Google AI Studioとは?プロンプトからアプリを作る使い方とAntigravity連携を整理
ルミィ
AIの歩き方

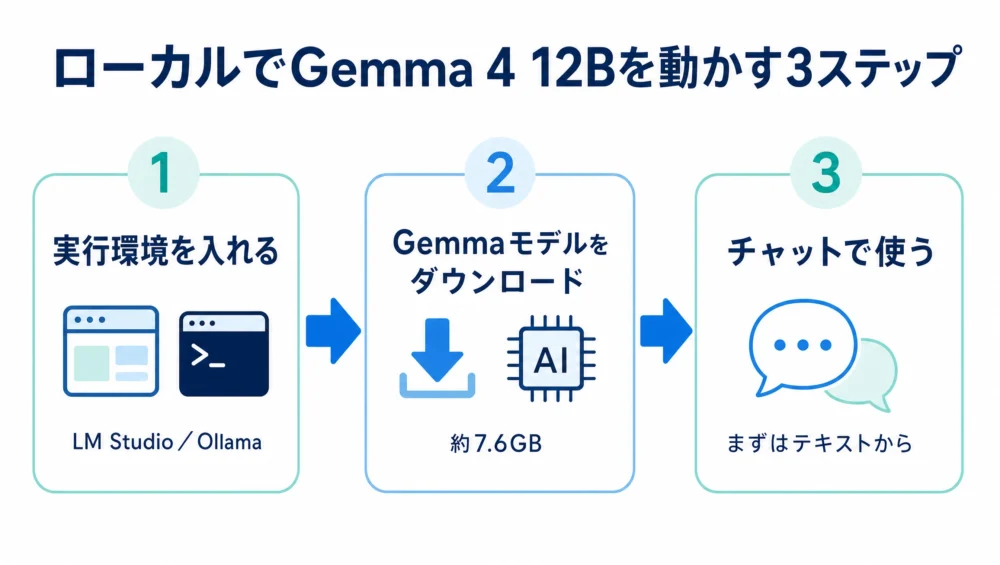
前回の記事では、Gemma 4 12BがGeminiの新機能ではなく、自分のPCで動かせるオープンAIモデルだと紹介しました。では、実際にGemma 4 12Bを使うには、何を入れればいいのでしょうか。
ChatGPTやGeminiのようにブラウザを開けばすぐ使えるタイプではなく、ローカルPCで動かすには、OllamaやLM Studioのような「実行環境」が必要です。
この記事では、Gemma 4 12Bを試す前に知っておきたい、OllamaとLM Studioの違い・必要メモリ・Mac/Windowsでの考え方・初心者がつまずきやすいポイントを、やさしく整理します。
📍 まだ「Gemma 4 12Bって何?」という方は、先に Gemma 4 12Bとは?Geminiとの違い・できること・ローカルAIの使い道 を読むとスムーズです。
結論から先に。 まず体験したいなら画面操作のLM Studio、コマンド操作や自動化まで考えるならOllama。どちらもGemma 4 12Bを動かせます。必要メモリは16GB前後が目安(モデルのダウンロードは約7.6GB)。まずはテキスト入力から小さく試すのが安全です。

「動かすAI」は最初だけちょっと準備がいるよ。でも一度入れちゃえば、あとはチャットするだけ。まずはLM Studioが分かりやすい!
大前提として、Gemma 4 12Bは「サイトを開いてログインすれば使える」タイプではありません。モデル本体(データ)を自分のPCに入れて、それを動かすソフトが必要になります。
イメージは、「実行環境(アプリ)を入れて、その中にGemma 4 12Bというモデルを読み込む」感じ。その実行環境の代表が、OllamaとLM Studioです。
ローカルAIとは、クラウド(ネット上のサーバー)ではなく、自分のPCの中でAIを動かすことです。メリットとデメリットを整理します。
「手元で完結する安心感」がローカルAIの魅力。そのかわり、準備とPCパワーは自分持ちだよ。
Ollamaは、ローカルでAIモデルを動かすための定番ツールです。コマンド(黒い画面に文字を打つ操作)が中心で、次のように打つだけでモデルを取得して動かせます。
ollama run gemma4:12b開発や自動化まで視野に入れている人に向いています。
LM Studioは、画面操作でローカルAIを動かせるデスクトップアプリです。アプリ内でモデルを検索してダウンロードし、チャット画面でそのまま会話できます。
Mac・Windows・Linuxに対応していて、「まずは触ってみたい」という初心者に向いています。
コマンドがちょっと怖い…という人はLM Studioから。ボタンとチャットだけで動かせるよ。
2つの違いを表にまとめます。どちらが優れているというより、「何をしたいか」で選ぶのがコツです。
| 項目 | LM Studio | Ollama |
|---|---|---|
| 操作方法 | アプリ画面中心 | コマンド中心 |
| 初心者向け | ◎ | ○ |
| モデル検索 | アプリ内で探しやすい | コマンド・モデルページから指定 |
| 開発連携 | ローカルサーバー機能あり | API連携しやすい |
| 向いている人 | まず触ってみたい人 | 開発・自動化したい人 |
| Gemma 4 12Bとの相性 | ◎ | ◎ |
まず体験したい人はLM Studio。コマンド操作や自動化まで考える人はOllama。 どちらもGemma 4 12Bを試す入口になります。
迷ったら、LM Studioから始めるのがおすすめです。画面操作だけで「モデルを入れる→チャットする」が完結するので、つまずきにくいからです。
コマンドに抵抗がない、または将来的に自動化・開発で使いたいなら、最初からOllamaでもOK。両方を入れて使い分けても問題ありません。
初心者がGemma 4 12Bを試すなら、いきなり細かい設定を触るより、まずは「モデルを入れて、短い文章で返事が返ってくるか」を確認するのがおすすめです。
画面操作だけで進められるので、初めてローカルAIを触る人はLM Studioから始めると分かりやすいです。
📍 LM Studioの具体的な手順(インストール〜チャット)は、専用記事で解説しました。→ LM Studioとは?Gemma 4 12BをローカルPCで動かす手順を初心者向けに解説
Ollamaを使う場合は、ターミナルで次のように入力します。
ollama run gemma4:12bコマンド操作に抵抗がない人や、あとで別アプリ・自動化・開発ツールから呼び出したい人はOllamaが向いています。
📍 Ollamaの具体的な手順は、専用記事で解説しました。→ Ollamaとは?Gemma 4 12Bをコマンドでローカル実行する手順を初心者向けに解説
12B(120億パラメータ)サイズのモデルなので、ある程度のメモリが必要です。目安を表にします。
| 項目 | 目安 |
|---|---|
| ダウンロードサイズ | 約7.6GB(Ollama版 gemma4:12b の場合) |
| 快適に動かすメモリ/VRAM | 16GB前後が目安 |
| 最低ライン | 8GBは厳しめ。より小さい量子化版を選ぶ前提に |
| コンテキスト長 | 最大256Kトークン |
ポイントは、メモリ(RAM)またはGPUのVRAMに「モデルが乗るか」。量子化(軽量化)されたモデルを選ぶと、必要メモリを下げられます。量子化の意味とQ4・Q5・Q8の選び方は量子化モデルとは?で詳しく解説しています。
⚠ 同じGemmaでも、サイズ違い(より小さいモデル)や量子化の度合いによって必要スペックは変わります。お使いのPCに合わせて、まずは軽いモデルから試すのが安全です。
環境によって、動かしやすさや速さが変わります。ざっくりの考え方はこうです。
どの環境でも、「メモリ/VRAMに余裕があるほど快適」という原則は同じです。
ローカルで動かせたら、まずはこのあたりから試すと手応えを感じやすいです。
いきなり重い使い方をせず、短いテキストで「ちゃんと返ってくる」ことを確認するのがコツです。
ここは少していねいに。Gemma 4 12Bの「モデルとしての対応」と、「OllamaやLM Studioで実際に使えること」は、分けて考えると安全です。
Gemma 4 12B自体は音声入力にも対応するモデルですが、OllamaやLM Studioでどこまで使えるかは、配布形式・実行環境・アプリ側の対応状況によって変わります。まずはテキスト入力、余裕があれば画像入力から試すのが安全です。
「公式モデルができること」と「いま手元のツールでできること」は別もの。慎重に確認するほど、ガッカリが減るよ。
Gemma 4 12BをローカルPCで使うには、OllamaかLM Studioのような実行環境が必要です。まず体験したいならLM Studio、自動化・開発まで考えるならOllama。必要メモリは16GB前後が目安(ダウンロードは約7.6GB)。
そして、「モデルとしての対応」と「ツールで実際に使える範囲」は分けて考えるのが安全です。まずはテキストから小さく試して、自分のPCと用途に合うかを確かめてみてください。
最初の1回さえ動かせれば、ローカルAIはぐっと身近になるよ。まずはLM StudioでGemmaを動かしてみよう!
A. モデル自体は無料で公開されています(Apache 2.0ライセンスで商用利用も可能)。ただし、動かすにはPCの性能(目安として16GB級のメモリ/VRAM)や電気代が必要です。
A. 12B版は8GBだと厳しめです。動かすなら、より小さいサイズや、強めに量子化された軽量版を選ぶ前提になります。快適さを求めるなら16GB前後が目安です。
A. 使えます。Apple Silicon(M系)はユニファイドメモリを活かしやすく、LM StudioのMLX形式などが快適なこともあります。メモリは16GB以上が安心です。
A. 初心者にはLM Studioが簡単です。画面操作だけで、モデルの取得からチャットまで完結します。コマンドや自動化に慣れているなら、Ollamaも手軽です。
A. Gemma 4 12B自体は音声入力にも対応するモデルです。ただし、OllamaやLM Studioで音声入力まで使えるかは、配布形式やアプリ側の対応状況によって変わります。まずはテキスト入力、次に画像入力から試すのが安全です。
A. 用途しだいです。手軽さや最大級の賢さは、クラウドのChatGPT・Geminiが有利。プライバシーやオフライン、料金を抑えた実験は、ローカルのGemmaが向きます。置き換えというより、使い分けがおすすめです。
※本記事は、公開情報(2026年6月時点)をもとに初心者向けに整理しています。仕様や対応状況は今後変わる場合があります。参考にした主な公式情報:Google公式ブログ/Gemma 4 モデルカード/Ollama(gemma4)/LM Studio連携ガイド。最新情報は各公式でご確認ください。






