
線形回帰分析とは?やり方から活用法まで徹底解説
momeq
AI Master
**「線形回帰分析って難しそう…」**と思っていませんか?
実は、お馴染みのExcelを使えば、プログラミングの知識がなくても本格的な統計分析ができるんです。今回は、住宅価格データを使って、面積や部屋数などの条件が価格にどう影響するかを分析してみましょう。
線形回帰分析とは、「AがBに与える影響の大きさ」を数値で表す統計手法です。
例えば:
こういった関係性を、データから客観的に読み取ることができます。

線形って、直線のことだよね?でも不動産価格って曲線的に変化しそうだけど…

確かに現実は複雑だけど、線形回帰でも十分実用的な結果が得られることが多いんだ。まずは線形から始めて、必要に応じて曲線回帰も試してみよう。
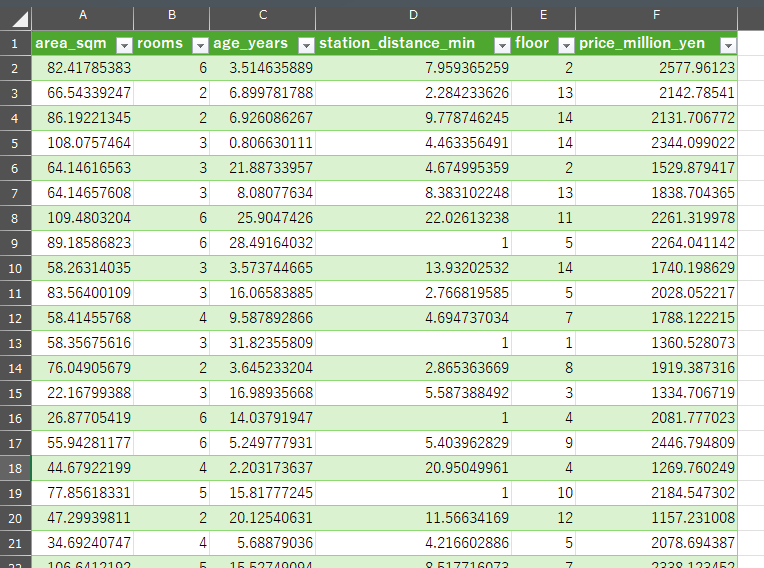
今回使用するのは、架空の住宅価格データです。以下の項目が含まれています:
| 列名 | 説明 |
|---|---|
area_sqm | 専有面積(㎡) |
rooms | 部屋数 |
age_years | 築年数 |
station_distance_min | 最寄り駅からの距離(分) |
floor | 階数 |
price_million_yen | 価格(万円)← 目的変数Y、これを予測したい |
今回使用するデータです。csvファイルですので、良かったらこちらを利用してみてください。
どんな感じのデータか教えて。
次がデータの詳細だよ、最小、最大、平均、中央値を列挙してあるよ。例えば部屋数であれば、最小で1部屋、最大で6部屋、平均で3.54部屋、中央値は3部屋って感じかな。
| 変数名 | 最小値 | 最大値 | 平均 | 中央値 |
|---|---|---|---|---|
| area_sqm | 20.658006 | 149.085423 | 84.813023 | 86.711287 |
| rooms | 1.000000 | 6.000000 | 3.534000 | 3.000000 |
| age_years | 0.011876 | 49.967675 | 25.937612 | 26.498170 |
| station_distance_min | 1.009643 | 29.868934 | 15.197620 | 15.179237 |
| floor | 1.000000 | 14.000000 | 7.462000 | 7.000000 |
| price_million_yen | 506.648657 | 2989.904066 | 1749.926 | 1733.422 |
まずは、ExcelにCSVデータを読み込みましょう。そのままCSVを開いてもいいけど、文字化けすることあるので、今回はExcelのデータから開きます。
まずは、PC内でインストールされているExcelを開いてください。
リボンのデータタブ内にある「テキストまたはCSVから」を選択して、対象のファイルを選んで「インポート」を押してください。
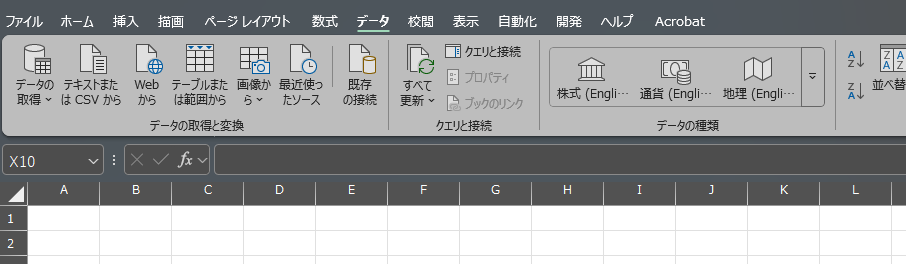
今回はそのまま読み込めそうなので読み込みを押して、データを読み込めば反映されます。
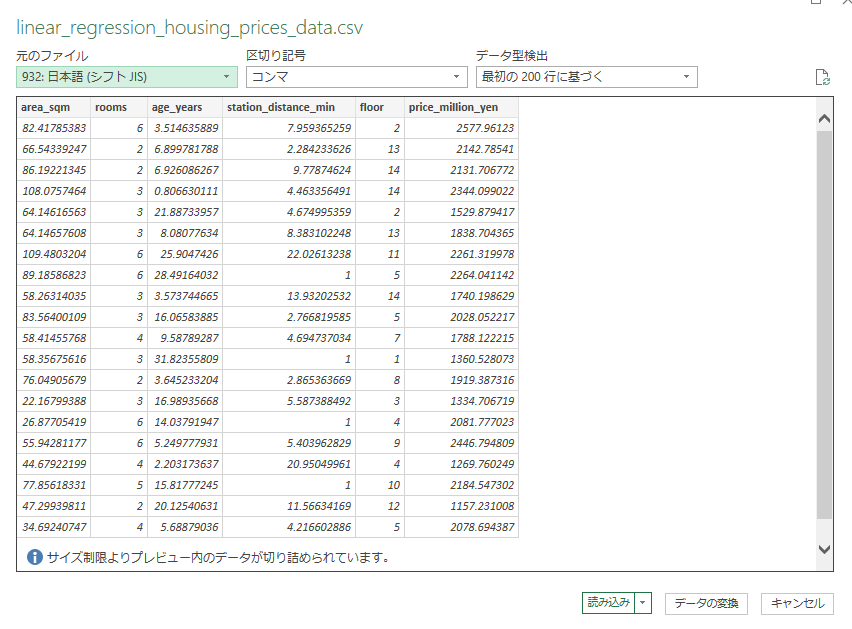
※バージョンによって使えなかったり、方法が違う場合があります。
※また、1行目に項目名(ヘッダー)があることを確認してください。
Excelの「分析ツール」は初期状態では無効になっています。以下の手順で有効化しましょう。
開いた状態で左上にある「ファイル」押します。すると画面が変わり、保存とか印刷とかが左に出てきます。一番下に「オプション」があるので、こちらをクリックしてください。

オプション内には数式やデータ等色々ありますが、下のほうに「アドイン」があります。アドイン内の下部にある「管理」欄を「Excelアドイン」にして「設定(G)…」をクリックしてください。
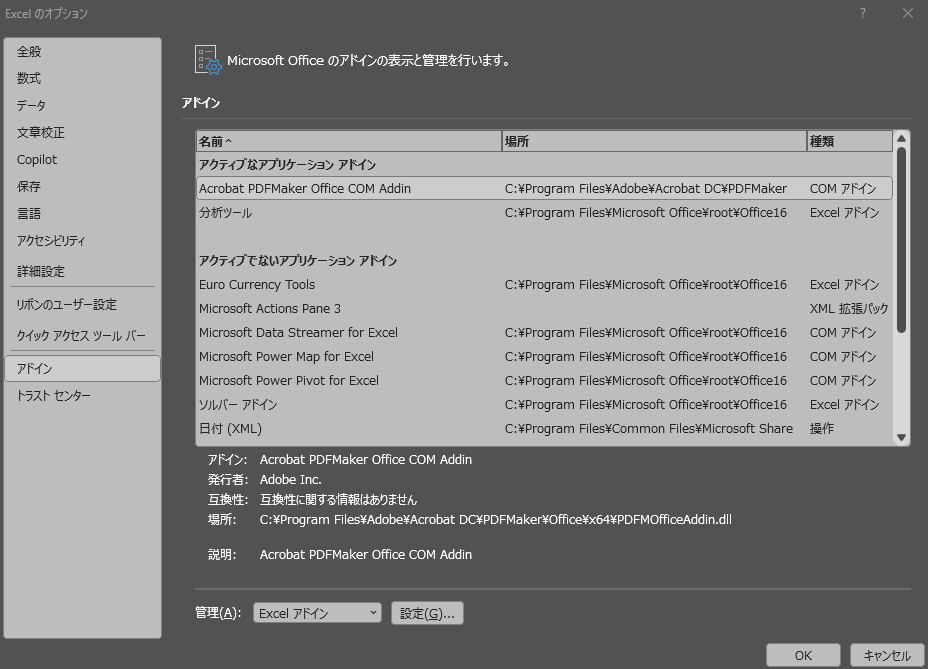
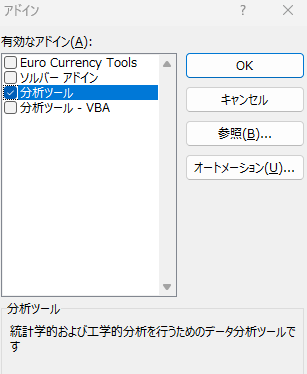
設定内では有効なアドインを選択できると思います。ここで、「分析ツール」を選んでチェックを入れてください。「OK」をクリックすると選択が反映されます。
トップ画面に戻り、データタブ内の右側に分析:データ分析のタブが反映されていれば設定完了です。
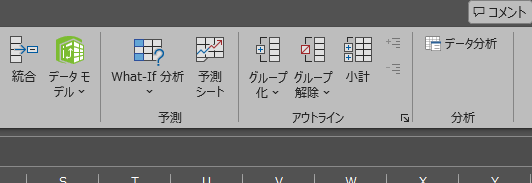
すると、「データ」タブに「データ分析」ボタンが追加されます。
Office 365やExcel for Macでは分析ツールの場所が違うことがあります。バージョンによっては『分析ツール – VBA』も一緒にチェックしてください。
いよいよ分析開始です!
回帰分析を選択状態にして「OK」をクリックします。
すると、回帰分析用の入力欄として次のような画面が出てきます。
ここでは大きく分けて4つ、さらに詳細な入力欄に分かれています。
$F$1:$F$501(目的変数:価格)$A$1:$E$501(説明変数:面積、部屋数、築年数、駅距離、階数)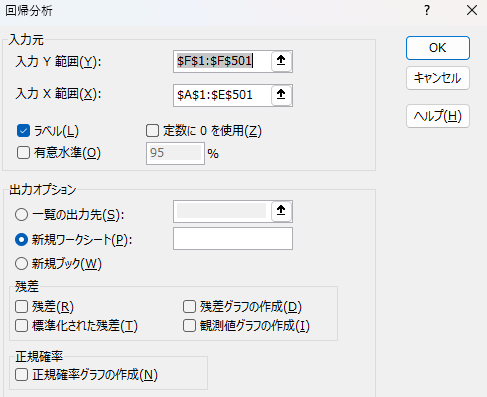
基本的にはチェック不要ですが、知っておくと便利なオプション:
分析が完了すると、新しいシートに結果が表示されます。重要なポイントを見ていきましょう。
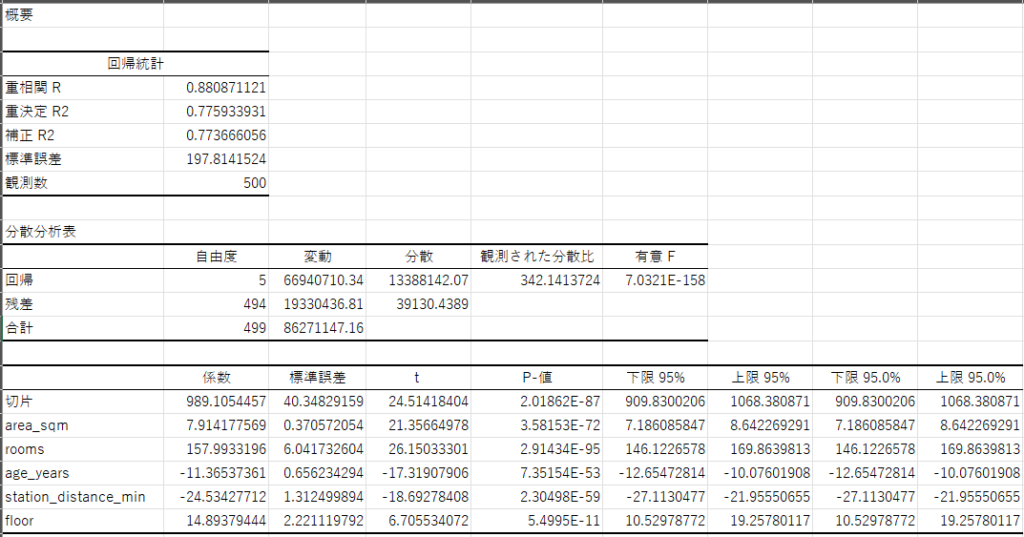
■ 回帰統計
| 指標 | 値 |
|---|---|
| 重相関 R | 0.8809 |
| 重決定 R² | 0.7759 |
| 補正 R² | 0.7737 |
| 標準誤差 | 197.81 |
| 観測数(n) | 500 |
■ 分散分析(ANOVA)
| 分類 | 自由度 | 変動 | 分散 | F値 | 有意確率(P値) |
|---|---|---|---|---|---|
| 回帰 | 5 | 66,940,710.34 | 13,388,142.07 | 342.14 | 7.03 × 10⁻¹⁵⁸ |
| 残差 | 494 | 19,330,436.81 | 39,130.44 | ||
| 合計 | 499 | 86,271,147.16 |
■ 回帰係数と統計量
| 説明変数 | 係数 | 標準誤差 | t値 | P値 | 95%信頼区間(下限) | 95%信頼区間(上限) |
|---|---|---|---|---|---|---|
| 切片(定数) | 989.11 | 40.35 | 24.51 | 2.02 × 10⁻⁸⁷ | 909.83 | 1068.38 |
| area_sqm(面積) | 7.91 | 0.37 | 21.36 | 3.58 × 10⁻⁷² | 7.19 | 8.64 |
| rooms(部屋数) | 157.99 | 6.04 | 26.15 | 2.91 × 10⁻⁹⁵ | 146.12 | 169.86 |
| age_years(築年数) | -11.37 | 0.66 | -17.32 | 7.35 × 10⁻⁵³ | -12.65 | -10.08 |
| station_distance_min(駅距離) | -24.53 | 1.31 | -18.69 | 2.30 × 10⁻⁵⁹ | -27.11 | -21.96 |
| floor(階数) | 14.89 | 2.22 | 6.71 | 5.50 × 10⁻¹¹ | 10.53 | 19.26 |
一番重要な数値たち:
77.6%って、まあまあなのかな?100%じゃなくて意味ないわけじゃないの…
実は77.6%はかなり優秀なんだ!現実のデータで80%を超えることは珍しく、60%でも実用的とされるくらいだからね。100%だと逆に『データを暗記しただけ』のいわゆる過学習を疑うべきだね。
各変数が価格に与える影響:
| 変数 | 係数 | 意味 | P値 |
|---|---|---|---|
| 面積 | +の数値 | 1㎡増えると価格上昇 | < 0.05 |
| 部屋数 | +の数値 | 1部屋増えると価格上昇 | < 0.05 |
| 築年数 | -の数値 | 1年古いと価格下落 | < 0.05 |
| 駅距離 | -の数値 | 駅から1分遠いと価格下落 | < 0.05 |
| 階数 | +の数値 | 1階高いと価格上昇 | < 0.05 |
P値が0.05未満なら、その変数の影響は「統計的に有意」(偶然ではない)と言えます。
P値って何?今回はほとんどゼロに近いぐらいな感じみたいだけど。
P値は『偶然でこの結果が出る確率』を表すんだ。だから小さい方がいい。だいたい、0.05(5%)未満なら『偶然じゃない、本当の関係がある』と判断するし、より、厳密にやりたい時は0.01を使うこともあるよ。
今回の分析結果から分かったこと:
これらは直感的にも納得できる結果ですね!
平均が1700万円だから、200万円でも誤差の範囲なんだね。
今回は前処理とかしていないから外れ値に近いものもあったかもしれない。そのようなイレギュラーを無くすとさらに精度がよくなるよ。
この分析結果を使って:
これで完璧に価格予測できますね!不動産投資で儲けられそう!
ちょっと待ってください!これはあくまで『傾向』を示すもの。立地の詳細、市場の変化、経済情勢など、モデルに含まれない要因もたくさんあります。『参考の一つ』として慎重に活用してくださいね。
Excelの「分析ツール」を使えば、プログラミング不要で本格的な統計分析ができます。
今回学んだポイント:
次のステップ:
統計分析の第一歩として、ぜひExcelの回帰分析を活用してみてください!
この記事が役に立ったら、ぜひ実際のデータで試してみてくださいね。質問があれば、コメント欄でお気軽にどうぞ!