Qwen3.5 9Bと27BをRTX 4070 Ti 12GBで実機比較|精度・速度・VRAMの差
ルミィ
AIの歩き方

前回の記事では、LM Studioを使って画面操作でGemma 4 12Bを動かす方法を紹介しました。この記事では、もう一つの定番ツール**Ollama**を使って、コマンドでローカル実行する手順を整理します。
Ollamaは「黒い画面(ターミナル)にコマンドを打つ」スタイルです。最初は少し身構えるかもしれませんが、実は覚えるコマンドはごくわずか。自動化や開発に広げやすいのが強みです。
📍 そもそも「Gemma 4 12Bって何?」という方は Gemma 4 12Bとは?、画面操作で試したい方は LM Studioの手順記事 がおすすめです。
結論から先に。 Ollamaは、コマンドでローカルAIを動かす無料の定番ツール。ollama run gemma4:12b という1行で、モデルの取得から実行まで進みます。必要メモリは16GB前後が目安(ダウンロードは約7.6GB)。画面操作が好みならLM Studio、コマンド・自動化が好みならOllamaです。

コマンドって聞くと身構えるけど、Ollamaは覚えることが少ないよ。まずは1行打ってみよう!
Ollamaは、ローカルでAIモデルを動かすための無料ツールです。コマンド操作が中心で、モデルの取得・実行・管理を、シンプルなコマンドで行えます。Mac・Windows・Linuxに対応しています。
内部でモデルを効率よく動かしてくれるので、ollama run モデル名 と打つだけで、ダウンロードから対話の開始まで一気に進みます。コマンドに慣れている人や、あとで自動化・開発につなげたい人に向いています。
LM Studioが「画面で操作するアプリ」なら、Ollamaは「コマンドで動かす道具」。中身(ローカルでGemmaを動かす)は同じだよ。
ollama run)ollama list など)「1行で動かせる手軽さ」と「APIで開発に組み込める柔軟さ」の両立が、Ollamaの魅力です。
Gemma 4 12Bは12B(120億パラメータ)の大きめのモデルです。動かす前に、PCのメモリを確認しておきましょう。
| 項目 | 目安 |
|---|---|
| ダウンロードサイズ | 約7.6GB(gemma4:12b の目安) |
| 快適に動かすメモリ/VRAM | 16GB前後が目安 |
| 最低ライン | 8GBは厳しめ。小さめ・量子化版を選ぶ前提に |
| コンテキスト長 | 最大256Kトークン |
なお、16GBはあくまで目安です。GPUの有無、Macのユニファイドメモリ、Windowsの空きメモリ状況によって、体感の速さは変わります。
⚠ 重いと感じたら、より小さいモデルや、強めに量子化されたモデルを選ぶと軽くなります。まずは無理のないサイズから試すのが安全です。
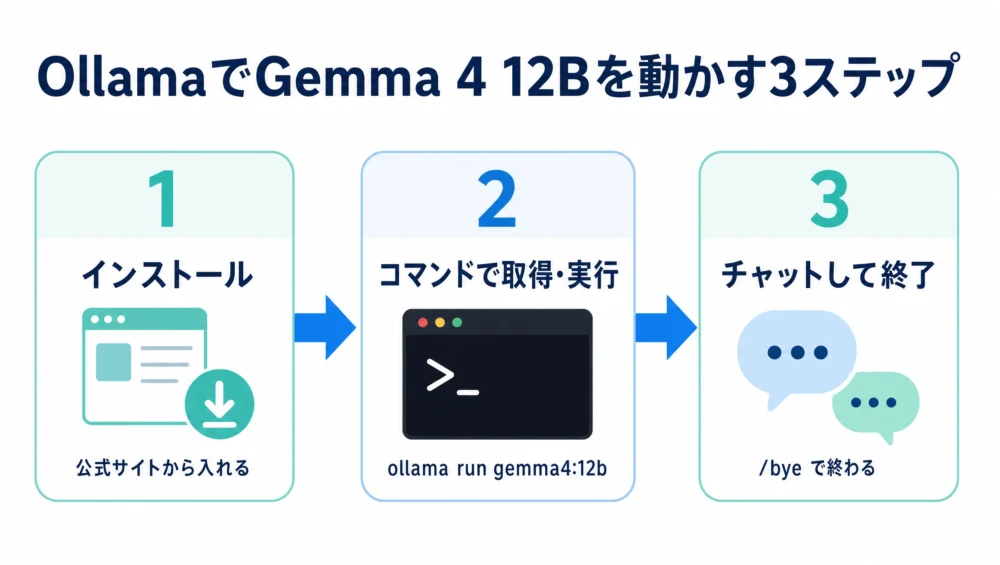
まずはOllamaをインストールします。手順はシンプルです。
ターミナルが開ければ準備完了です。次は、いよいよGemma 4 12Bを動かします。
Ollamaの便利なところは、モデルの取得と実行が1行でできること。ターミナルに次のコマンドを入力します。
ollama run gemma4:12b初回はモデル(約7.6GB)のダウンロードが始まり、終わると自動でチャットが始まります。2回目以降は、ダウンロード不要ですぐに起動します。
💡 先にダウンロードだけ済ませておきたいときは、ollama pull gemma4:12b を使います。あとから ollama run gemma4:12b で即起動できます。
プロンプト(入力待ちの記号)が表示されたら、そのまま日本語で話しかけられます。
/bye と入力する(または Ctrl + D)最初は短い質問でOK。ちゃんと返ってくれば、自分のPCの中でGemmaが動いている証拠です。
最初の返事が返ってきたら成功!終わるときは /bye でOK。次に使うときは run をもう一回打つだけだよ。
Ollamaで覚えておくと便利なコマンドはこのくらい。まずは run と /bye の2つだけでも十分です。
| コマンド | 意味 |
|---|---|
| ollama run gemma4:12b | モデルを実行(なければ取得してから実行) |
| ollama pull gemma4:12b | モデルをダウンロードだけしておく |
| ollama list | 取得済みモデルの一覧を表示 |
| ollama rm gemma4:12b | モデルを削除して容量を空ける |
| /bye | チャットを終了する |
容量が気になってきたら、使わないモデルを ollama rm で消すと空きを作れます。
日本語の安定性を確かめるなら、こんな短いプロンプトから試すと分かりやすいです。
コツは、短く・具体的に指示すること。長文や複雑な指示は、モデルやスペックによって崩れやすいので、まずは軽いものから試しましょう。
「コマンドが効かない」「遅い」「落ちる」ときは、ここを順に確認します。
| 症状 | 確認・対処 |
|---|---|
| コマンドが見つからない | インストール後にターミナルを開き直す。OSを再起動して再確認 |
| ダウンロードが遅い・止まる | 回線を確認し、時間をおいて再実行する |
| 重い・遅い | モデルが大きすぎるかも。小さめ・量子化版に変える |
| メモリ不足で落ちる | より小さいモデルへ下げる |
| 日本語が不自然 | モデルや量子化の影響。別のモデル/サイズを試す |
基本は「重い・不安定なら、まず小さいモデルに下げる」。これでたいていは安定します。
コマンド派のOllamaは、片付けもコマンドで一瞬です。モデルが増えてストレージが気になってきたら、この2つを覚えておけば困りません。
ollama list # 入っているモデルとサイズの一覧
ollama rm モデル名 # 使わないモデルを削除削除してもまたpullすれば戻せるので、「3週間使っていないモデルは消す」くらいの気軽さで大丈夫です。1つ数GB〜十数GBあるので、2〜3個消すだけでかなりの空きが生まれます。
モデルが新しいバージョンに置き換わったときは、同じモデル名でもう一度ollama pullを実行するだけです。差分が取得されて最新になります。アプリと違って自動更新はされないので、「ニュースで新版を見かけたらpull」くらいの感覚で十分です。
Ollamaがコマンド派に愛される本当の理由は、チャットだけでなく他のプログラムからAIを呼び出す窓口(ローカルAPI)になることです。Ollamaが起動していれば、自作のスクリプトやツールから「この文章を要約して」とプログラム的に依頼できます。
ここまで来ると、ローカルAIは「チャット相手」から「自分の道具箱の部品」に変わります。いますぐ使わなくても、「Ollamaは将来そういうこともできる」と知っておくと、ツール選びの視界が広がるはずです。
実際、当サイトで紹介している自動化やアプリ開発の文脈でも、ローカルAIの呼び出し口としてOllamaは定番の位置にあります。「画面で楽しむならLM Studio、組み込んで働かせるならOllama」——2つの違いは、突き詰めるとこの一文に行き着きます。
画面操作のLM Studioと、コマンドのOllama。目的はどちらも「ローカルでGemmaを動かすこと」ですが、操作スタイルや使うモデル形式、開発連携のしやすさが違います。
| 項目 | LM Studio | Ollama |
|---|---|---|
| 操作方法 | アプリ画面中心 | コマンド中心 |
| 初心者の入りやすさ | ◎ | ○ |
| 自動化・開発 | ○ | ◎ |
画面操作で試したい人は LM StudioでGemma 4 12Bを動かす手順 へ。OllamaとLM Studioの違い・必要メモリの全体像は Gemma 4 12BをローカルPCで使うには? にまとめています。
Ollamaは、コマンドでローカルAIを動かす定番ツールです。ollama run gemma4:12b の1行で、モデルの取得から実行まで進みます。覚えるコマンドは少なく、自動化や開発に広げやすいのが強みです。
まずは短い文章で返答速度と日本語の安定性を確認し、重い場合は小さめのモデルや量子化版から。画面操作が好みならLM Studio、コマンド・自動化が好みならOllama、と使い分けましょう。コマンド1行から始まる世界は、想像よりずっと広い。まずは今日、ターミナルに1行打つところから——それがローカルAI活用の2つ目の扉です。
これでローカルAIの2つの入口(LM StudioとOllama)を両方知ったね。あとは好みで選んでOK!
A. はい、無料で使えます。モデルも多くは無料で入手できます。ただし、動かすにはPCの性能が必要で、Gemma 4 12Bなら16GB級のメモリが目安です。なお、モデルごとにライセンスや商用利用の条件が異なる場合があるため、仕事で使う場合はモデル配布元の利用条件も確認しておきましょう。
A. 覚えるのは、実行する「ollama run」と終了する「/bye」くらいです。最初の1回さえ通れば難しくありません。どうしてもコマンドが苦手なら、画面操作のLM Studioという選択肢もあります。
A. モデルを取得(ダウンロード)するにはインターネット接続が必要です。ただし、取得した後の実行やチャットは、基本的にPC内で完結できます。
A. Gemma 4 12Bは8GBだと厳しめです。より小さいモデルや、強めに量子化された軽量版なら動く可能性があります。快適さを求めるなら16GB前後が目安です。
A. 用途しだいです。手軽さや最大級の賢さは、クラウドのChatGPTが有利。プライバシーやオフライン、料金を抑えた実験は、ローカルのOllama+Gemmaが向きます。置き換えというより、使い分けがおすすめです。
※本記事は、公開情報(2026年6月時点)をもとに初心者向けに整理しています。コマンド・対応状況は今後変わる場合があります。参考にした主な情報:Ollama(gemma4)/Gemma 4 モデルカード/Google公式ブログ。最新情報は各公式でご確認ください。






