
決定木とは?仕組み・ジニ不純度・剪定までやさしく解説【機械学習入門】
ルミィ
AIの歩き方

前回のSVMは、境界線をかしこく引く手法でした。今回のk近傍法(kNN)は、うって変わって「いちばん直感的でシンプルな分類」。なんと、境界線すら引きません。
やることは、たったひとつ。「新しいデータの“ご近所”を見て、多数派と同じ仲間にする」だけ。転校生が、席の近い子たちのグループに自然となじむような——そんなイメージです。あまりにシンプルですが、ちゃんと役に立つ。その仕組みと“クセ”を見ていきましょう。
この連載は、機械学習の3つの学び方でいう「教師あり学習(分類)」の手法をあつかいます。決定木やロジスティック回帰を読んでいると、より分かりやすいです。
📘 連載「機械学習アルゴリズム図鑑」(手法編・全4回)
線形回帰や決定木に続く“定番の分類アルゴリズム”を、1つずつ図でやさしく整理する連載です。

『似た者は近くにいるはず』という素直な発想。むずかしい計算はナシ。だけど侮れないんだ。
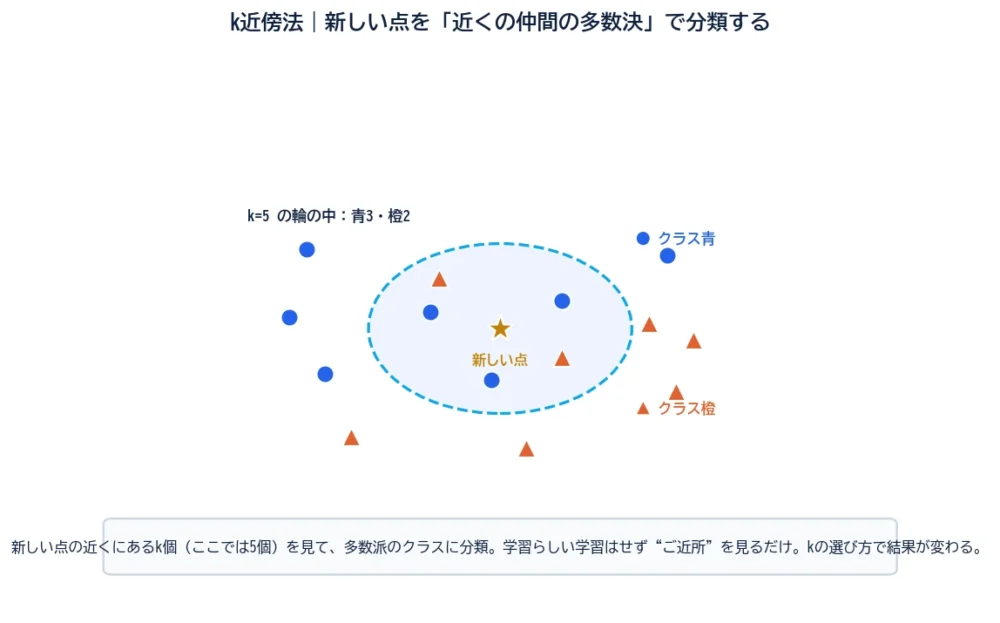
k近傍法(k-Nearest Neighbors、kNN)は、新しいデータを分類したいとき、その近くにある“k個”のデータを見て、多数派のクラスに分類する手法です。
図を見てください。真ん中の星(★)が、分類したい新しいデータです。その周りの近いデータをk個(図では5個)選び、内訳を数えます。青が3つ、橙が2つ。多数派は青なので、この新しいデータは「青クラス」と判定します。やっていることは、本当にこれだけです。
kNNの手順は、3ステップでまとめられます。
「近さ」は、ふつう2点間のまっすぐな距離(ユークリッド距離)で測ります。座標が近ければ似ている、という素直な考え方です。
kNNでいちばん大事なのが、「いくつのご近所を見るか(k)」の決め方です。これで結果が変わります。
ちなみに、2クラス分類ではkを奇数にするのがコツ。偶数だと「3対3」のように同点になり、多数決がつかないことがあるからです。
kNNには、もう一つ面白い特徴があります。事前の「学習」をほとんどしないのです。
ふつうの機械学習は、まずデータから一生けんめいモデル(境界線やルール)を作り、本番ではそれを使います。ところがkNNは、データをただ覚えておくだけ。そして新しいデータが来たそのときに、はじめてご近所を探して判定します。この“その場しのぎ”のやり方から、kNNは「怠惰学習(lazy learning)」と呼ばれます。
学習の手間がない代わりに、予測のたびに全データとの距離を計算するので、データが多いと予測が重くなる——これがkNNの大きなクセです。
kNUの得意・不得意を整理します。
| 内容 | |
|---|---|
| 長所① | 仕組みが単純で、理解も実装も簡単 |
| 長所② | 事前学習が不要。データを足せばすぐ反映される |
| 長所③ | 複雑な形の境界にも自然に対応できる |
| 短所① | データが多いと、予測のたびに計算が重い |
| 短所② | スケール(単位)の影響を受けるので標準化が必要 |
| 短所③ | 次元が多すぎると“近さ”が意味を失う(次元の呪い) |
「まずシンプルな手法で試したい」「データがそれほど多くない」ときに、kNNは手軽で頼れる選択肢です。
kNNは分類のイメージが強いですが、数値を予測する回帰にも使えます。やり方は同じで、近いk個の“数値の平均”をとるだけ。
たとえば「近所の似た家、5軒の価格の平均」で家賃を見積もる、といった具合です。線形回帰のように式を立てるのではなく、“ご近所の実例の平均”で予測する——これもkNNらしい、素直な発想です。
シンプルさゆえに、kNNはいろいろな場面で使われます。
イメージをつかむために、映画の好みでユーザーを分類してみましょう。「アクション好き度」と「恋愛もの好き度」の2つで、各ユーザーを地図上の点として置きます。
新しいユーザーがどちらのグループ(たとえば“アクション派”か“恋愛派”か)かを知りたいとき、kNNはその人の近くにいる既存ユーザーをk人見て、多い派閥に振り分けます。「あなたの趣味に近い人たちが恋愛派なら、あなたも恋愛派だろう」という、ごく自然な推測です。レコメンドが「あなたと似た人はこれも観ています」と勧めてくるのも、根っこは同じ発想です。
kNNは「近さ」がすべて。その測り方には、いくつか種類があります。
そして、kNNでいちばん注意すべきが“スケール(単位)”です。たとえば「年収(万円)」と「年齢(歳)」を一緒に使うと、数字の大きい年収ばかりが距離を支配し、年齢がほとんど効かなくなってしまいます。
これを防ぐのが標準化——各項目の大きさをそろえる前処理です。kNNを使うなら標準化はほぼ必須。同じく距離を使うクラスタリングでも、まったく同じ注意が必要でした。
ふつうのkNNは、k個の近所を“平等な1票”として多数決します。でも、「すぐ隣の点」と「ぎりぎりk番目の遠い点」を同じ1票にするのは、少しもったいない気もします。
そこで、近い点ほど票を重くするやり方(重み付きkNN)もあります。距離が近い仲間の意見を強く反映させることで、より自然な判定に近づけるわけです。シンプルなkNNにも、こうした改良の余地が残されています。
kNNの弱点として、特に有名なのが「次元の呪い」です。少し不思議な現象なので、押さえておきましょう。
特徴量(項目)の数が増えて“次元”が高くなると、どのデータどうしも、似たような距離に散らばってしまうのです。みんなが等しく遠くにいる状態では、「近い仲間」を選ぶこと自体に意味がなくなり、多数決が機能しません。kNNは「近さ」が命なので、この影響をもろに受けます。
対策は、本当に効く項目だけに絞ることや、主成分分析(PCA)などで次元を減らしてからkNNにかけること。「むやみに項目を増やさない」のが、kNNと付き合うコツです。
「近いものをまとめる」と聞くと、教師なし学習のクラスタリングを思い出すかもしれません。どちらも“近さ”を使いますが、目的はまったく違います。
kNNは正解ラベルがある教師あり学習で、「この新しい点はどのクラスか」を当てます。クラスタリングは正解のない教師なし学習で、「データ全体をいくつのグループに分けられるか」を探ります。正解を当てるのがkNN、グループそのものを見つけるのがクラスタリング——同じ“近さ”でも、向いている方向が逆なのです。名前が似た「k近傍法(kNN)」と「k平均法(クラスタリングのk-means)」を混同しやすいので、ここはしっかり区別しておきましょう。
k近傍法(kNN)は、新しいデータの“ご近所”をk個見て、多数派のクラスに分類する、いちばん直感的な手法です。境界線も引かず、事前学習もしない「怠惰学習」で、kの選び方が結果を左右します。
データが多いと予測が重い、次元が多いと近さが薄れる、といったクセはありますが、仕組みのわかりやすさは随一。「似た者は近くにいる」という素直な発想は、機械学習の入り口としても最適です。次回は、確率で見分けるナイーブベイズに進みます。
あらゆる機械学習の中で、kNNほど『仕組みを一言で説明できる』手法は珍しいでしょう。『近くの仲間の多数決』——たったこれだけです。だからこそ、機械学習を学び始めた人が最初に触れるのに最適ですし、複雑な手法の結果を『本当にこれで合っているのか?』と確かめる“ものさし”としても役立ちます。シンプルさは、それ自体が立派な武器なのです。次に分類問題に出会ったら、まずはkNNで肩慣らしをしてみてください。近くを見るだけ、という素朴さの中に、機械学習のエッセンス——「似たものは似た答えになる」という大前提——が、ぎゅっと詰まっています。
kNN=新しい点の近くk個を見て、多数決で分類する。
事前学習しない『怠惰学習』。kの選び方(奇数が無難)が肝。
シンプルだが、データが多いと予測が重い。回帰にも使える。
A. 新しいデータを分類するとき、その近くにあるk個のデータを見て、多数派のクラスに分類する手法です。境界線を引かず、近くの仲間の多数決で決める、いちばん直感的な分類アルゴリズムです。
A. kは「いくつのご近所を見るか」の数です。小さすぎるとノイズに振り回され、大きすぎると境界がぼやけます。データ量に応じていくつか試して決め、2クラス分類では同点を避けるため奇数にするのが定番です。
A. ふつうは2点間のまっすぐな距離(ユークリッド距離)で測ります。座標が近ければ似ているとみなします。単位の大きい特徴量に引っ張られないよう、事前にスケールをそろえる標準化が重要です。
A. kNNのように、事前にモデルを作らず、データをただ覚えておくだけの学習方法です。新しいデータが来たそのときに、はじめてご近所を探して判定します。学習は楽ですが、予測のたびに計算が必要になります。
A. データが多いと予測のたびに全データとの距離を計算するため重くなること、特徴量のスケールに影響されること、次元が多すぎると“近さ”が意味を失う(次元の呪い)ことです。標準化や次元削減で対処します。
A. 使えます。分類では多数決をしますが、回帰では近いk個の数値の平均をとって予測します。たとえば近所の似た家の価格の平均で家賃を見積もる、といった使い方ができます。
A. 好みの近いユーザーの行動を使うレコメンド、浮いた点を見つける異常検知、似た画像を探す画像認識などに使われます。シンプルなので、最初に試して基準を作るベースラインとしてもよく使われます。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わります。





