【Python】PyTorchで学ぶ:ニューラルネットワーク構築入門
momeq
muchi-no-chi

自動微分と計算グラフって聞いたことあるけど、それがディープラーニングでどう使われるのかにゃ?

自動微分と計算グラフは、ニューラルネットワークをトレーニングする際に不可欠なんだ。自動微分を使えば、複雑な勾配計算を簡単に行えるし、計算グラフはそれらの計算の流れを視覚的に表現するのに役立つよ。
なるほど、でもそれがどういう意味なのかまだよくわからないんだにゃ。難しいにゃ。
実際、これらの概念は最初は少し難しく感じるかもしれないね。でも、一緒に基本から学んでいけば、すぐに理解できるようになるよ。自動微分によって、モデルのトレーニングがどれだけ効率化されるか、そして計算グラフがどのように役立つかを見ていこう。
自動微分は、ディープラーニングにおける最も重要な概念の一つです。この技術は、複雑な数学的関数の微分を自動的に計算し、ディープラーニングモデルの効果的なトレーニングを可能にします。
自動微分は、数値計算の分野において、関数の導関数(勾配)を計算機プログラムによって自動的に評価する技術です。具体的には、計算プロセスを基本的な操作に分解し、それぞれの操作に対する微分を連鎖法則に基づいて組み合わせることで、関数全体の導関数を効率的に計算します。
ディープラーニングモデルは、多くの調整が必要なパラメータを持っています。これらのパラメータを適切に設定するためには、モデルがどれだけ良くないかを示す「損失関数」というものの勾配(方向と大きさ)を計算する必要があります。自動微分は、この勾配計算を迅速かつ正確に行うための技術です。これにより、モデルのトレーニング(学習過程)が大幅に効率化されます。
簡単に言うと、ディープラーニングモデルを効果的に学習させるためには、モデルがどのように改善されるべきかを正確に把握することが重要です。自動微分は、この「改善の方向」を高速かつ正確に計算する手法であり、これにより学習過程がスムーズかつ迅速に進むのです。
従来の手動微分は、特に複雑な関数に対しては時間がかかり、エラーが生じやすいプロセスでした。自動微分はこれを自動化し、以下の点で大きな利点を提供します:
ディープラーニングにおいて、計算グラフはモデルの動作を理解し、最適化する上で重要なツールです。
計算グラフは、計算プロセスを視覚的に表現したものです。グラフにおけるノード(節点)は、数学的な操作や変数を表し、エッジ(枝)はノード間のデータの流れを表します。このグラフを使用することで、複雑な計算プロセスをステップバイステップで追跡し、各操作の影響を明確に理解することができます。
計算グラフでは、入力データ、パラメータ、中間計算結果がノードとして表現されます。例えば、加算や乗算のような演算はノードとして表され、これらのノード間のデータの流れはエッジによって表されます。このようにして、モデル全体の動作がグラフとして視覚化されます。
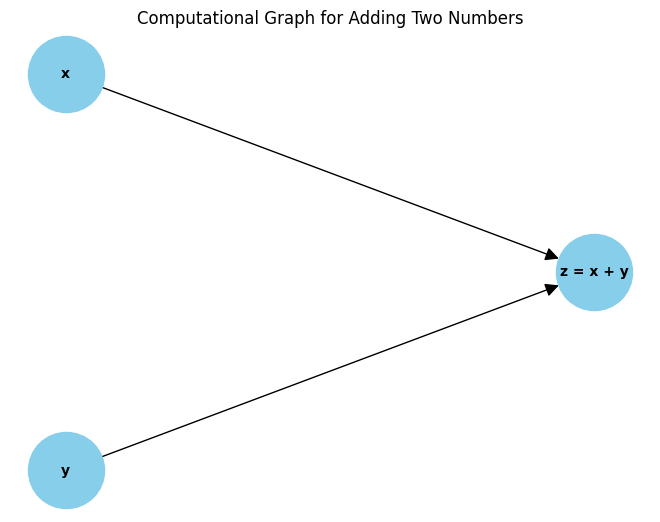
簡単な例として、2つの数値の加算を計算グラフで表現してみましょう:
x と y)を作成します。z = x + y)を作成します。この単純なグラフは、データがどのように操作を通じて流れるかを示しており、より複雑なネットワークの動作も同様の方法で表現することができます。
ディープラーニングモデルのトレーニングにおいて、逆伝播と勾配降下は核心的なプロセスです。このセクションでは、逆伝播のメカニズムと、勾配降下法の役割について掘り下げます。
逆伝播は、ニューラルネットワークをトレーニングする際の主要な手法です。このプロセスでは、ネットワークを通じて誤差(損失関数の出力)の勾配を逆方向に伝播させ、各層の重みを調整します。計算グラフは、この勾配がネットワークの各部分にどのように影響を与えるかを視覚化するのに役立ちます。
具体的には、ネットワークの出力から始めて、連鎖法則を使用して、各層の重みに関する誤差の勾配を計算します。この勾配は、ネットワークをより効果的に学習させるために重みの更新に使用されます。
勾配降下法は、ニューラルネットワークの重みを最適化するための一般的なアルゴリズムです。この手法では、損失関数の勾配に基づいて、重みを段階的に調整していきます。勾配降下法にはいくつかの変種があります:
これらの変種は、計算資源の制約、データの特性、モデルの複雑さに応じて選択されます。勾配降下法は、効率的に最適な重みを見つけるために、逆伝播と密接に連携します。
PyTorchは、その強力な自動微分機能で広く知られています。このセクションでは、PyTorchのautogradライブラリを使用した自動微分の実装について説明し、基本的な使用方法を示すコード例を提供します。
PyTorchのautogradライブラリは、ニューラルネットワークのトレーニング中に発生する微分計算を自動化するためのものです。このライブラリは、テンソルのすべての操作を追跡し、逆伝播時に必要な勾配を計算します。
PyTorchでは、テンソルに対するすべての操作が自動的に計算グラフに記録されます。以下は、autogradを使用して簡単な勾配計算を行う例です:
import torch
# requires_grad=Trueを設定してテンソルを作成
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# テンソルに対する操作
y = x * 2
z = y.mean()
# 逆伝播
z.backward()
# xに対する勾配を表示
print(x.grad)この例では、テンソルxに対する操作を行い、その平均を取るという単純な計算を行っています。z.backward()を呼び出すことで、xに関するzの勾配が計算されます。
autogradライブラリの使用により、複雑なニューラルネットワークの勾配計算を手動で行う必要がなくなります。これにより、モデルの開発と実験が容易になり、より迅速なイテレーションと革新が可能になります。
理論から実践へと進み、自動微分と計算グラフを用いた具体的なディープラーニングプロジェクトの例を見てみましょう。ここでは、PyTorchを使用して簡単なニューラルネットワークを構築し、そのトレーニングと評価のプロセスを説明します。
PyTorchでは、torch.nn.Moduleを継承してカスタムネットワーククラスを作成することが一般的です。例えば、単純な全結合層(線形層)を持つネットワークは以下のように定義できます:
import torch.nn as nn
import torch.nn.functional as F
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 5) # 入力層から隠れ層へ
self.fc2 = nn.Linear(5, 2) # 隠れ層から出力層へ
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return xモデルをトレーニングする際には、損失関数と最適化アルゴリズムを定義します。そして、トレーニングデータに対して繰り返しモデルを実行し、backward()メソッドを使用して勾配を計算し、最適化アルゴリズムで重みを更新します。
import torch.optim as optim
model = SimpleNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# トレーニングデータのロードと処理
# for data, target in train_loader:
# optimizer.zero_grad()
# output = model(data)
# loss = criterion(output, target)
# loss.backward()
# optimizer.step()モデルの性能を評価するには、別のデータセット(通常は検証セット)を使用して、モデルの予測精度を測定します。モデルが過学習していないかを確認するために、トレーニングセットと検証セットでの性能を比較します。
このブログを通じて、自動微分と計算グラフの基本的な概念を理解し、それらがディープラーニングモデルのトレーニングにどのように活用されるかを見てきました。ここで、主要なポイントをまとめ、今後の学習への道筋を示します。
autogradライブラリは、勾配計算を自動化し、開発者がより複雑なモデルに集中できるように支援します。




