
Excelでできる!重回帰分析の使い方【2026年最新版・初心者向け】
ルミィ
AIの歩き方

決定木、ロジスティック回帰に並ぶ“分類の定番”が、今回のSVM(サポートベクターマシン)です。少し前まで、画像認識や文字認識の主役を務めていた実力者でもあります。
SVMの考え方は、ひとことで言うと「2つのグループの間に、いちばん広い“余白”をあけて境界線を引く」こと。なぜ余白が広いと良いのか、直線で分けられないデータはどうするのか——その賢いアイデアを、図でやさしく見ていきましょう。
この連載は、機械学習の3つの学び方でいう「教師あり学習(分類)」の手法をあつかいます。決定木やロジスティック回帰を読んでいると、より分かりやすいです。
📘 連載「機械学習アルゴリズム図鑑」(手法編・全4回)
線形回帰や決定木に続く“定番の分類アルゴリズム”を、1つずつ図でやさしく整理する連載です。

ただ2つに分けるだけじゃなく、“いちばん余裕をもって分ける”のがSVM。この『余白』がキモだよ。
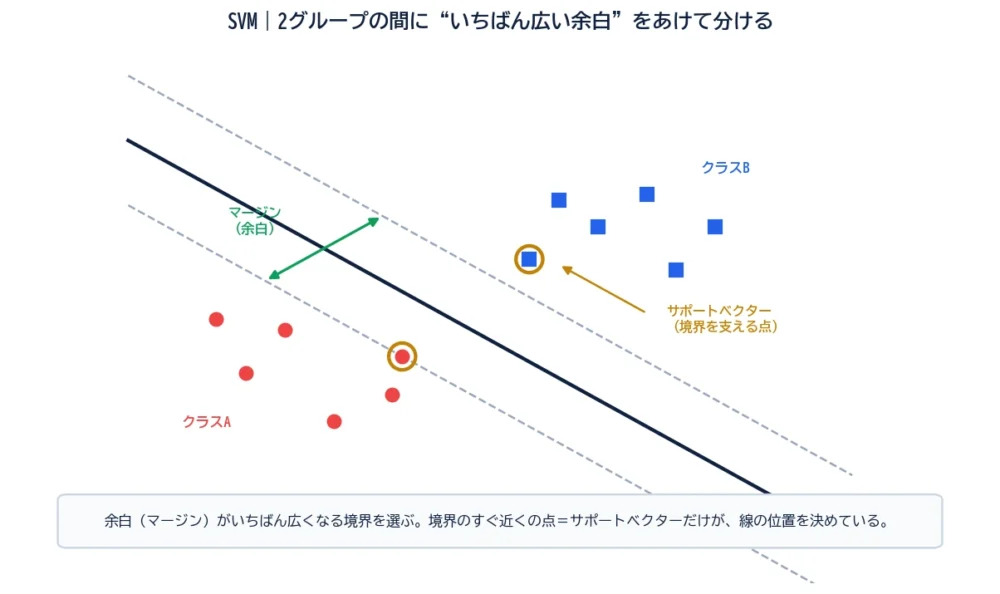
SVM(Support Vector Machine)は、データを2つのグループに分ける境界線を引く分類手法です。ここまでは決定木やロジスティック回帰と同じですが、SVMには独特のこだわりがあります。
それは、境界線の引き方。2つのグループを分ける線は、実は何本でも引けます。SVMはその中から、「両側のいちばん近いデータとの距離(余白)が、最大になる線」を選びます。図のように、境界の両側にできる“通り道”がいちばん広くなる線、というわけです。
この余白のことをマージンと呼びます。SVMは「マージンを最大化する」手法、とよく説明されます。では、なぜ余白は広いほうがいいのでしょうか。
理由は、新しいデータに強くなる(汎化しやすい)からです。境界がどちらかのグループにギリギリ寄っていると、少しデータがズレただけで間違えてしまいます。でも、両側にたっぷり余白をとっておけば、多少のズレやノイズがあっても、正しく分類できる可能性が高まります。「余裕をもって分ける」ことが、本番での安定につながるのです。
SVMは、ただ分けるのではなく「両側に最大の余白(マージン)をとって分ける」。余白が広いほど、新しいデータにも強くなる。
SVMという名前の由来が、このサポートベクターです。図で、境界線のすぐ近く(余白のふち)にある点に注目してください。これらがサポートベクターです。
面白いのは、境界線の位置を決めているのは、このサポートベクターだけだということ。遠く離れた大多数の点は、境界の位置に影響しません。「ギリギリのところにいる少数の点」が、境界を“支えて”いるのです。だから、関係ない点をたくさん足しても境界は変わらず、計算上も効率的、という利点があります。
「でも、まっすぐな線では分けられないデータも多いのでは?」——その通りです。そこでSVMが使う魔法のような工夫がカーネルトリックです。
アイデアはこうです。データをいったん“高い次元”に持ち上げると、まっすぐな面で分けられるようになることがあります。たとえば、平面上では円状に入り混じっていて直線で分けられない点も、うまく立体に持ち上げれば、1枚の平らな板でスパッと分けられる——そんなイメージです。
カーネルトリックは、この“持ち上げ”を、実際に高次元の計算をせずに済ませる賢い近道です。おかげでSVMは、曲がりくねった複雑な境界も扱えるようになります。これがSVMを強力にした立役者でした。
SVMの得意・不得意を整理しておきましょう。
| 内容 | |
|---|---|
| 長所① | 余白を最大化するので、新しいデータに強い(汎化しやすい) |
| 長所② | カーネルで複雑な境界も扱える |
| 長所③ | データが少なめ・次元が高い場面でも比較的強い |
| 短所① | データ量がとても多いと、計算が重くなりやすい |
| 短所② | 結果の理由が直感的に説明しづらい |
| 短所③ | スケール(単位)の影響を受けるので、事前の標準化が必要 |
「中規模までのデータで、きっちり高精度に分けたい」場面で、SVMは長く頼られてきました。
SVMは、機械学習の現場で幅広く活躍してきました。
同じ分類でも、それぞれ持ち味が違います。ロジスティック回帰は「確率で答えが欲しい・理由を説明したい」とき、決定木は「ルールを目で見て理解したい」とき。
SVMは、その中間で「とにかく境界をきっちり引いて高精度に分けたい」ときに光ります。とはいえ近年は、表形式データなら勾配ブースティング(XGBoostなど)、画像ならディープラーニングに主役を譲った場面も多いです。それでも「マージン最大化」という美しい考え方は、機械学習を学ぶうえで一度は知っておきたい基礎教養です。
ここまでは「2つのグループがきれいに分かれている」前提で話してきました。でも現実のデータは、たいてい少し混ざり合っていて、1本の線では完全に分けきれません。
そこでSVMは、「少しの間違い(はみ出し)は許す」という柔軟さを持っています。これをソフトマージンと呼びます。数個の点が境界をはみ出しても、全体として余白が広く、うまく分けられる線を選ぶ——完璧を求めずに、大局でいちばんよい境界をとるわけです。
どれくらいはみ出しを許すかは、Cという調整つまみで決めます。Cを小さくすると「余白を広くとる代わりに、はみ出しに寛容」、大きくすると「はみ出しを厳しく罰する代わりに、余白は狭め」になります。これは、ちょうど過学習とのバランス調整そのもの。厳しくしすぎると訓練データには完璧でも、新しいデータで失敗しやすくなります。
SVMのイメージは、2つの村の間に“いちばん広い道路”を通すことにたとえられます。道幅(マージン)を最大にしておけば、多少車がふらついても、隣の村の畑に突っ込むことはありません。これが「余裕をもって分ける」ということです。
そして、その道幅を決めているのは、道のすぐ脇に建つ数軒の家(サポートベクター)だけ。村の奥にある家がいくら増えても、道の引き方は変わりません。「境界の近くの少数だけが効く」というSVMの性質が、このたとえで直感的に分かるはずです。
2000年代、SVMは機械学習の花形でした。いまは、表形式データなら勾配ブースティング、画像や言語ならディープラーニングが主役になり、出番は以前より減っています。
それでも、データが少なく次元が高い場面ではいまも有力ですし、何より「マージンを最大化する」という考え方の美しさは色あせません。SVMを理解しておくことは、機械学習の“考え方の引き出し”を豊かにしてくれます。
実際にSVMを使う場面を見すえて、つまずきやすいポイントを3つ挙げておきます。
どれも「データの大きさをそろえ、複雑さをほどよく保つ」という、機械学習に共通の作法です。SVMだからと身構える必要はありません。
SVM(サポートベクターマシン)は、2つのグループの間に“いちばん広い余白(マージン)”をあけて境界を引く分類手法です。余白を最大化することで新しいデータに強くなり、境界を支えるのは少数のサポートベクターだけ。カーネルトリックを使えば、曲がった複雑な境界も扱えます。
ディープラーニング登場前は画像・文字認識の主役を務めた実力者で、いまも中規模データの高精度な分類で頼られています。「余裕をもって分ける」という発想は、機械学習の大切な基礎の一つ。次回は、もっと直感的な分類手法——k近傍法に進みます。
選択肢が多いと、つい「いちばん新しくて強い手法」に飛びつきたくなります。でもSVMのように、シンプルで筋の通った古典を知っておくことには、別の価値があります。データが少ないとき、とにかくきっちり分けたいとき——状況に応じて引き出しから取り出せる手法が多いほど、あなたの分析は柔軟になります。SVMは、その引き出しに必ず入れておきたい一本です。
SVM=いちばん広い余白(マージン)で分ける分類手法。
境界を決めるのは少数のサポートベクターだけ。
カーネルトリックで曲がった境界も扱える。中規模データの高精度分類に強い。
A. データを2つのグループに分ける際、両側のいちばん近いデータとの余白(マージン)が最大になる境界線を引く分類手法です。余白を最大にすることで、新しいデータにも強い(汎化しやすい)分類ができます。
A. 境界線とその両側のいちばん近いデータとの距離(余白=マージン)を、できるだけ広くとることです。余白が広いほど、データが多少ズレても正しく分類でき、本番の新しいデータに強くなるため重要です。
A. 境界線のすぐ近く(余白のふち)にある少数のデータ点のことです。SVMでは、この点だけが境界線の位置を決めており、遠く離れた多数の点は境界に影響しません。名前の由来にもなっています。
A. 直線では分けられないデータを、いったん高い次元に持ち上げることで、まっすぐな面で分けられるようにする工夫です。実際に高次元の計算をせずに済ませる賢い近道で、これによりSVMは曲がった複雑な境界も扱えます。
A. 長所は、余白最大化で新しいデータに強いこと、カーネルで複雑な境界も扱えること、次元が高いデータにも比較的強いことです。短所は、データ量が非常に多いと計算が重いこと、結果の理由を説明しづらいこと、事前の標準化が必要なことです。
A. 手書き文字認識や画像分類、スパム判定などのテキスト分類、遺伝子データの分類、異常検知などに使われてきました。ディープラーニング登場前は、画像・文字認識の主役級の手法でした。
A. ロジスティック回帰は確率や理由が欲しいとき、決定木はルールを目で見て理解したいとき、SVMは境界をきっちり引いて高精度に分けたいときに向きます。目的やデータの性質に応じて選びます。
※本記事は2026年6月時点の一般的な仕組みを初心者向けに整理したものです。手法の詳細や最適な使い方はデータや目的によって変わります。





