意な差がある』と言えるようになる——その一歩が、データにもとづく意思決定の始まりです。統計が苦手だと思っていた人ほど、この『差 ÷ ばらつき』という素直な発想がストンと腑に落ちた瞬間、検定がぐっと身近に感じられるはずです。
t検定=2グループの平均の差の検定。t値=差÷ばらつき。
対応なし(別々の集団)/対応あり(同じ対象の前後)を使い分ける。
前提は正規性・等分散。等分散が怪しければウェルチのt検定。
A. 2つのグループの平均の差が、偶然では説明しにくいほど大きいかどうかを調べる統計的検定です。ABテストや薬の効果検証など、2グループの平均を比べたいときに使う、もっとも基本的な検定です。
A. 「平均の差 ÷ ばらつき(標準誤差)」で計算される値です。差の大きさだけでなく、ばらつきに対して差がどれだけ大きいかを表します。t値が大きいほど、その差は偶然では説明しにくくなります。
A. 対応のないt検定は、A店とB店の客のように別々のグループを比べます。対応のあるt検定は、同じ人のダイエット前後のように、同じ対象のペアを比べます。データの構造が違うため、正しい種類を選ぶ必要があります。
A. 「2グループに差はない」と仮定したときに、観測された差が偶然では起こりにくい(p値が有意水準5%などより小さい)、という意味です。つまり、その差は偶然ではなく意味のある差だと判断できる、ということです。
A. 2グループのばらつき(分散)が等しいと仮定しない、t検定の一種です。等分散の前提が怪しいときに安全で、近年はこれを既定として使うことも増えています。
A. データがおおむね正規分布に近いこと(正規性)と、2グループのばらつきが同程度であること(等分散)です。等分散が怪しいときはウェルチのt検定を使います。データが極端に歪んでいるときは平均の比較自体が向かないこともあります。
A. できます。T.TEST関数や「データ分析」アドインのt検定で計算できます。対応あり・なし、等分散かどうかを選ぶと、p値が求まります。出てきたp値を有意水準と比べて判断します。
※本記事は2026年6月時点の一般的な統計の考え方を初心者向けに整理したものです。検定の前提条件や厳密な手順は専門書もご確認ください。





